kubernetes 调度器指北
最近因为 k8s 的默认调度器功能太丰富,太“高级”了,一些屌丝特性没有满足,所以前段时间自己魔改了一下满足了一些屌丝特性,暂时叫做乞丐调度器,顺便把默认的调度器代码翻了一下,这里对默认的代码做一下总结。
CreateScheduler
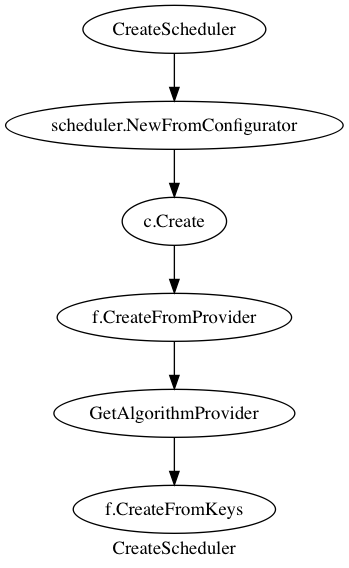
CreateScheduler 会从 policy file 当中获取算法的配置信息。接口k8s.io/kubernetes/plugin/pkg/scheduler.Configurator 定义了构造一个 scheduler 的配置信息。k8s.io/kubernetes/plugin/pkg/scheduler/factor.ConfigFactory 是这个接口的一个实现。c.Create 会把 AlgorithmProvider 配置的 Predicate 和 Priority 的 key 当作参数传给,f.CreateFromKeys 这样主要对应的 key 注册了的话就会有对应的算法绑定到 scheduler 上面。目前有两种 Provider,一种是用默认 predicate 和 默认 priority 的 AlgorithmProvider,另一种是把 LeastRequestedPriority 换成 MostRequestedPriority 的自动伸缩友好的 AlgorithmProvider。
1 | // Registers algorithm providers. By default we use 'DefaultProvider', but user can specify one to be used |
Scheduler Server
options.ScheduleServer 是服务端对应的配置结构,其中有几个成员。
- KubeSchedulerConfiguration 调度器的配置
- Master 表示 API server 的地址
- Kubeconfig k8s 配置文件的路径
func Run(s *options.SchedulerServer) error 会根据 Sechduler Server 来运行。EventBroadcaster 接受事件,并且把事件发送给事件处理者( EventSink watcher, log),startHTTP 主要是是 profiling 接口,心跳检测接口和 prometheus 的 instrumenting 接口。informerFactory,看起来是一个异步同步信息的 cache,平时调度是直接走 cache,更新的时候才会走 API。最后配置了选主的话会从 Etcd 拿到锁,并且拿到 Master 的锁。
