总结一下 SysML 2019 的一些论文。
TICTAC
问题背景是解决分布式训练的 scale 问题。
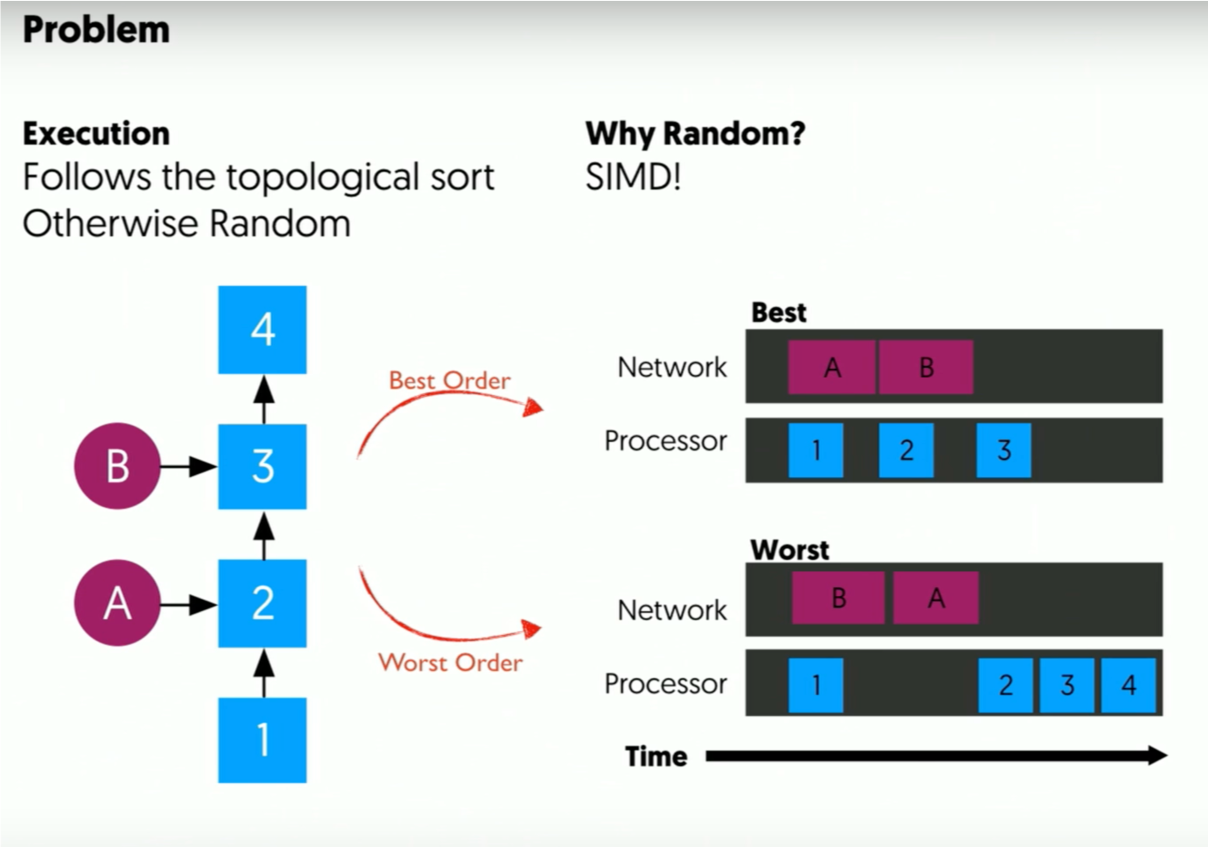
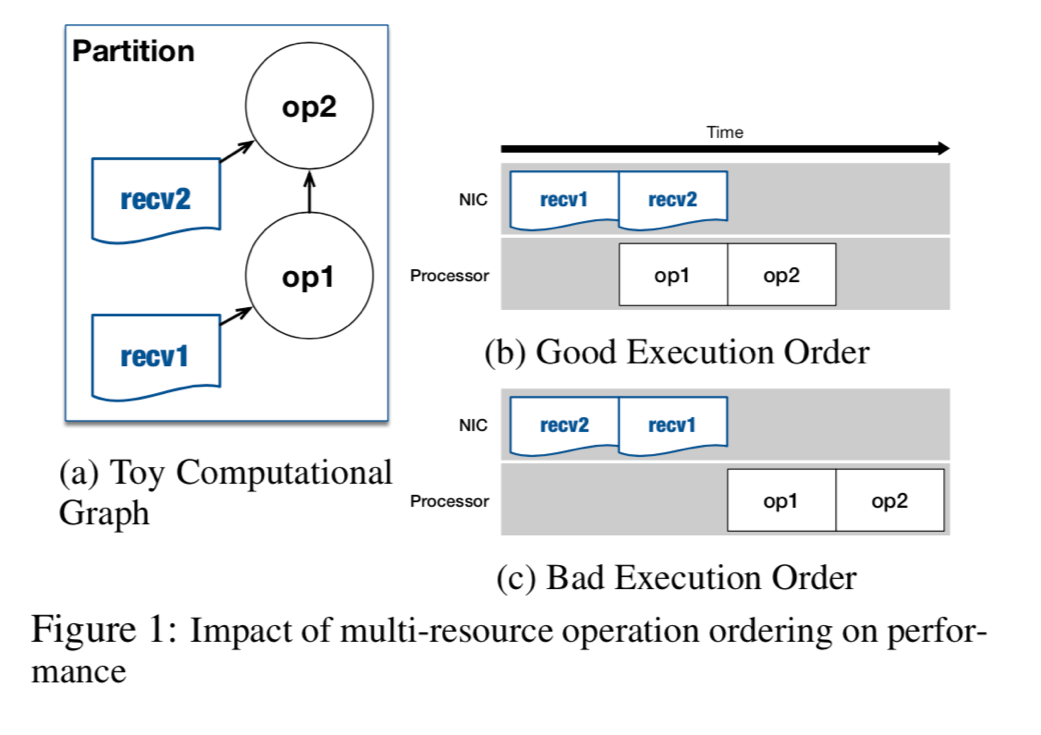
如图,网络带宽和传输的顺序是关键因素,网络带宽很好理解,如果 Best 要提高只能加带宽,同时传输顺序如图会影响计算时间。
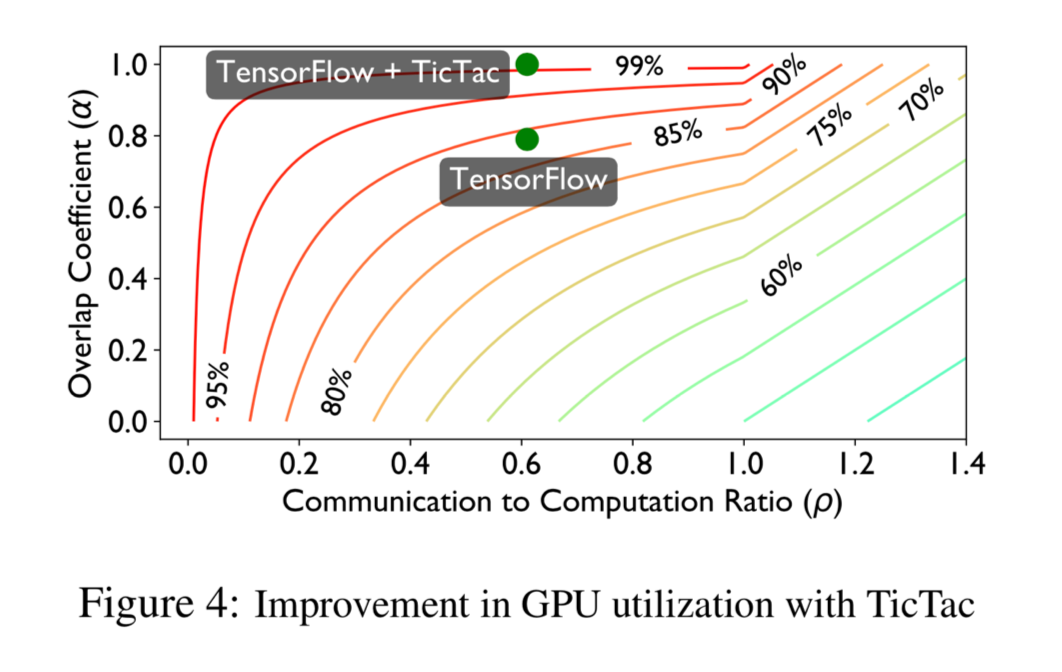
Communication to Computation Ratio 传输计算比,如果比值大说明效率高
增大 BatchSize,但是会过拟合(贾扬清的 Train ImageNet in 1 Hour),减小参数精度(FP16,腾讯绝艺 1024 张V100)。
