$$ F=-\frac{G M m r}{(r^2 + \epsilon^2)^{\frac{3}{2}}} $$
这样累加的时候自己也可以加进去,因为 r 是 0,那一项相当于没算。
$$ F_j= \sum_{i=1}^{n} F_i $$
对于 N body 有很多的稍微近似的算法,多是基于实际的物理场景的,比如大部分天体是属于一个星系的,每个星系之间都非常远,所以可以将一些星系作为整体计算,构建一颗树,树中的某些节点是其所有叶子的质心,这样就可以减少计算量,但是放到 GPU 的场景下一个 O(N^2) 的暴力算法利用 GPU 的并行能力可以非常快的算出来。
import math classVector: def__init__(self, x, y, z): self.x = x self.y = y self.z = z def__add__(self, other): return Vector(self.x + other.x, self.y + other.y, self.z + other.z) def__sub__(self, other): return Vector(self.x - other.x, self.y - other.y, self.z - other.z) def__mul__(self, other): return Vector(self.x * other, self.y * other, self.z * other) def__div__(self, other): return Vector(self.x / other, self.y / other, self.z / other) def__eq__(self, other): ifisinstance(other, Vector): returnself.x == other.x andself.y == other.y andself.z == other.z returnFalse def__ne__(self, other): returnnotself.__eq__(other) def__str__(self): return'({x}, {y}, {z})'.format(x=self.x, y=self.y, z=self.z) defabs(self): return math.sqrt(self.x*self.x + self.y*self.y + self.z*self.z) origin = Vector(0, 0, 0) classNBody: def__init__(self, fileName): withopen(fileName, "r") as fh: lines = fh.readlines() gbt = lines[0].split() self.gc = float(gbt[0]) self.bodies = int(gbt[1]) self.timeSteps = int(gbt[2]) self.masses = [0.0for i inrange(self.bodies)] self.positions = [origin for i inrange(self.bodies)] self.velocities = [origin for i inrange(self.bodies)] self.accelerations = [origin for i inrange(self.bodies)] for i inrange(self.bodies): self.masses[i] = float(lines[i*3 + 1]) self.positions[i] = self.__decompose(lines[i*3 + 2]) self.velocities[i] = self.__decompose(lines[i*3 + 3]) print("Contents of", fileName) for line in lines: print(line.rstrip()) print print("Body : x y z |") print(" vx vy vz") def__decompose(self, line): xyz = line.split() x = float(xyz[0]) y = float(xyz[1]) z = float(xyz[2]) return Vector(x, y, z) def__computeAccelerations(self): for i inrange(self.bodies): self.accelerations[i] = origin for j inrange(self.bodies): if i != j: temp = self.gc * self.masses[j] / math.pow((self.positions[i] - self.positions[j]).abs(), 3) self.accelerations[i] += (self.positions[j] - self.positions[i]) * temp returnNone def__computePositions(self): for i inrange(self.bodies): self.positions[i] += self.velocities[i] + self.accelerations[i] * 0.5 returnNone def__computeVelocities(self): for i