Go语言并行测试(论文翻译)
- Peiyi Tang
- 计算机科学部
- 阿肯色州大学小石城分校
##概要
Go语言是一门新的并发编程语言.它的目标之一就是应对多核并行编程的挑战.在这篇论文里面,我们展示了两个多核并行的Go程序和他们在八核微处理器上的性能和并行Go代码的效率.
1 介绍
直到2000年,计算机架构都可以把并发运算封装在硬件中,每18个月微处理器的性能就可以翻倍,而不需要丝毫地改动串行编程模型(sequential programming model).但有三个问题日益凸显,处理器和内存的速度在跨越式增长,指令级别的并发存在限制,高性能的计算能力也被提高,综合这三个原因,在2000年所有的微处理器厂商都转向了多核微处理器的开发.
多核处理器展现了非常好的性能,为了能够充分发挥这样的性能,就需要通过并行编程来解决.运行串行的代码只能够发挥单个处理器的性能,而浪费了其他处理器的资源.
最早和多核并行编程有关的书是_”multi-thread programming”[1],然而在多线程模型上实现并行和并发程序是非常困难的.就像_Edward A.Lee[2]指出的,多线程编程的问题是,这样的方式是一种落后的方式,使得程序在一开始就变得不确定,然后通过使用信号量,锁机制还有监视器来减少不确定性.
最近Google推出了一门新语言Go(这里的最近是指2009年).Go是并发的并且具有垃圾回收的系统编程语言[3],目标之一就是迎合多核编程的挑战使得并发编程更加简便.Go不使用多线程模型,而是通过Go的routine(基于CSP的communication通道).任何Go语言中的函数,能够作为串行编程模型中的普通routine或者用关键字go在前端执行一个Goroutine,在运行时里面一个被调用的Goroutine是和调用者routine并发执行的,而不管他们是否运行在同一个CPU上.从编程这的角度来说,Go routine是并发的归宿,而且对比于之前的锁方式等等,有更加良好的确定性.Go在CSP的communication通道的基础上,扩展了无缓冲区大小的通道来实现异步发送(或写)操作.通道是Go语言的预定义类型(first-class),能够从一个routine传递到另一个routine.Goroutine和CSP通道的结合提供了一个强大的机制来来保证达到一个期望的确定性的并发计算。
在这篇论文中,我们将通过两个例子展示Go语言在并行编程方面体现的多核利用率.第一个例子在第二节中讨论,是没有同步和通道的并行积分问题.第二段程序在第三节中讨论,是一个并发动态规划的问题,需要在多个并发任务中实现同步,第四节总结这篇论文.
2 并行计算积分
计算积分是一个用来展示并发编程和它本身加速度(表示的是多处理器执行时间和单处理器执行时间的比值)的常见例子,例如一个函数\(f(x)\),在\([a,b]\)上的积分.
$$ \int_a^b f(x),dx $$
能够通过\(n\)个在曲线下方的长方形来求和估计计算\(f(x)\),
$$ \sum\limits^{n-1}_{i=0} hf(a+h(i+\frac{1}{2})) $$
因为\(h = \frac{a-b}{n}\)是小长方体的宽度.因为只有有限个\(np\),并且\(np << n\),所以只要创建\( np\)个计算组,每个计算组分配给一个处理器就可以得出结果.为了平衡处理器之间的计算,我们用阻塞公式(blocking formula)[5]来把n个矩形\(0,\cdots,n-1\)平均分配到\( np\)个计算组里.
$$ \lfloor \frac{i*n}{np} \rfloor,\lfloor \frac{i*n}{np} \rfloor + 1,\cdots,\lfloor \frac{(i+1)*n}{np} \rfloor - 1 $$
1 | func f(a float64) float64 { |
代码1:计算Pi的代码.
通过循环触发Goroutine来实现np个子算组的并行运算,代码1显示了被省略的Go代码来计算Pi的积分:
$$ \pi=\int_0^1 \frac{4}{1+x^2},dx $$
计算一个计算组是通过 chunk(start,end int,c chan float64)这个函数实现的,这个函数计算从start到end之间的矩形面积.Channel c则是用来在结束的时候进行同步,并且把计算组的结果送到main routine.
