Spark/Ray/PS/MPI等计算引擎和框架的小总结
大规模的并发并行计算考虑的问题主要关于数据、计算的吞吐量还有容错。不管是设计者还是使用者,关心的是在期望上(因为可能会失败)运行任务的效率,从设计者的角度来讲要提供一个可靠高效的环境,从使用者的角度来讲这个东西需要足够的简单,简单意味着编程效率也保证了可靠性。大数据的整套技术栈在解决一些吞吐量大的批处理问题时得心应手,但是到了深度学习的场景,计算吞吐的要求反而提高了,比较现实点的情况是很多时候我们考虑的是能处理多大的数据量的日志,和多快能把一个ImageNet ResNet50训练完。这个区别在于 Spark 或者 Hadoop 的 MapReduce 的设计和 Tensorflow 以及 PyTorch 的设计理念不同以及对应的计算场景的不同。到了强化学习的场景又是一个大融合,强化学习的场景不光有迭代式的反向误差传播的计算,同时也包含了大规模的仿真环境的计算,Ray主要是在这方面提供了一个一站式的解决框架。分布式系统的问题某种程度上和操作系统的问题其实很类似,都是要考量如何从整个系统的角度充分利用物理资源,从错误中恢复,满足效率。这篇文章主要是比较一下几种主流的计算引擎或者框架或者说是算法的异同。
Spark(MapReduce)
我把Spark和MapReduce都归于大数据栈这一类,RDD(Resillient Distributed Dataset) 和 MapReduce
这两者的区别没有和MPI/PS的区别大那么多。
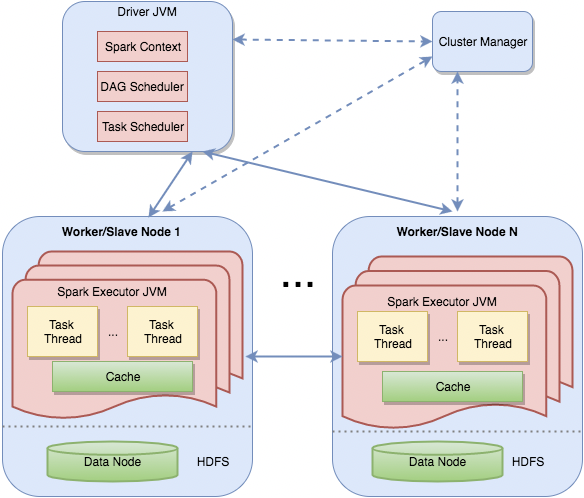
MapReduce 有 JobTracker,Spark 有 Driver
MapReduce 有 TaskTracker,Spark 有 Executor
MapReduce 中间结果是基于 HDFS,会落盘,Spark 中间结果是基于内存的,也可以落盘,主要是利用内存做缓存
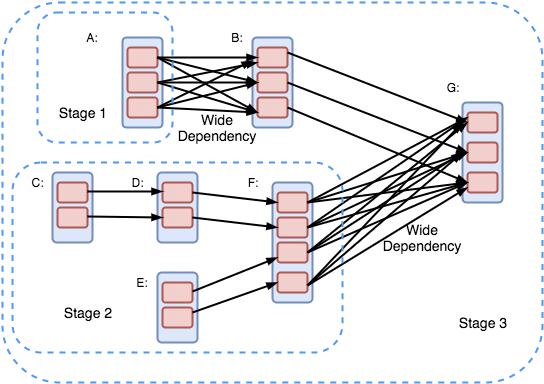
MapReduce 计算抽象由Map和Reduce构成,Spark 的 RDD 有一系列的Transform和Action,封装程度更高
MapReduce 的错误处理比较简单,把失败的Map重试就好了,重试是一种非常好理解的错误处理。
Spark 的重试是根据 RDD 的有向无环图中的血缘关系计算的,可以理解为从失败的拓扑序上重新计算,也可以有中间的checkpoint。
RDD 的特性是只读的,在机器学习场景下参数不大的时候 MLLib 通过把参数存到 Driver 上来计算,当参数比较大特别是深度网络的参数大得吓人 Driver 存不下的时候,
只能通过新增 RDD,对于要频繁更新的模型参数要生成非常多的 RDD,这是 Spark 在深度学习上设计的缺陷。
一般来说一些简单的机器学习任务通过 sklearn 就能完成,当数据量比较大的时候就需要通过 Spark 的MLLib来处理。
当然 MLLib 现在也在开始从RDD-based转向SparkSQL用的Dataframe-based,从大的角度上讲两者互相融合是可行的,可能需要一些时间。