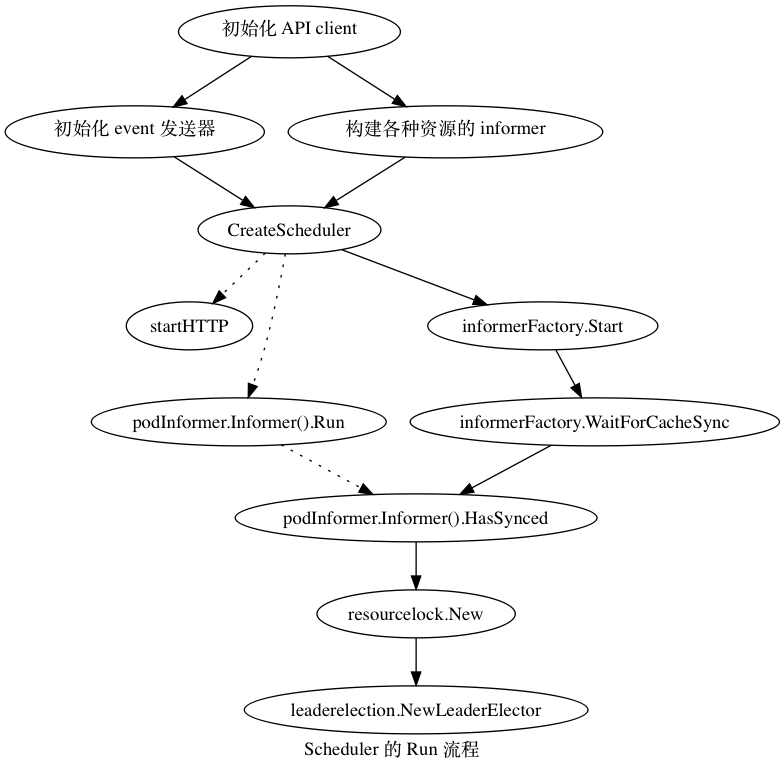
k8s.io/kubernetes/plugin/pkg/scheduler.Scheduler.Run
初始化以后,Run 对应的是一个 0 秒循环的大 loop(相当于每次 loop 等于主动调用一次 Go runtime.Sched()),在每次循环当中都会调用 sched.scheduleOne,首先 NextPod 会同步等待一个 pod 变成 available 的状态,并且跳过正在被删除的 pod,然后调用 sched.schedule 走到具体的调度算法当中,整个过程是串行,没有批量调度 pod 的操作。在进行具体的调度算法之后,会得到一个可行的 node,如果调度失败的话会,并且调度失败的原因是找不到合适的 node 的话,就尝试 sched.preempt,这个的作用就是尝试在替换现有 pod 的情况下能够获得调度机会的策略,那么就抢占已经被调度的 pod,标记目标 pod 的 Annotation 然后踢出权重最低的那个 pod。如果成果获得一个可调度的节点,就通过把本地 cache 先更新到已经调度之后的状态,标记 pod 已经在要调度的 node 上,也就是调用 sched.assume 假设 pod 已经调度到了节点上,再异步的通过 ApiServer 的接口,sched.bind 让 pod 正在运行到 node 上。
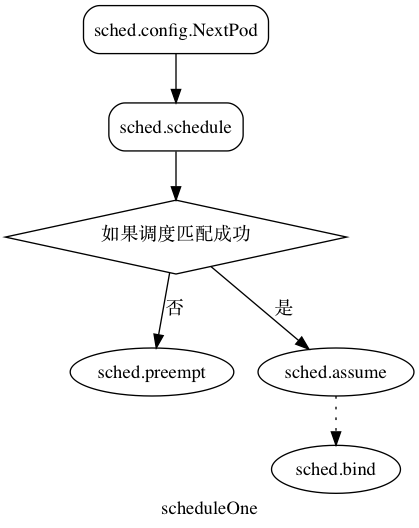
sched.schedule
schedule 调用 algorithm/scheduler_interface.go下面定义的调度器的接口 Schedule。对应的实现在 core/generic_scheduler.go 下面。
1 | // ScheduleAlgorithm is an interface implemented by things that know how to schedule pods |