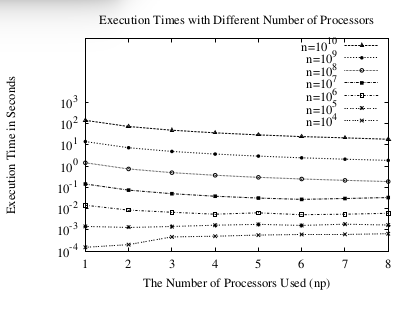
图2:执行时间
主routine 通过建立运行时来开始所有在\(np\)个处理器上的Go routine,通过调用rutime.GOMAXPROCS(np)就可以实现.make语句构造了一个有np大小缓存的通道,第一个循环是通过chunk开始所有的routine,并且把通道传递进去.这些routine和main routine并发执行.
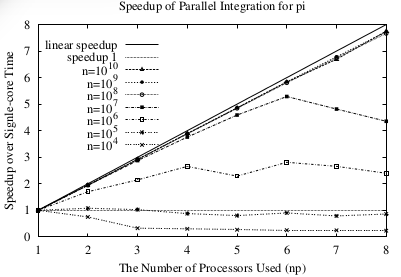
图3:积分的加速度
pi+= <-c会执行np次,累加以获得pi的结果,在第一个chunck()调用的时候,通道为空,从空的通道读取会阻塞main routine.第二个循环在接受了所有routine的
结果之后终止,pi就会得到最终结果.
我们在一个八核AMD Opteron(tm) 2.8GHz 1024KB cache的处理器上.我们把问题的n从\(10^4\)调整到\(10^10\)然后把处理器个数从1提升到8.图2 展示了,并行Go计算pi的效率.对于小的问题规模\( (n = 10^4,10^5) \),使用多核不能增加的执行时间,这是因为过多的调度和初始化routine导致的,大部分时间没有执行并行计算.当问题规模n变大的时候\((n = 10^8,10^9,10^10)\),使用多处理器能够显著的增加执行时间.
为了能够体现并发执行的加速度(speedup),我们可以通过下面的式子计算速度:
$$ S_{np} = \frac{T_1}{T_{np}} $$
在这里 \(T_1\)和\(T_{np}\) 是1个处理器和np个处理器.他们对应的结果在图3中.注意,当问题规模非常大的时候,增长几乎就是线性的了,特别是问题规模达到\(n=10^9\)的时候,几乎能达到7.79,这个时候处理器的个数是8个.
3 并发的动态规划
现在我们转向第二个多核并发的例子,这个例子是一个动态规划问题.动态规划旨在存在最优子结构的问题的解决,并且动态规划还要解决重叠问题[6],只计算一次子问题,然后把结果存在备忘录中,也就是一个用来查询结果的表结构.这种方式很多时候能把时间复杂度从指数级降低到多项式的级别.我们使用优化二分搜索树问题来展示动态规划的多核并行方式.
给出n个key,\(k_1,\cdots,k_n\)和他们的概率分布\(p_1,\cdots,p_n\),优化二分树搜索问题是找到二分搜索树(BST)的key的最小平均时间.
设\(BST_{i,j}\)为优化BST,存储了key,\(k_1,\cdots,k_n(j>=i-1)\),并且\(MST_{i,j}\)代表最小搜索时间(mean search time,MST),\(BST_{i,i}\)是一个只有root \(k_i(1 <= i <= n)\) 的单一节点,它的最小搜索时间是\(MST_{i,i}\),也就是\(p_i\).另外\(BST_{i,i-1}\)是一颗空树\((1 <= i <= n)\),并且它的最小搜索时间是\(MST_{i,i-1}=0\)
1 | var ( |
代码4: 动态规划算法
如果优化二叉搜索树\(k_1,\cdots,k_n \),把\( k_r ( 1 <= r <= n) \)作为根节点,那么左子树\(k_1,\cdots,k_{r-1}\)和右子树\(k_{r+1},\cdots,k_n\)必须也是最优化的(这个用反证法可以证明).因此,\(MST_{i,j}\)能够递归定义成
$$ MST_{i,h} = \min_{i<=r<==j} (MST_{i,r-1} + MST_{r+1,h}) + \sum_{k=i}^jp_k $$
这个公式能够决定MST的最小子树的r对应的这棵树的根节点.