上 Spark 用 Yarn 调度 Tensorflow,还是用 Kuberenetes 调度 Spark 和 Tensorflow,我个人支持后者,而且这种分层是我比较喜欢的一种分层。
Ray
Ray 的基本抽象就是 Remote 或者 Actor,一个是分布式调用函数,一个式分布式调用类。Ray 和 Ray 的 RLlib 主要面对的问题是强化学习有大量的 simulating 的环境,比如仿真一局Dota,涉及到模拟一局Dota,反馈Agent的神经网络,是并行计算和神经网络训练的结合。当然 Ray 本身的抽象就是个分布式 goroutine,所以某种程度上可以完成的事情不光是强化学习一种任务,比如HypterTunning等一些并行计算的模型也是试用的。
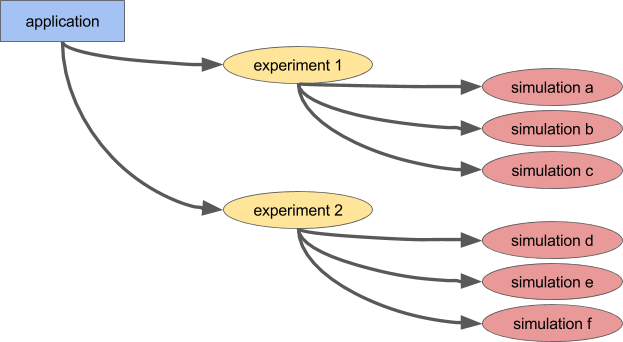
反过来想,如果没有 Ray 的话,如何做这个系统呢,要构建大批量的仿真计算环境,然后能根据仿真的反馈训练神经网络。
这两个任务的调度控制就是一个问题,当然放到 k8s 的调度器里做似乎也可以,然后涉及这些分布式任务的同步问题,
需要构建这些任务的关系和信息传输,似乎用一些 DAG (比如 argo)的 workflow 也能解决,但他们之间通信的高效性似乎会是一个问题,需要
选择一种高效的远程调用传输方式,肯能gRPC也可以,还有他们的元数据管理用什么呢,自己搞个Redis似乎也行。
Ray 从这些方面综合考虑了这些问题提供了一个一站式的RL训练平台。
PS和MPI
MPI和PS的介绍有很多,我也不需要费篇幅唠叨。
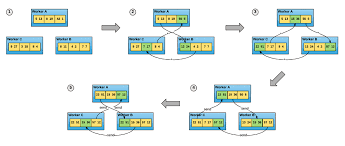
PS和MPI是比较常用的分布式深度学习的训练方式,两者的主要区别在于Paramater Server,在PS的场景下参数统一走一个或者shard多个PS更新。
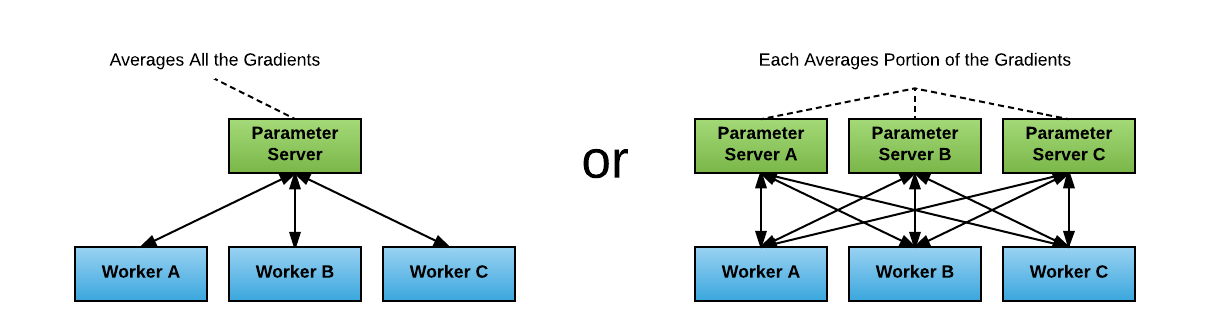
在MPI的场景下每个Worker是对等的(或者分层级对等,比如主机上的四张卡走NVLink,主机之间走万兆网卡)工作节点,使用AllReduce参数的同步在Worker之间进行。
总结
MPI在我出生前应该就有了,但是MapReduce之所以能火起来主要还是在 fault-tolerance 上,MPI的抽象比较基础,但是MapReduce和Spark在廉价大集群上的表现非常亮眼,对于没那么并行化理想的场景能够tolerate,时间到了深度学习的场景这玩意儿又冒出来了,一方面是深度学习的计算资源好得不得了,因为配备GPU的机器和传统的机器比起来好很多,对于这种纯粹的并行计算框架来说非常友好,错误处理的问题就没那么严重,即使是这样也慢慢开始有人着手优化MPI/PS的fault tolerance,在一些并行化退化的场景下能够把训练并行度降级不至于完全失败的工作。
从长远来看 Ray 还会有很多进化的空间,Spark 也会更好地适配深度学习场景,深度学习本身在System上的优化也层出不穷,大家对于大规模的并发并行计算系统的方方面面的要求都会越来越高。