FlashAttention 解析
FlashAttention是一种新型的注意力算法,它能够准确计算注意力,且只需进行远远少于传统方法的内存访问。这个算法的主要目标是尽可能避免内存的读取和写入,这是注意力机制性能瓶颈的一个关键因素。该论文提出了一个IO-aware的精确注意力算法,它使用tiling(贴瓷砖,代表数据分片)来减少GPU高带宽内存与低带宽内存之间的内存读取/写入次数。
该算法基于注意力矩阵通常稀疏这一观察结果:注意力矩阵只有少数元素非零。它通过将输入矩阵Q、K、V分成更小的块来实现,从而避免了计算全矩阵乘积Q*K^T的内存占用问题。通过块级别的处理,FlashAttention使得矩阵操作可以在现代GPU的内存限制下进行,并仅读取/写入每个切片的非零元素。这降低了需要的内存访问次数,使整个过程更快和更高效。
FlashAttention通过分“瓦片化”的方式计算能够更快的一个原因是将矩阵放入更高速的缓存当中,高速的叫SRAM,低速的叫HBM。
第一代 FlashAttention 只是把QK切片,这个只要把矩阵切分在SRAM,然后计算出结果再存回HBM,这个比较简单。
第二代 FlashAttention 把 softmax 的计算也放在了SRAM上。
源自博客描述的结构中可以看出。
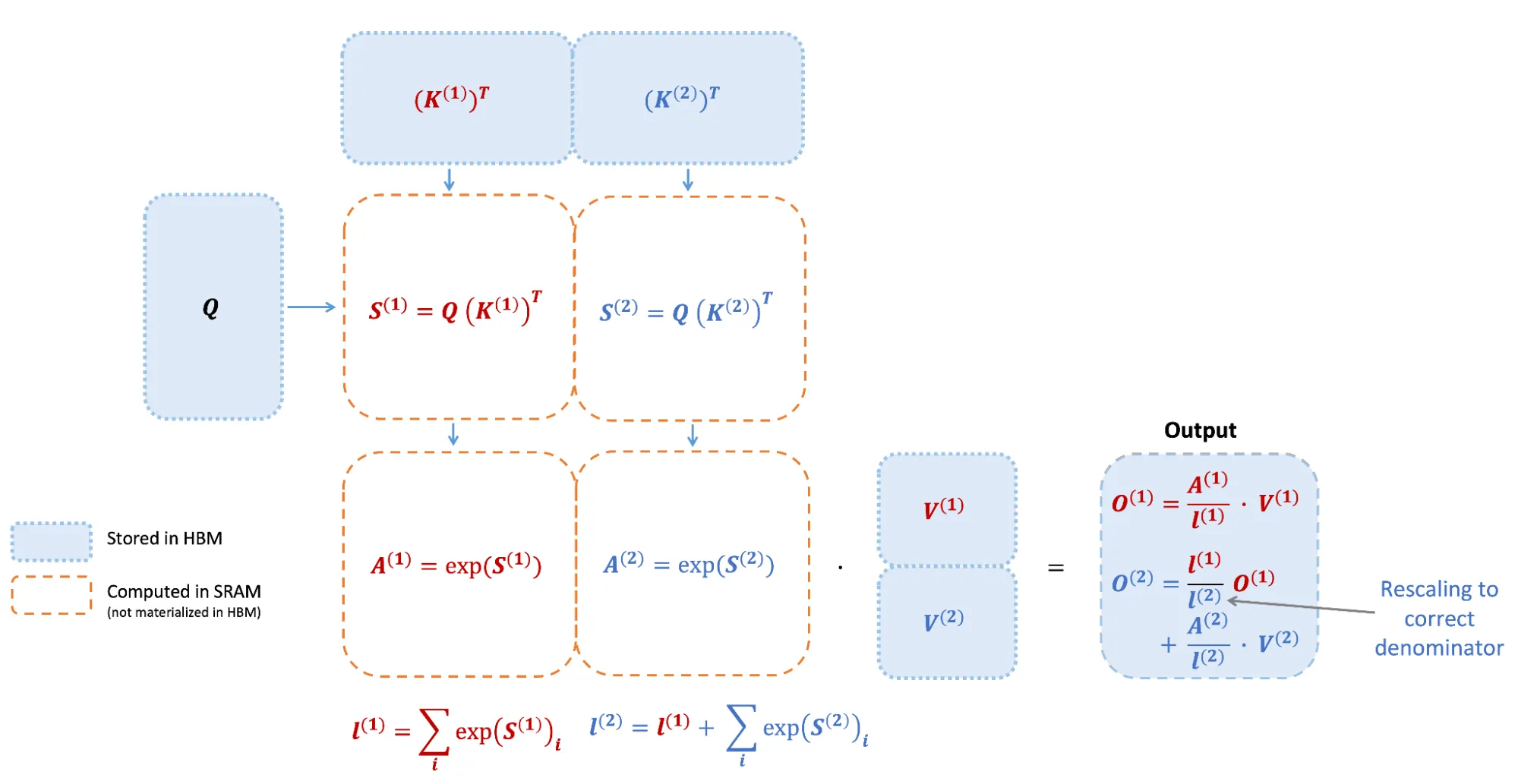
他这里面标得感觉不是很清楚,其中的O_2应该是最终的结果O,里面的l_1/l_2 * A^1 / l_1 就还原出了最终结果的分母,也就是scale法则。
第三代 FlashAttention 减少了上面提到的scale,不再每一步做除法,而是放到最后再除。还有就是针对交叉注意力中的mask的优化,跳过了被mask的部分。还有就是CUDA Thread warps的优化提高了并行度。
总结
FlashAttention通过利用高速缓存和分块技术,显著减少了内存访问次数,提高了注意力计算的效率。第一代主要通过切分QK矩阵并利用SRAM缓存,第二代将softmax计算也放入SRAM,第三代则进一步优化了scale计算和mask处理,并提升了并行度。