存储MST的结构是矩阵(n+1)X(n+1)的上三角部分,这个矩阵对应的是最小搜索时间MST的cost[n+1][n+1].特别地 MSTi,j 存储在cost[i-1][j].相似地,\(k_i,\cdots,k_j\)优化二叉搜索树的根节点存储在root[i-1][j],root是另外一个root[n+1][n+1]矩阵.时间的概率的分布存储在数组prob[n]中,\(p_i\)对应prob[i-1].
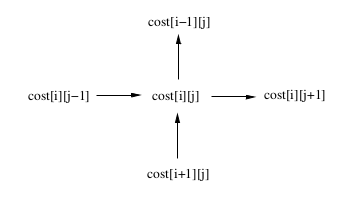
图5:任务间的数据依赖.
寻找最优二叉搜索树的串行动态规划算法[7]的代码在 代码4 中展示.总得来说,这个算法计算cost[i][j](0 <= i <= j <= n)时是需要递归使用cost[i][i],cost[i][i+1],…,cost[i][j-1]和cost[i+1][j],cost[i+2][j],…,cost[j][j]的值的.cost[i][j]的计算依赖于cost[i][j-1],cost[i+1][j]的依赖.
图5展示了用来计算cost[i][j]的数据结构.这是因为串行算法里面的嵌套循环从按照从下到上以及从左到右来计算cost[i][j]的,当并行化这个算法的时候,我们必须借助这个数据依赖.
原则上,我们可以构造(n+1)*(n+1)/2大小的矩阵,一个来记录cost,但是这个并行任务的粒度太小了,会使得调度和同步的代价过高,而挤占了并行计算的资源.为了能够控制并行计算的粒度,我们把任务空间切分成 vp(vp+1)/2 个块,并且把每个快分配给一个Goroutine作为一个运算单元.
在每个任务块内,Goroutine以自顶向下或者由下而上的顺序计算二维数组cost,root的一部分.为了能够实现数据块间的数据依赖,要使用channels进行同步.
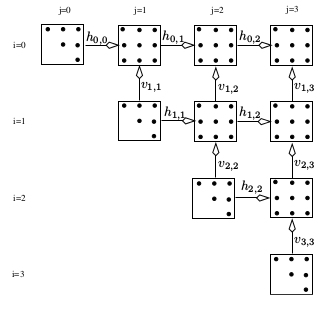
图6展示了10个数据块,vp=4,数据规模n=11的一个用Gochannel同步的结果.每个点代表了数组cost的一个元素的计算称作point.任务块之间的箭头时Gochannel的同步.特别地,一个数据块左数据块和下数据块计算完毕才能够开始计算.每个任务块都有一个下标\((i,j)(0<=i<=j<=vp-1)\).Channels能够通过发送给通道的任务块来识别.特别的,title(i,j)通过水平线上的channel \(h_{i,j}\)把信号传送给右边的title(i,j+1)(如果不是在最上面),或者通过水平的通道把信号发送到上面的title(i-1,j).在对角线上的title(i,j)(i==j)能够开始计算,因为他们没有依赖于任何其他的任务块的计算.最右上角的(vp-1,vp-1)时最后一个计算的.为了能够发送结束的信号,有另外一个finish通道用来告知main routine计算的结束.
1 | var h,v [vp][vp] chan int |
代码7 Go语言并行动态规划
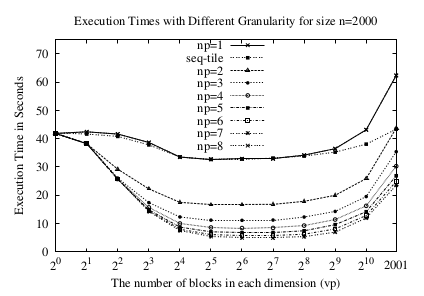
图8 规模2000的执行时间
我们选择设定问题规模为2000来进行实验,来保证足够大的精确测量.我们需要在八核AMD Opteron(tm)微处理器运行图7中的并行代码,改变每个维度的block的数量,从1,2,4,8,…,1024和2001.当vp越大的时候,粒度越小.vp=1对应了粒度最大的情况,没有并行,只有一个数据块.这种情况只有一个Goroutine调用,一个channel finish.
执行时间几乎就像串行结果一样的,不管多少处理器被利用.vp=2001的时候对应粒度最小的最大任务块,每个点都有一个.