Overlay Coeffiecient 提供传输和计算的重合率,是 TicTac 的优化方向。
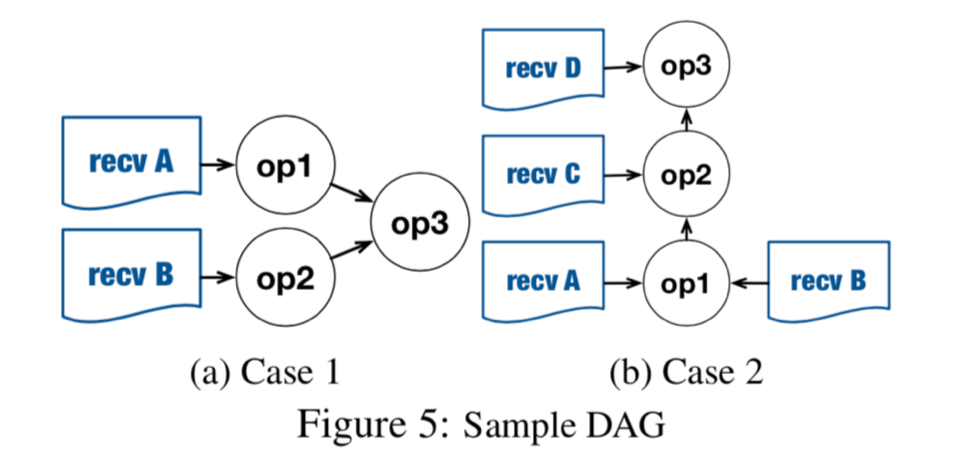
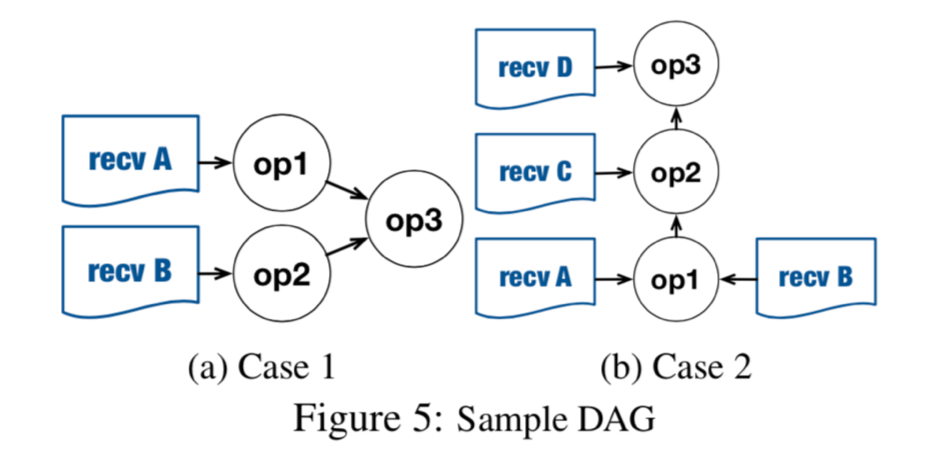
计算最优传输依赖,这是个 NP 问题,需要找近似解。recv op 是图的 root,可行的拓扑排序有很多种,解决方案就是找到近似优化排序。(原问题是 NP 问题)
几种符号
op.P 直接 Op 执行计算时间
op.M Op传输时间
op.M+ 触发计算 op 的最小传输时间
Tic
设 Communication Time 对于每个 recv op 来说都相等,从直觉上解释就是计算执行 recv op 的优先度。
如图计算对应的值
1 | case 1 |