Schedule 会根据调度算法得到一个合适的节点,而 Preempt 则是尝试抢占一个 pod 以获得调度到节点上的机会。Predicates 和 Priorities 则是两个重要的部分,Predicates 类似一个过滤器,对节点进行筛选,而 Priorities 则是对筛选出来的节点进行权重的排序,最后得到一个合适的调度节点。
算法工厂
算法工厂就是注册 Preciate 和 Priority 的地方,之前已经说了可以通过 AlgorithmProvider 获得一组 Predicate 和 Priority,比如 DefaultProvider 提供了默认的一套,如果不用 Provider,需要在 policy file 当中另外指定要使用的 Predicate 和 Priority,不过目前好像没有用这种方式,还是通过 Provider 指定了一套要使用的算法 。注册 AlgorithmProvider 是通过factory.RegisterAlgorithmProvider,然后调用 NewGenericScheduler (在 k8s.io/kubernetes/plugin/pkg/scheduler/core/generic_scheduler.go 当中),初始化要用到的 predicates 和 priorities。
调度过程
Schedule 其实很简单,就是通过 findNodesThatFit,先根据 Predicate 过滤出合适的 Node,然后调用 PrioritizeNodes,用 Priorities 对 Node 根据算法的权重进行排序,因为每个 node 要走的流程是一样的并且最终结果相互没有影响,所以这个过程是并发的,这篇文章的图画的很好,示意很明显。
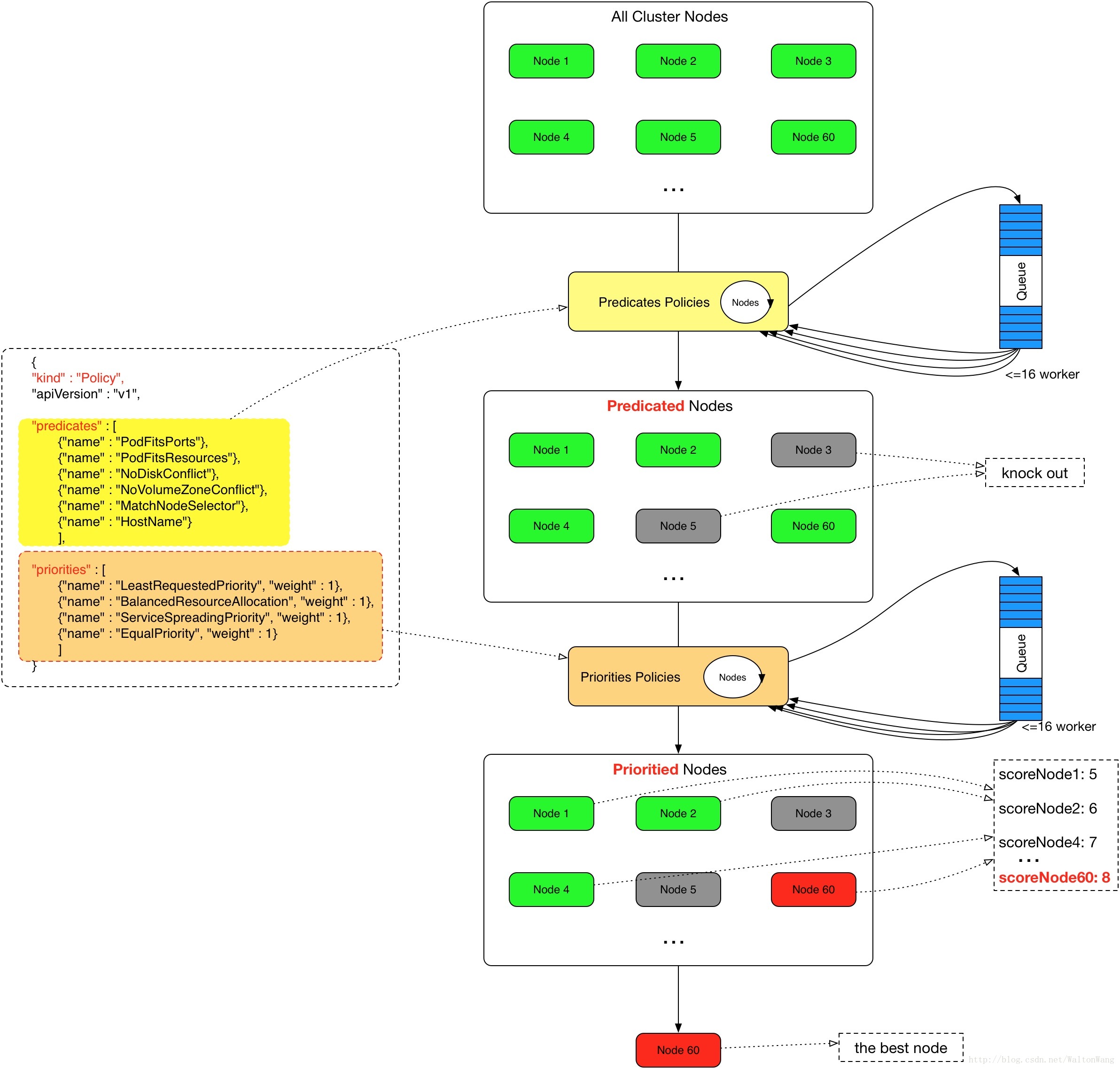
最后会得到一个最理想的节点,再通过 bing 告诉 API server 这个节点被选中了。
sched.preempt
抢占过程是在 pod 没有找到合适的节点情况下,如果能在踢出一个 pod 获得调度机会的情况下进行抢占。抢占算是一个比较新的特性,在 1.8 里面都是默认关掉的,要打开的话需要指定kube-scheduler 的 --feature-gates=PodPriority=true 还有 apiserver 的 --runtime-config=scheduling.k8s.io/v1alpha1=true。可以通过添加 PriorityClass 把 pod 分权重,现在这个特性算是给 pod 也加上的权重。
1 | apiVersion: v1 |
