// A bucket for a Go map. type bmap struct { tophash [bucketCnt]uint8 // 这里的bucetCnt是8,是个固定值,每个桶跟8个k-v对. // 先是8个key,后是8个value. // 最后是一个overflow指针指向串联的bucket. }
而hmap表示如下,其实就是一个头信息.
1 2 3 4 5 6 7 8 9 10 11 12 13
// A header for a Go map. type hmap struct { flags uint8 // 一些标志j B uint8 // bucket数量的log_2 hash0 uint32 // hash 种子
// A Section represents a single section in an ELF file. type Section struct { SectionHeader
// Embed ReaderAt for ReadAt method. // Do not embed SectionReader directly // to avoid having Read and Seek. // If a client wants Read and Seek it must use // Open() to avoid fighting over the seek offset // with other clients. io.ReaderAt sr *io.SectionReader }
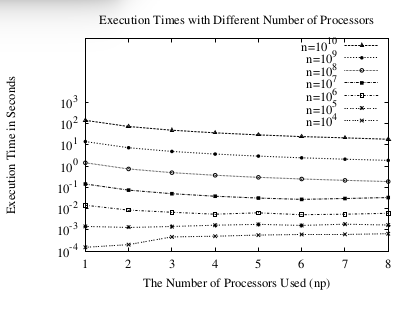
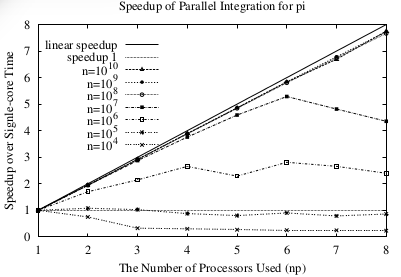
func f(a float64) float64 { return 4.0/(1.0 + a * a) } func chunk(start, end int64, c chan float64) { var sum float64 = 0.0 for i:= start; i < end; i++ { x := h * (float64(i) + 0.5) sum += f(x) } c <- sum * h } func main() { runtime.GOMAXPROCS(np); h = 1.0/float64(n) ..//start timing c := make(chan float64, np) for i:=0; i < np; i++ { go chunk(int64(i)*n/int64(np), (int64(i)+1)*n/int64(np), c) } for i:=0; i < np; i++ { pi += <-c } ...//end timing }
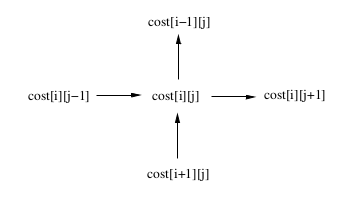
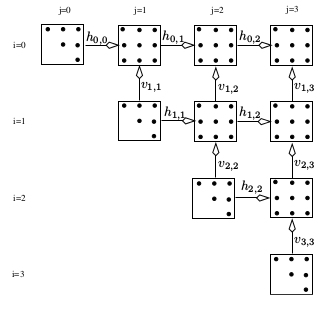
var h,v [vp][vp] chan int var finish chan int ..//declare other variables and constants func creatChan() { for i:=0; i < vp; i++ { for j:=i; j < vp; j++ { if j < vp-1 {h[i][j] = make(chan int, 1)} if i > 0 {v[i][j] = make(chan int, 1)} } } } func mst(i,j int) { ... // the same as in the sequetial code } func chunk(i,j int) { var bb int il := (i * (n+1))/vp //block-low for i ih := ((i+1) * (n+1))/vp - 1 //block-high for i jl := (j * (n+1))/vp //block-low for j jh := ((j+1) * (n+1))/vp - 1 //block-high for j if i < j { // not a tile on the diagonal <-h[i][j-1] // receive from the left <-v[i+1][j] // receive from below } for ii:=ih; ii >= il; ii-- { if i==j { bb = ii } else { bb = jl } for jj:=bb; jj <= jh; jj++ { mst(ii,jj) } } if j < vp-1 {// not a tile on the right border h[i][j] <- 1 } if i > 0 { // not a tile on the top border v[i][j] <- 1 } if i==0 && j==vp-1 {//the last tile finish <- 1 } } func main() { ...//read flags runtime.GOMAXPROCS(np) ... //start timing creatChan() finish = make(chan int, 1) for d:=0; d < vp; d++ {//sub-diagonal of j=i+d for i:=0; i+d<vp; i++ { go chunk(i, i+d) } } <-finish ....//end timing }
[1] Shameen Akhter and Jason Roberts. Mutli-Core Programming: Increasing Performance through Software Multi-threading. Intel Press, 2006.
[2] Edward A. Lee. The problem with threads. IEEE Computer, 39(5):33–42, May 2006.
[3] Go Team.The Go programming language specification.Technical Report http://golang.org/doc/doc/go spec.html,Google Inc., 2009.
[4] C.A.R. Hoare. Communication Sequential Processes.Prentice Hall, 1985.
[5] Michael J. Quinn. Parallel Programming in C with MPI and OpenMP. McGraw-Hill, 2004.
[6] Thomas H. Corman, Charles E. Leiserson, Ronald L.Rivest, and Clifford Stein. Introductions to Algorithms,2nd Edition. McGraw-Hill Book Company, 2001.
[7] Sara Baase and Allen Van Gelder. Computer Algorithms: Introduction to Design and Analysis (3rd Ed).Addison-Wesley, 2000.