越小优先级越高,这个可以在 DAG 中静态算出
Tac
Communication Time 对于每个 recv op 来说有对应的时间,对应的算法。


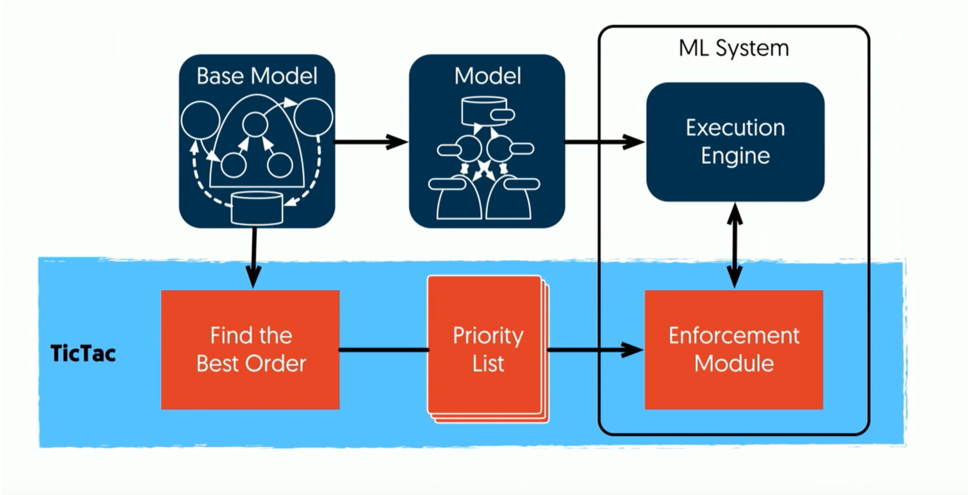
系统设计
Time Oracle: Tensorflow metrics 计算 op time
Ordering Wizard: 计算静态依赖优先级
Enforcing: 修改 Tensorflow gRPC 子模块
P3
PRIORITY-BASED PARAMETER PROPAGATION FOR DISTRIBUTED DNN TRAINING
和上一篇论文类似,也是基于传输优化的思路,因为网络带宽基本上就是一个硬件问题。一些优化手段是用了有损压缩或者降低收敛时准确率的方式。还是通过提高 overlap 来实现。