图8展示了不同的vp和不同处理器np的情况下并行执行时间.对于每种vp和np的组合,我们运行5次,用单用户模式,计算平均值并放入图8中.
注意np=1的时候执行时间.我们能够观察到执行时间会递减,当vp从1增加到32,这是因为vp的增加创造了更多的任务块并且增加了缓存的命中率.
当vp从32增加到2001的时候,执行时间却反而增加了,这是因为缓存命中率降低并且过多的创建和调度Goroutine的结果导致的.
我们运行另一个去除所有的channel和routine调用的串行但是分块的代码(这段代码没有展示),它的执行时间近似于图8 ¨seq-tile¨ 的曲线,这个时间真正的体现了没有goroutine的时候的缓存命中率的效果.因此¨seq-tile¨和¨np=1¨之间的距离就是Go调度和调用的代价.
对于vp=2001,右2,003,001 个Goroutine的调用,¨np=1¨和¨seq-title¨时62.318429-43.351857=18.966572秒.因此,创建和调度Goroutin的代价对于每个处理器来说平均时\( \frac{18.966572}{2003001} = 9.46*10^{-6}\)秒,也就时9.46us.
np>1时的多核并行执行时间是小于np=1时的运行时间.但是np=1时,有goroutine的调用和调度的开销,这在串行执行的时候并不是完全需要的.我们用分块的串行时间¨seq-time¨作为基础来计算并行计算加速度.特别的,np>=1的处理器
$$ S_{np}=\frac{T_{ts}}{T_{np}} $$
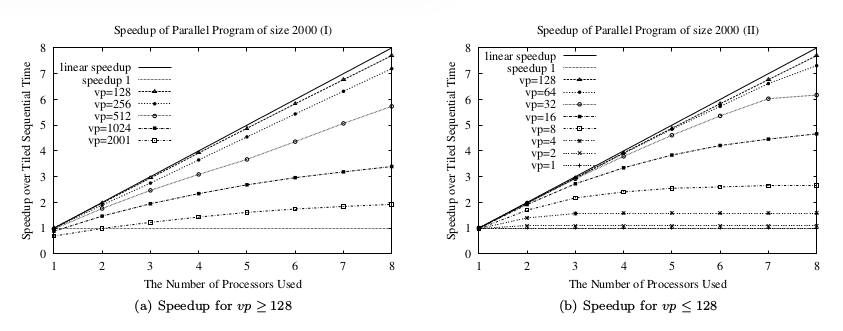
\(T_{ts}\)和\(T_{np}\)分别对应串行时间和使用np处理器的并行时间.图9 显示了不同任务块大小的并行运行时间和串行时间的比较.最好的加速度vp=128的时候.对于8个处理器的时候,加速度是7.70.当vp从128增加的时候,粒度减小而Goroutine调度和调用拖累了执行过程,降低了加速度.图9(a)当vp从128降低的时候,粒度增加而且没有足够的任务块,因此降低了并发度,也降低了加速度.图9(b)展示了降低了的加速度.
##4 总结
我们展示了Go的两个问题的并行代码,并行积分和并行动态规划问题.这些代码展示了Go在编写多核并行代码的简易性.我们同样测量了代码的性能.最高的加速度分别时7.79和7.70.初始化和调度Goroutine的代价在使用一个处理器的时候只有9.46us.因为并行计算倾向于计算大块的任务,Goroutine的量级如此之小,基本上可以忽略.
引用
- [1] Shameen Akhter and Jason Roberts. Mutli-Core Programming: Increasing Performance through Software Multi-threading. Intel Press, 2006.
- [2] Edward A. Lee. The problem with threads. IEEE Computer, 39(5):33–42, May 2006.
- [3] Go Team.The Go programming language specification.Technical Report http://golang.org/doc/doc/go spec.html,Google Inc., 2009.
- [4] C.A.R. Hoare. Communication Sequential Processes.Prentice Hall, 1985.
- [5] Michael J. Quinn. Parallel Programming in C with MPI and OpenMP. McGraw-Hill, 2004.
- [6] Thomas H. Corman, Charles E. Leiserson, Ronald L.Rivest, and Clifford Stein. Introductions to Algorithms,2nd Edition. McGraw-Hill Book Company, 2001.
- [7] Sara Baase and Allen Van Gelder. Computer Algorithms: Introduction to Design and Analysis (3rd Ed).Addison-Wesley, 2000.