然后可以在spec当中指定 priorityClassName: high-priority,这样这么大的权重,这个 pod 就很难被抢占了,具体流程如下图。
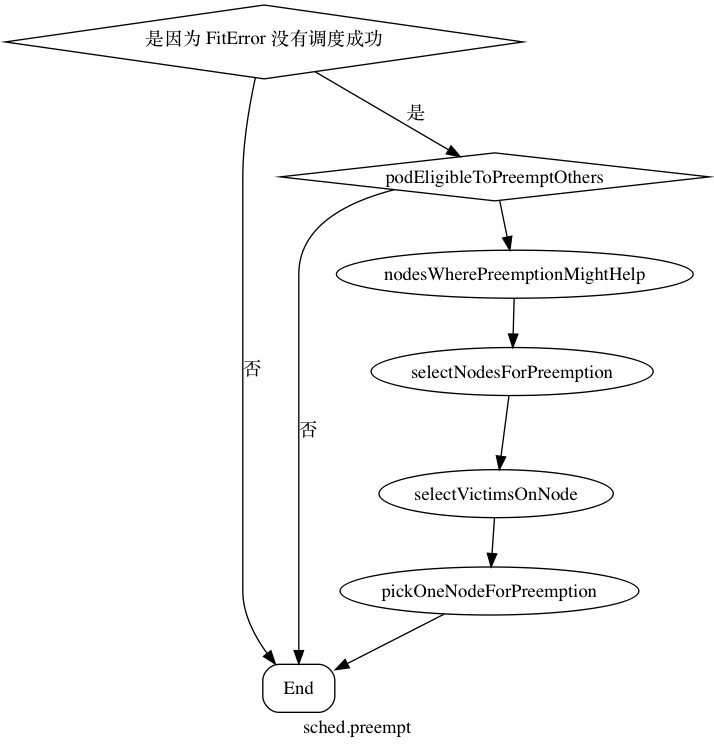
podEligibleToPreemptOthers 主要判断如果 目标 pod 被标记为(通过 pod 的 annotation 标记)已经要抢占其他 pod,并且有一个优先级小于 目标 pod 的 pod 即将被删除 (p.DeletionTimestamp != nil ),就直接退出,因为这个时候这个被删除的 pod 其实在为目标 pod 腾出空间了,在下次调度的时候就会获得调度机会。nodesWherePreemptionMightHelp,类似于 schedule 的时候的 predicate 阶段,只不过多了一步是通过尝试移除 pod 跑一遍 predicates 看看这个节点能不能被通过。 selectNodesForPreemption 则和 priority 的阶段类似,把删除 pod 之后的可以通过的节点进行排序选出一个排名最高的节点。再通过 selectVictimsOnNode 把节点上的 pod 按照节点的 priority 排序选出“受害者”,越高越难被抢占。可以在 spec 里面设置这个值,选出了节点上的受害者以后,通过pickOneNodeForPreemption,主要的依据是拥有最低的最高 pod 权重的节点先被选出来,比如 node1 上 pod 的最高权重是 10,node2 上 pod 的最高权重是 8,那么 node2 被选中,如果有平局的话,最少的“受害者”先选,如果还平局,随机选一个。最后得到一个要被抢占的节点。
自定义调度器的方式
自定义调度器有三种方法。
第一种是通过添加 Predicate 和 Priority 的方式,做微调,这种方式比较简单,只要定义好对应的函数并且通过函数工厂注册就可以。
第二种是使用自定义的调度器,具体的方法可以看官方文档,通过把 pod 的 spec.schedulerName 指向自定义的调度器就可以把调度任务转到自己实现的服务。
第三种是使用 extender,extender 本身和调度器的过程类似,接口是如下定义的,主要是针对一些不算受集群本身控制的资源,需要通过外部调用来进行调度的情况,相关文档在这里。
性能测试
目前单机简单的测试条件下,1s 钟可以调度成功 450 左右的 pod,具体的性能参数还要慢慢挖掘。