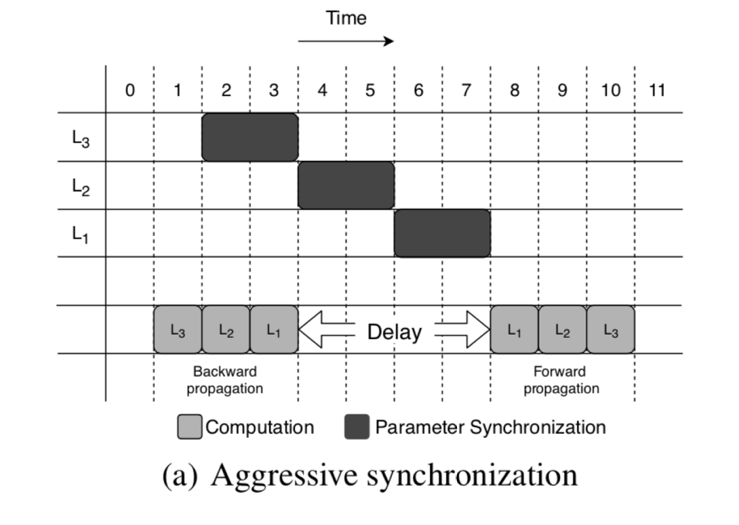
直观的现象是如图 L4 的一次正向传播和反向传播之间的间隔很大。
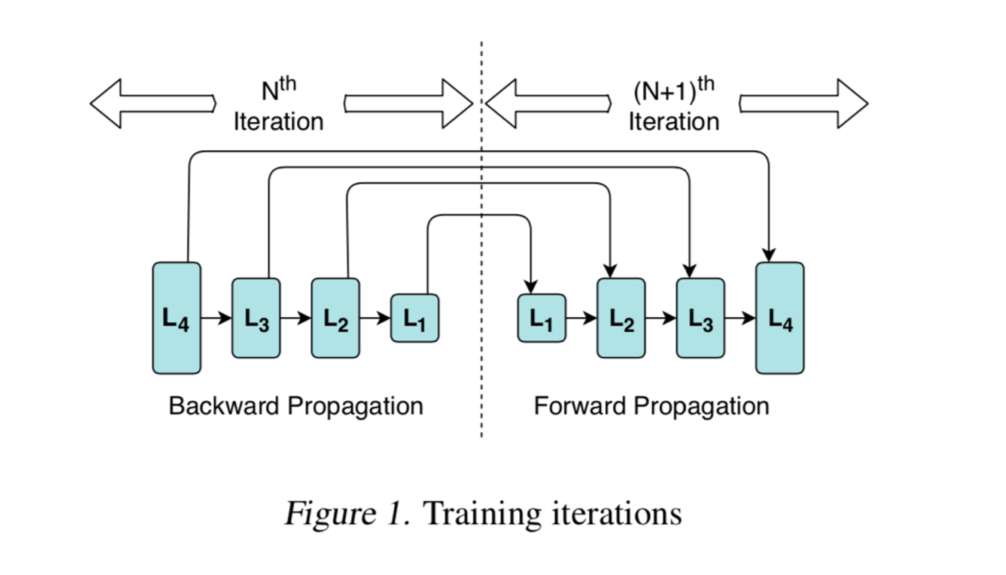
解决方法:带优先级的参数切分
在 MXNet 里面,worker 算完当层的梯度
就会提一个 pull request 当其他 work 同步了这个梯度。
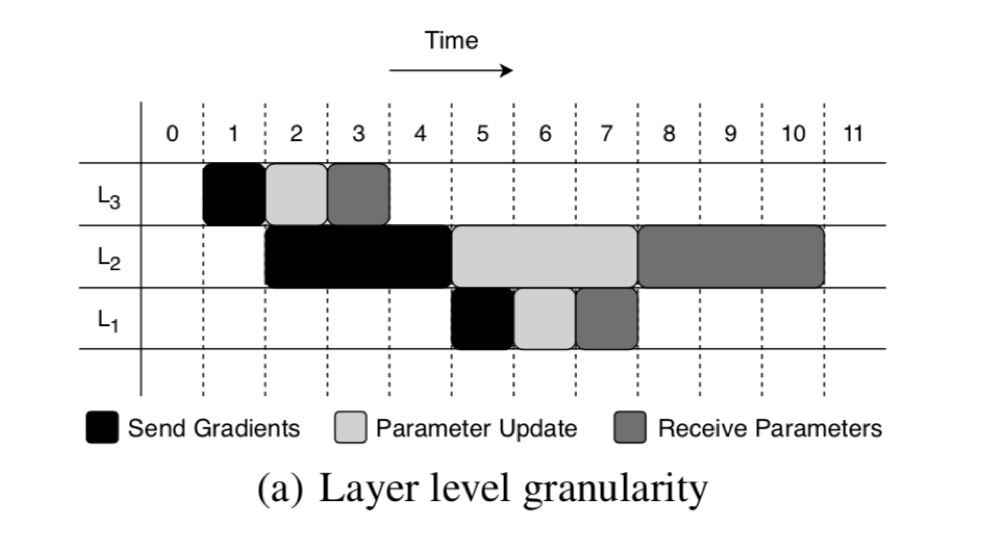
问题在于发送的顺序和反向传播的顺序一致,并且颗粒度
是以 layer 为单位的。
根据领域知识将大 layer 分片成小 slice。
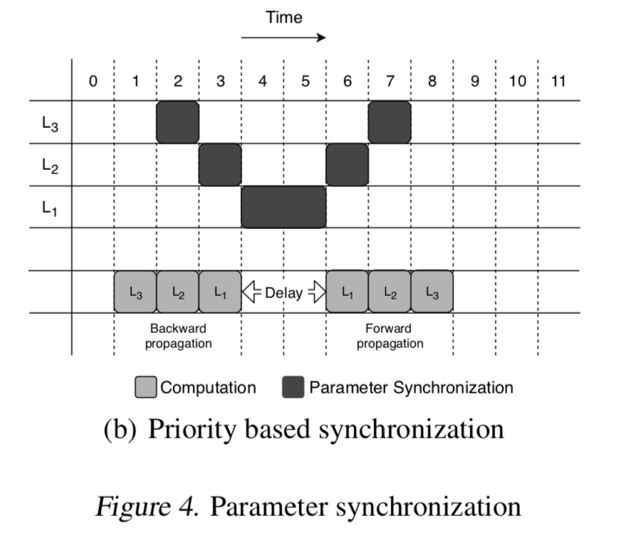
