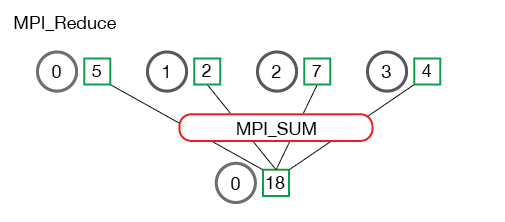
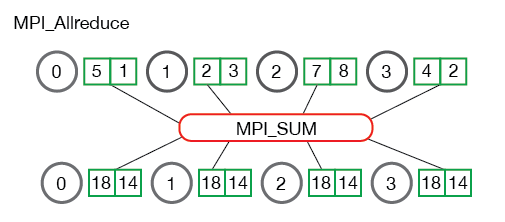
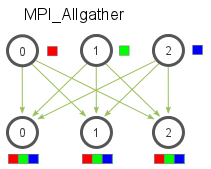
Reduce is a classic concept from functional programming. Data reduction involves reducing a set of numbers into a smaller set of numbers via a function. For example, let’s say we have a list of numbers [1, 2, 3, 4, 5]. Reducing this list of numbers with the sum function would produce sum([1, 2, 3, 4, 5]) = 15. Similarly, the multiplication reduction would yield multiply([1, 2, 3, 4, 5]) = 120.
In the system we described, each of the N GPUs will send and receive values N-1 times for the scatter-reduce, and N-1 times for the allgather. Each time, the GPUs will send K / N values, where K is the total number of values in array being summed across the different GPUs. Therefore, the total amount of data transferred to and from every GPU is
Data Transferred=2(N−1)KN
数据传输量在 N 比较大的时候越没有影响,这就消弭了多节点给 Parameter-Server 造成的瓶颈。
第二部根据 local_rank(相当于单节点上的第n张卡),并且设置不占用全部显存,按需分配(可能因内没有统一管理导致显存碎片),然后传递给 keras 设置 session。
1 2 3 4 5
# Horovod: pin GPU to be used to process local rank (one GPU per process) config = tf.ConfigProto() config.gpu_options.allow_growth = True config.gpu_options.visible_device_list = str(hvd.local_rank()) K.set_session(tf.Session(config=config))
# If set > 0, will resume training from a given checkpoint. resume_from_epoch = 0 for try_epoch in range(args.epochs, 0, -1): if os.path.exists(args.checkpoint_format.format(epoch=try_epoch)): resume_from_epoch = try_epoch break
# Horovod: broadcast resume_from_epoch from rank 0 (which will have # checkpoints) to other ranks. resume_from_epoch = hvd.broadcast(resume_from_epoch, 0, name='resume_from_epoch')
# Horovod: print logs on the first worker. verbose = 1 if hvd.rank() == 0 else 0
# Restore from a previous checkpoint, if initial_epoch is specified. # Horovod: restore on the first worker which will broadcast both model and optimizer weights # to other workers. if resume_from_epoch > 0 and hvd.rank() == 0: model = hvd.load_model(args.checkpoint_format.format(epoch=resume_from_epoch), compression=compression) else: # ResNet-50 model that is included with Keras is optimized for inference. # Add L2 weight decay & adjust BN settings. model_config = model.get_config() for layer, layer_config in zip(model.layers, model_config['layers']): if hasattr(layer, 'kernel_regularizer'): regularizer = keras.regularizers.l2(args.wd) layer_config['config']['kernel_regularizer'] = \ {'class_name': regularizer.__class__.__name__, 'config': regularizer.get_config()} if type(layer) == keras.layers.BatchNormalization: layer_config['config']['momentum'] = 0.9 layer_config['config']['epsilon'] = 1e-5
model = keras.models.Model.from_config(model_config)
# Horovod: adjust learning rate based on number of GPUs. opt = keras.optimizers.SGD(lr=args.base_lr * hvd.size(), momentum=args.momentum)
callbacks = [ # Horovod: broadcast initial variable states from rank 0 to all other processes. # This is necessary to ensure consistent initialization of all workers when # training is started with random weights or restored from a checkpoint. hvd.callbacks.BroadcastGlobalVariablesCallback(0),
# Horovod: average metrics among workers at the end of every epoch. # # Note: This callback must be in the list before the ReduceLROnPlateau, # TensorBoard, or other metrics-based callbacks. hvd.callbacks.MetricAverageCallback(),
# Horovod: using `lr = 1.0 * hvd.size()` from the very beginning leads to worse final # accuracy. Scale the learning rate `lr = 1.0` ---> `lr = 1.0 * hvd.size()` during # the first five epochs. See https://arxiv.org/abs/1706.02677 for details. hvd.callbacks.LearningRateWarmupCallback(warmup_epochs=args.warmup_epochs, verbose=verbose),
# Horovod: after the warmup reduce learning rate by 10 on the 30th, 60th and 80th epochs. hvd.callbacks.LearningRateScheduleCallback(start_epoch=args.warmup_epochs, end_epoch=30, multiplier=1.), hvd.callbacks.LearningRateScheduleCallback(start_epoch=30, end_epoch=60, multiplier=1e-1), hvd.callbacks.LearningRateScheduleCallback(start_epoch=60, end_epoch=80, multiplier=1e-2), hvd.callbacks.LearningRateScheduleCallback(start_epoch=80, multiplier=1e-3), ]
最后直接用 allreduce 计算一个 evaluation score。
1 2
# Evaluate the model on the full data set. score = hvd.allreduce(model.evaluate_generator(input_fn(False, args.train_dir, args.val_batch_size),NUM_IMAGES['validation']))
实现
适配层和压缩算法
horovod 的实现主要分几部分,第一部分是一个适配层,用于兼容各种框架,比如 tensorflow 的适配就是实现一个新的 Op,这个可以参考 add new op,里面规范了 Tensorflow 自定义算子的实现。
请注意,生成的函数将获得一个蛇形名称(以符合 PEP8)。因此,如果您的操作在 C++ 文件中命名为 ZeroOut,则 Python 函数将称为 zero_out。
C++ 的定义是驼峰的,生成出来的 python 函数是下划线小写的,所以最后对应的是,适配Op的代码在 horovod/tensorflow 目录下面
// The coordinator currently follows a master-worker paradigm. Rank zero acts // as the master (the "coordinator"), whereas all other ranks are simply // workers. Each rank runs its own background thread which progresses in ticks. // In each tick, the following actions happen: // // a) The workers send a Request to the coordinator, indicating what // they would like to do (which tensor they would like to gather and // reduce, as well as their shape and type). They repeat this for every // tensor that they would like to operate on. // // b) The workers send an empty "DONE" message to the coordinator to // indicate that there are no more tensors they wish to operate on. // // c) The coordinator receives the Requests from the workers, as well // as from its own TensorFlow ops, and stores them in a [request table]. The // coordinator continues to receive Request messages until it has // received MPI_SIZE number of empty "DONE" messages. // // d) The coordinator finds all tensors that are ready to be reduced, // gathered, or all operations that result in an error. For each of those, // it sends a Response to all the workers. When no more Responses // are available, it sends a "DONE" response to the workers. If the process // is being shutdown, it instead sends a "SHUTDOWN" response. // // e) The workers listen for Response messages, processing each one by // doing the required reduce or gather, until they receive a "DONE" // response from the coordinator. At that point, the tick ends. // If instead of "DONE" they receive "SHUTDOWN", they exit their background // loop.