inrange(self.bodies): self.velocities[i] += self.accelerations[i] returnNone def__resolveCollisions(self): for i inrange(self.bodies): for j inrange(self.bodies): ifself.positions[i] == self.positions[j]: (self.velocities[i], self.velocities[j]) = (self.velocities[j], self.velocities[i]) returnNone defsimulate(self): self.__computeAccelerations() self.__computePositions() self.__computeVelocities() self.__resolveCollisions() returnNone defprintResults(self): fmt = "Body %d : % 8.6f % 8.6f % 8.6f | % 8.6f % 8.6f % 8.6f" for i inrange(self.bodies): print(fmt % (i+1, self.positions[i].x, self.positions[i].y, self.positions[i].z, self.velocities[i].x, self.velocities[i].y, self.velocities[i].z)) returnNone nb = NBody("nbody.txt") for i inrange(nb.timeSteps): print("\nCycle %d" % (i + 1)) nb.simulate() nb.printResults()
CUDA 并行计算
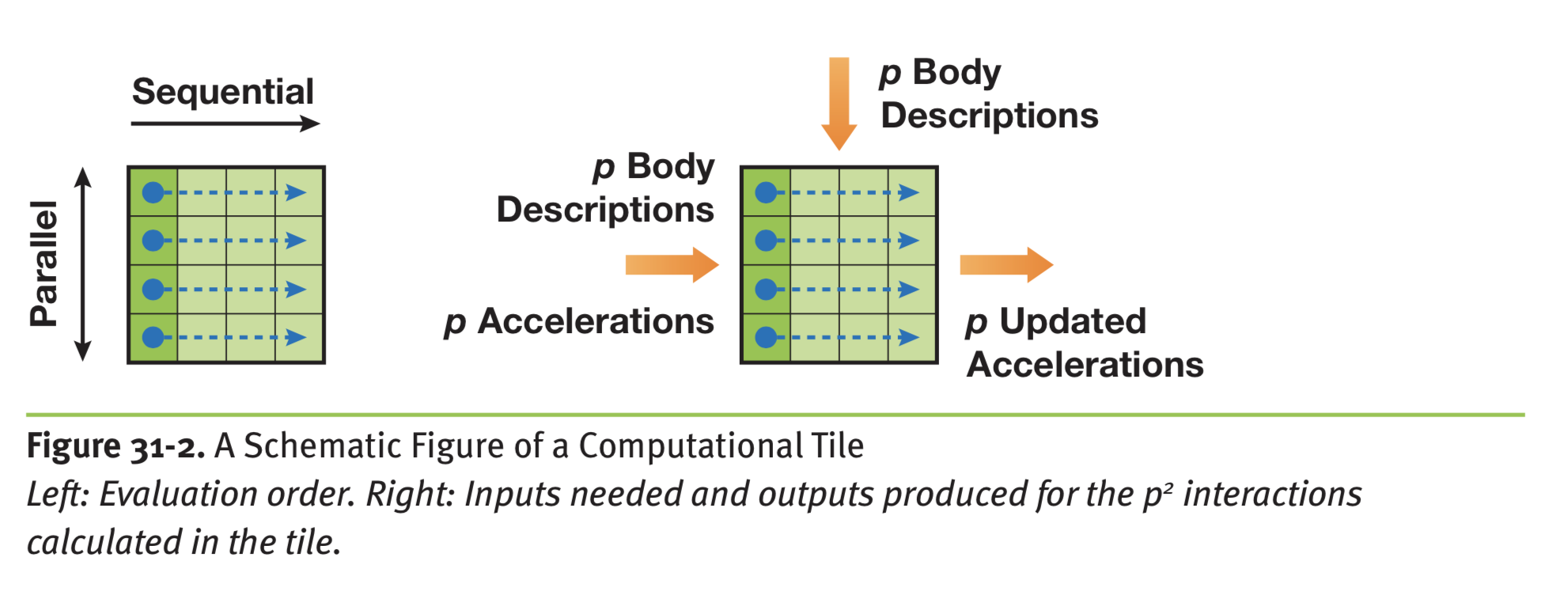
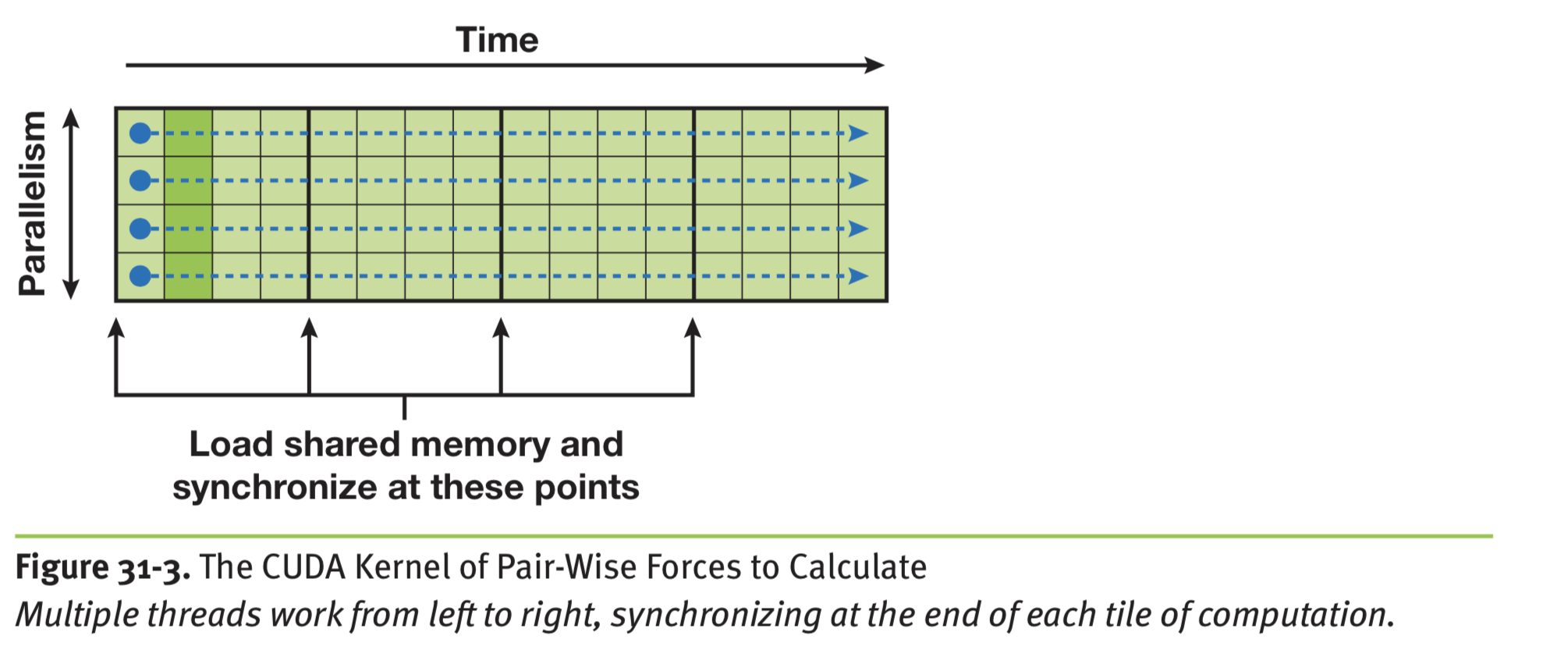
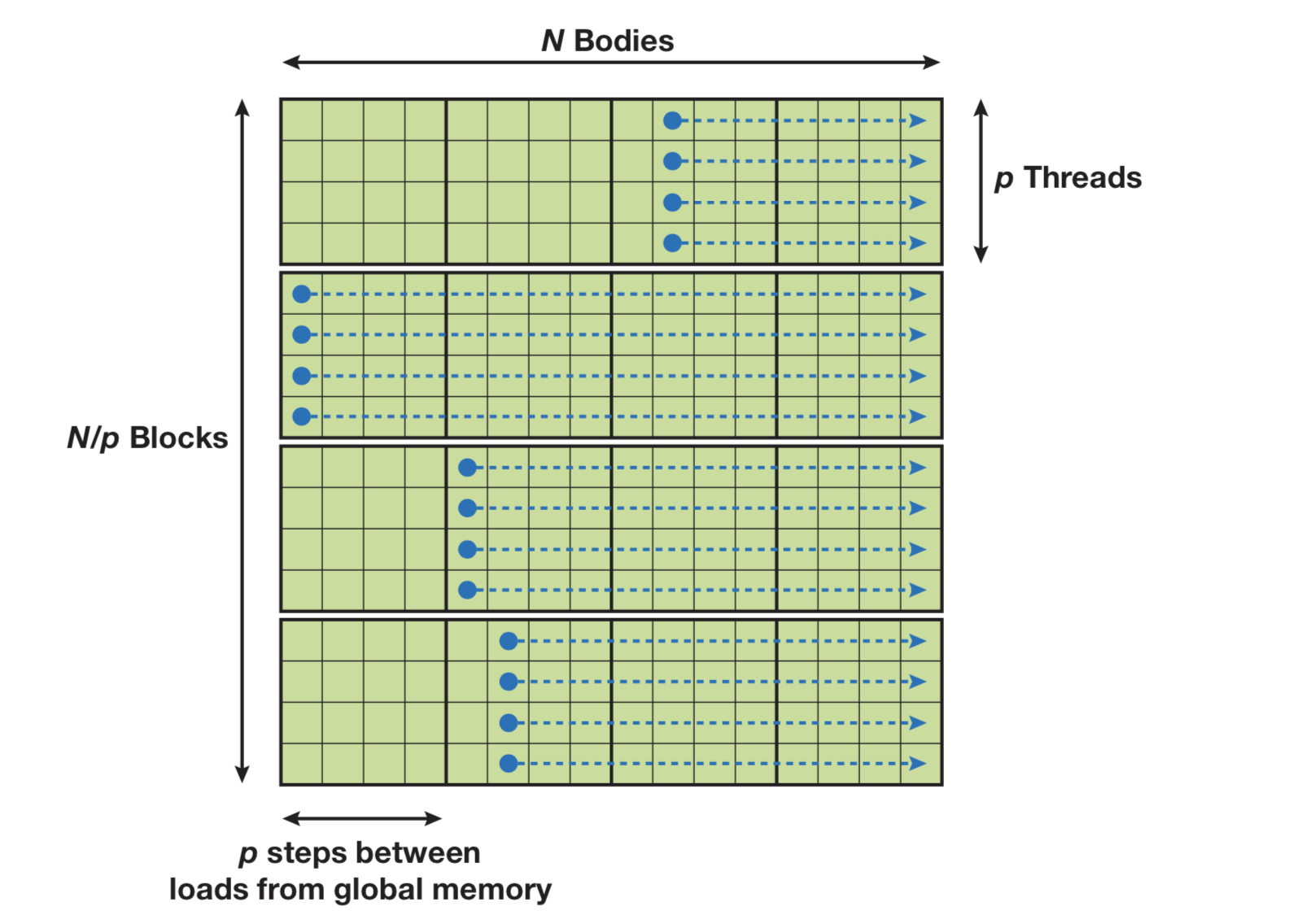
在 CUDA 中并行化首先要理解 CUDA 的层次结构,CUDA 有 grid 和 block 对线程做划分。首先设计一个 computation tile,相当于一个 block 的计算。
左侧表示一个 block 中的 p 个 body 执行 p 次,最后就能更新所有 body 的加速度,这里的内存占用是 O(p) 的不是 O(p^2),浅绿色表示的是串行执行的流,官方的文档没有更新,对应 CUDA 10 的例子里是这样的,vec3 存的是 x/y/z 轴的加速度,vec4 存的是坐标加质量,就是计算 i 受到 j 的加速度,这里没有并行设计是串行的。