对每个 slice 进行权重排序,优先传输权重高的 slice。
被称为 Priority-Based Parameter Propagation
如图如果参数传输有优先级能够被中断就能减少 delay
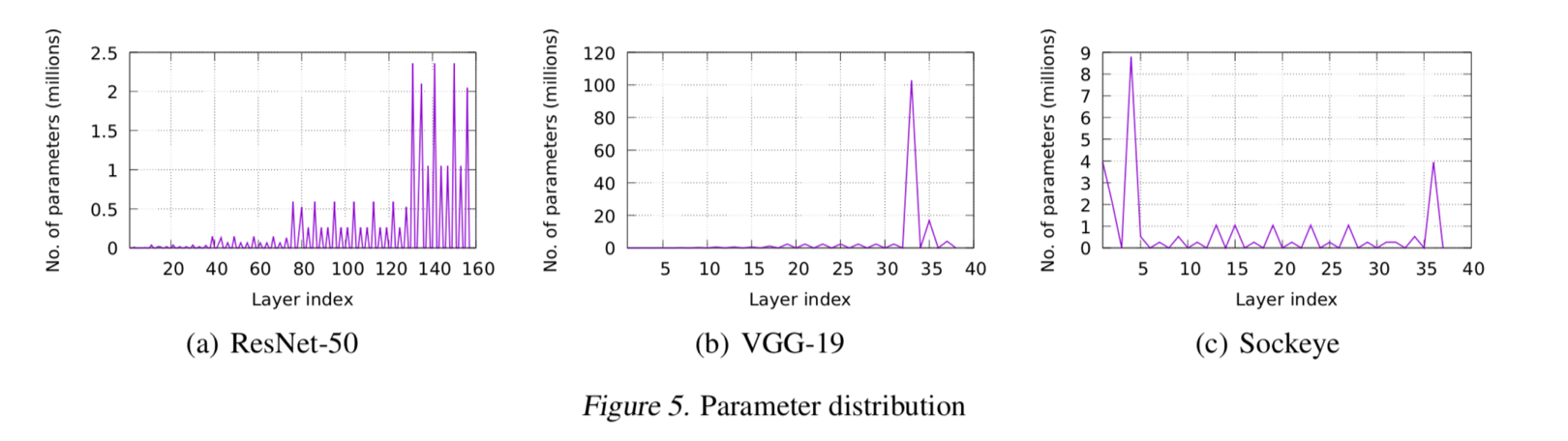
大部分模型每层的参数是不平衡的,特别是全连接的参数非常大。
对每一层切分以后利用 TCP 的全双工可以达到流水线的效果。
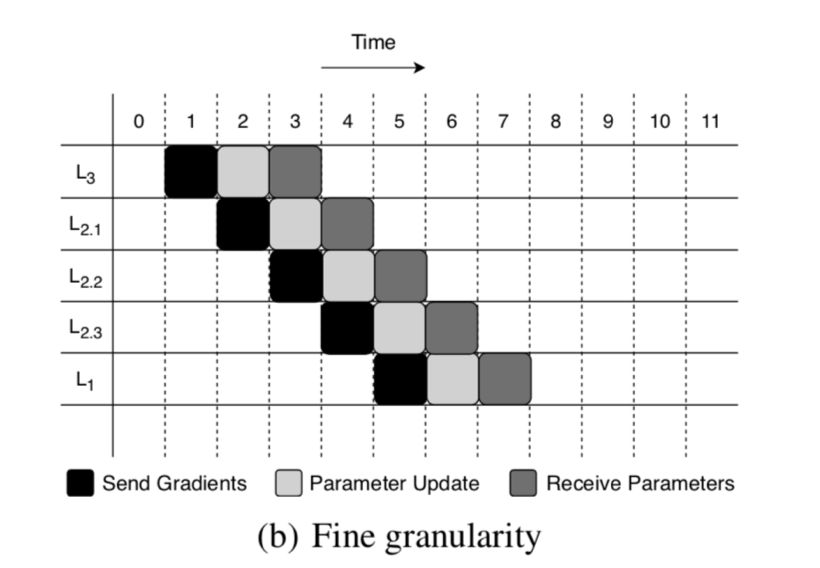
P3 的设计
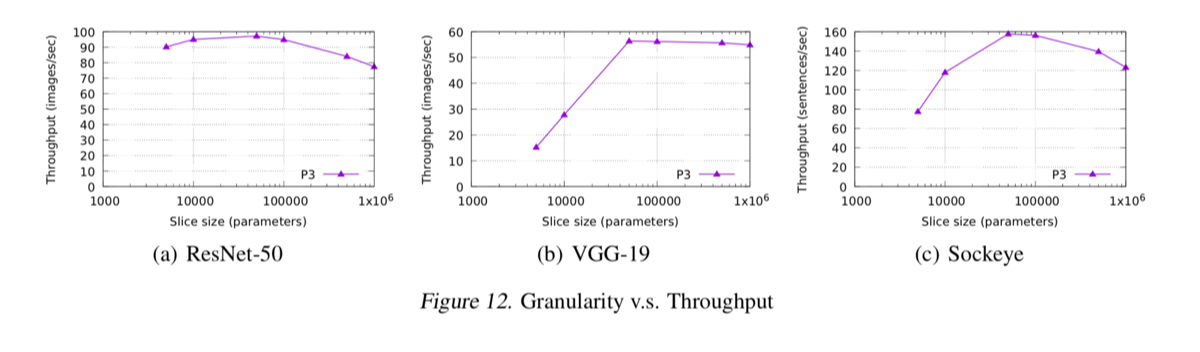
参数切片:根据领域知识和实验选择大小(50000)
参数优先级:下一层先需要的先发送,可以抢占低优先级的
我个人觉得简单,这个比上一个更好理解也简单。
BlueConnect
主要是一个对分层(原本的一层或者两层)的 All-Reduce 的泛化算法。
首先使用递归的方法可以减少 all-gather 的传输次数。
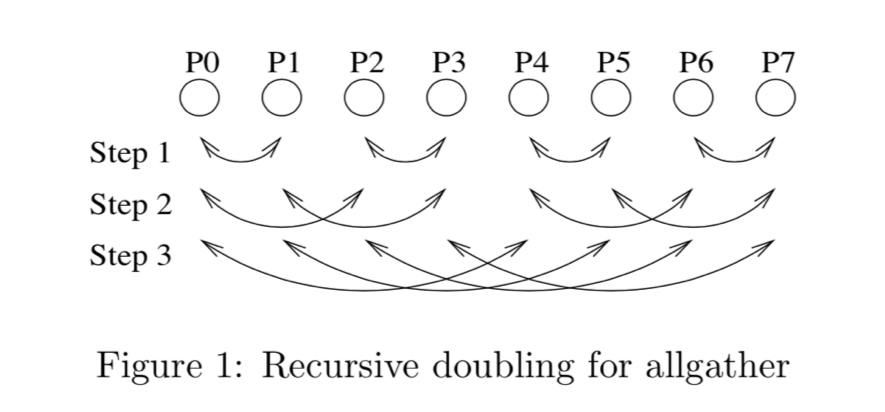
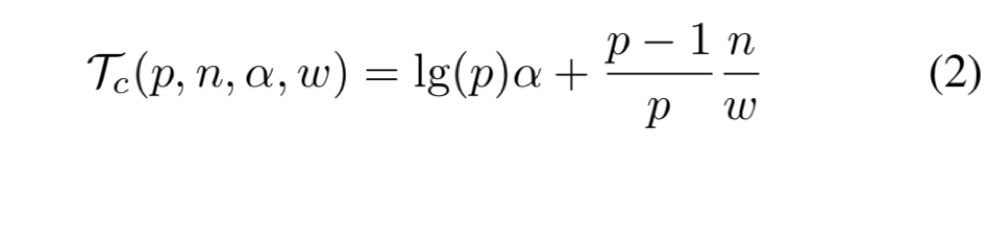
这个只要三次 logp
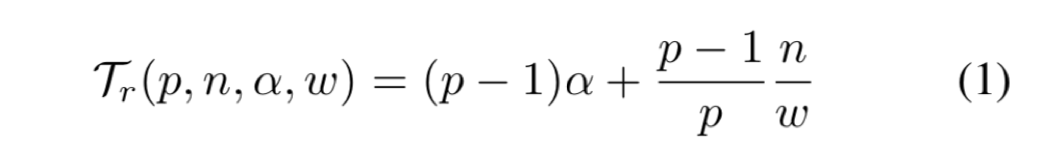
ring reduce 要7次 (p-1)
问题背景
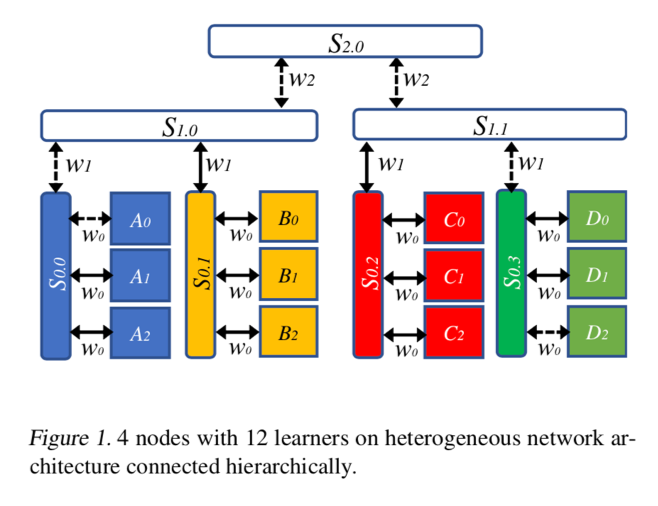
多卡之间的带宽很高 32GB/s,不同网络拓扑下,最慢的会成为瓶颈。
分两层可以解决网络和总线的带宽差异。
对于二层的一个泛化,
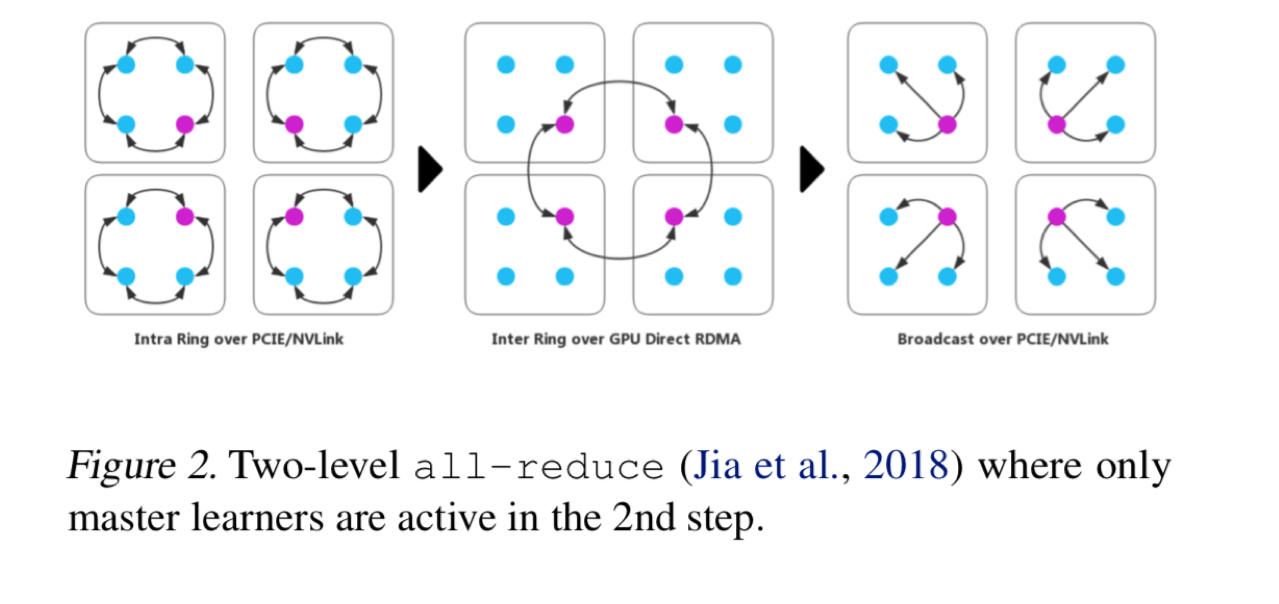
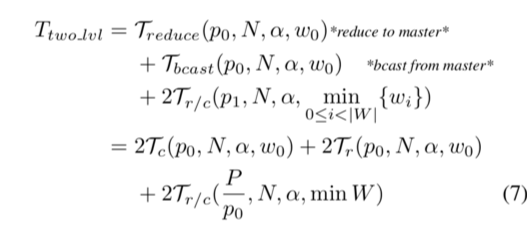

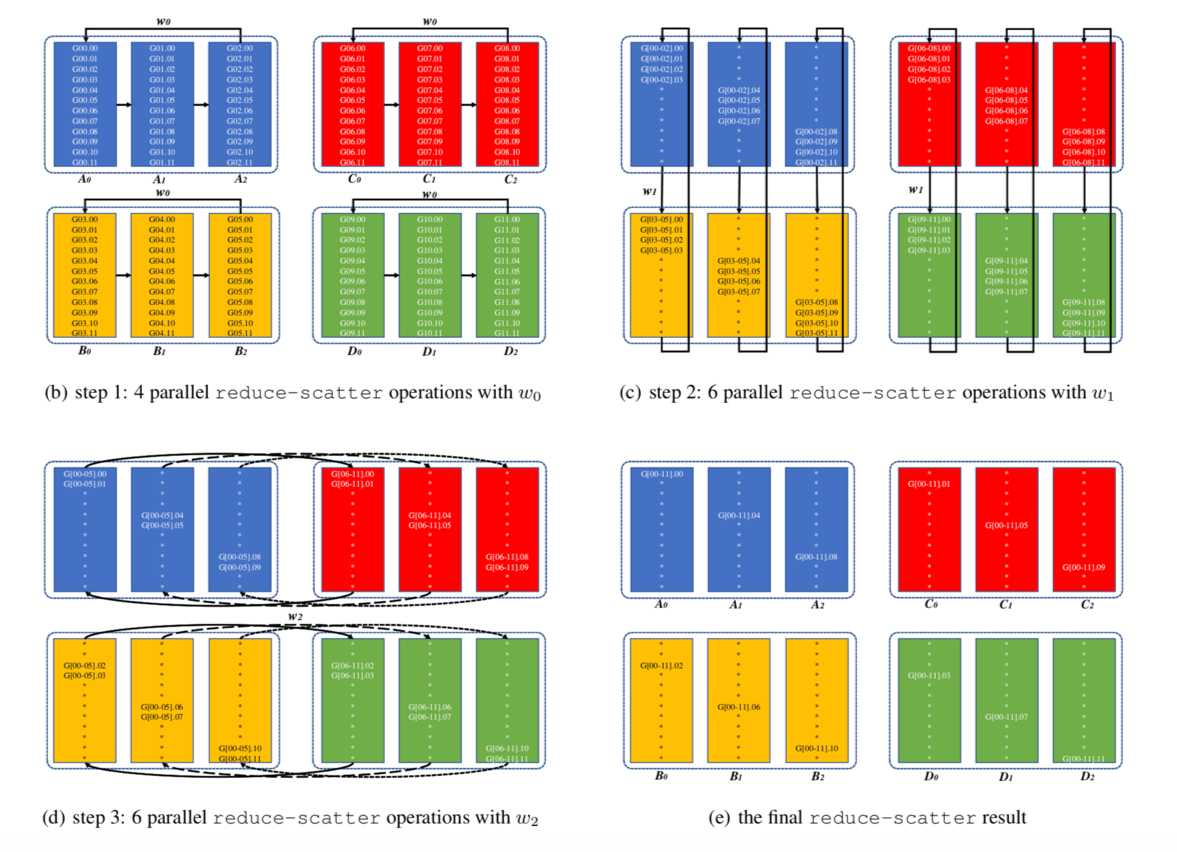
三层的 reduce-scatter 的例子,reduce-gather 是反的。
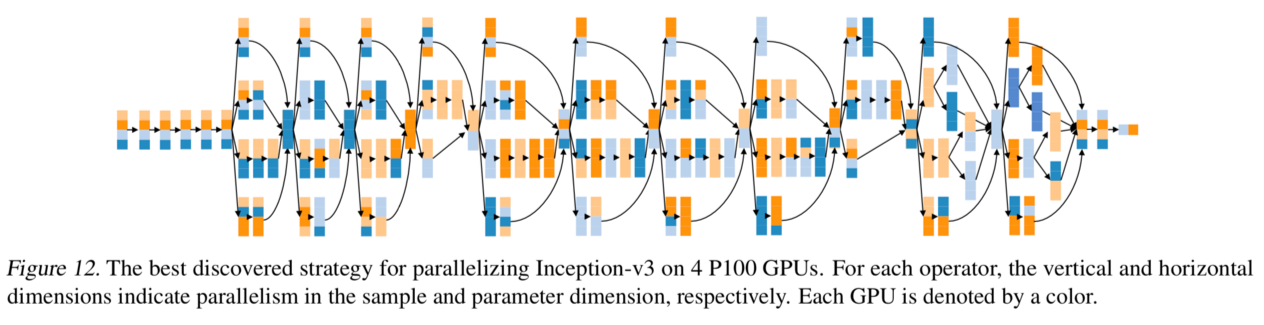
BEYOND DATA AND MODEL PARALLELISM FOR DEEP NEURAL NETWORKS
这个主要是提到了并行程度除了数据和模型之外可以更细粒度到参数和属性,也就是模型的小划分和样本的小划分。
SOAP= Sample Attribute Operator Parameter

全连接层有大量的参数,造成传输瓶颈。
领域特定的优化:RNN 和 CNN 用 data 并行,最后全连接用 model 并行。
搜索策略
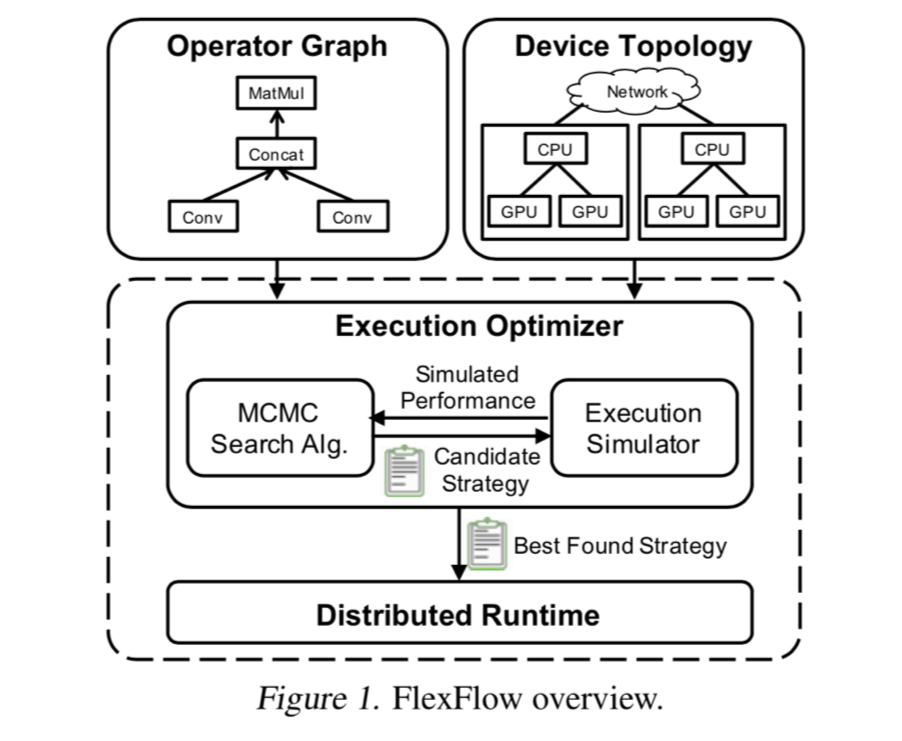
找到最优并行策略是 NP 问题。
Execution Optimizer 通过找到最小 cost 的
并行策略寻找较优解。
Cost = tensor size/ bandwidth

随机从搜索空间选取策略,依据 MCMC
最够贪心,又不会太局部贪心。
总的来有点和 AutoML 类似,在一个搜索空间选择一个策略使得 cost 最低,一个是原本的 cost 函数,这个是
计算本身执行的时间。目前主流框架也不支持 SOAP 级别的并行划分,没手调的好,但很接近。
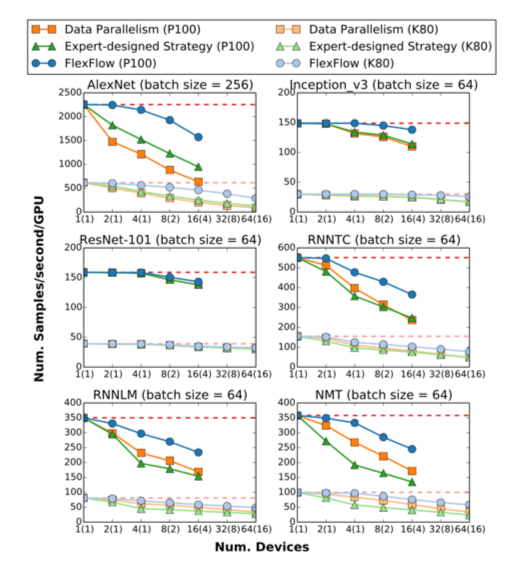
可以看到搜索出来的结果全连接基本上是单卡算的