vLLM 分析2 计算引擎
vLLM的一个主要贡献就是PagedAttention,可以实现更高效的推理。
高效的语言模型服务系统(LLM)需要批量处理多个请求。然而,现有系统存在以下问题:
- 每个请求的key-value缓存(KV缓存)内存巨大,动态增长和减少。
- 容易因为碎片化和冗余复制导致内存浪费,限制了批量大小。
为了解决这些问题,提出了PagedAttention,一个基于虚拟内存和分页技术的注意力算法。基于此,开发了vLLM,一个LLM服务系统,实现了以下两个目标:
- KV缓存显存的几乎零浪费,减少了显存碎片。
- KV缓存在请求之间和请求内共享,进一步减少显存使用。
论文包含了他早期设计。
一次调用的示例如博客中展示的。
AsyncLLM
generate细节:
- 如果引擎没有运行,启动后台循环,循环调用
_run_output_handler方法来处理等待的请求。 - 从
AsyncStream中等待请求输出并生成它们。
engine会在启动之前profile一下,把剩余的显存分配给kv cache用。
AsyncStream 对 asyncio.Queue的封装,支持了终止的能力,当finish的时候会丢入一个STOP_ITERATION的exception,这样可以让调用者知道这个stream已经结束了。
每当有一个对话请求的时候调用add_request就会生成一个这样的AsycStream用于处理对话的输出,其中副作用就是判断backgroud loop没有启动的时候,启动backgroundloop。
AsyncEngine本身有一个_new_request的Queue用户保存request的AsyncStream。
generate方法会不断从AsyncStream中yield出结果,直到遇到STOP_ITERATION。
loop的主体如下:
1 | # 1) Pull EngineCoreOutput from the EngineCore. |
When TP=n & PP=m, vLLM engine will have n*m + 1 processes in total.
Corollary: even when using a single GPU, we will have 2 processes.
EngineCore
EngineCore主要是完成 schedule、execute 和 output 的循环。
1 | def step(self) -> List[EngineCoreOutput]: |
Request
在具体分析之前,先看看 Request 的定义,这个数据结构串联了很多东西。
属性 num_tokens 代表的是 prompt_tokens 和 output_tokens 的总数。
1 |
|
num_output_tokens 代表 output tokens 的数量。
1 |
|
append_output_token_ids 会改变上述的两个属性。
1 | def append_output_token_ids( |
在 __init__ 方法中,会设置 num_prompt_tokens,这个是不变的,num_computed_tokens 会初始化为 0。
1 | self.prompt = self.inputs.prompt |
所以在最开始时,num_tokens 和 num_prompt_tokens 是相等的。当 prefill 以后,num_computed_tokens 会逐渐(逐渐的原因是 prefill 可能会被 chunked 掉)等于 num_prompt_tokens。decode 以后,num_tokens 会等于 num_prompt_tokens 加上 num_output_tokens。如果 computed_tokens 等于 num_tokens,说明已经开始 decode 了,要开始一个 token 一个 token 计算了。
在调度过程中没有直接用 computed_tokens 等于 num_prompt_tokens 的原因是:如果一个 request 被抢占掉,那么 num_tokens 在 request 恢复的时候其实应该是 num_prompt_tokens 加上 num_output_tokens,这里做了一个统一的判断。如果把preempted的request重新处理的话其实相当于多了一些output tokens的prompt的新request。
Scheduler
从 EngineCore 的 step 方法来看,目前的调度是同步的 schedule | execute model | update_from_output | schedule | execute model | update_from_output,这样会导致计算和调度之间的时间差,这个时间差会导致计算的时间没有充分利用,从而导致资源的浪费。后面的版本应该会有优化。
Scheduler 的 V1 版本把一些 chunked prefill 还有 prefix caching 的内容拆离出去,做得比较通用。
vLLM 实现了一种所有或无(all-or-nothing)驱逐策略,即要么驱逐一个序列中的所有块,要么不驱逐任何块。
接下来看看来自 v1/core/scheduler.py 的 V1 版本的 schedule 实现。
Scheduler 有个 waiting list 和 running list(位置代表权重,是 FIFO 的)。
从 running list 中获取 request 然后通过 kv_cache_manager 执行 append_slots 把新的 block 追加到 request 的 block chain 当中。如果最后一个 block 的 slot 还够的话,就不会追加新的 block。
1 | new_blocks = self.kv_cache_manager.append_slots( |
如果当前的 kv_cache 的 block table 满了,则会抢占一个 running list 中的 request(放入 waiting list 中)并且把他的 cache block 都 free 掉,这里的 free 是引用计数的形式,如果引用计数为 0 就会被释放,但如果多个 request 共享了一个 block 就还不会被真正释放。
1 | if new_blocks is None: |
加入到 scheduled_running_reqs 中,消耗这次调度的 token budget,这个 budget 用完以后就会停止调度了。
1 | scheduled_running_reqs.append(request) |
如果没有抢占请求则说明还是比较富裕的,尝试从 waiting list 中获取 request,waiting list 可能有新请求也可能有之前被抢占的请求,然后执行一遍上面的代码,不同的是需要从 kv_cache_manager 计算 computed_tokens,因为被之前被抢占的或者一些有共同前缀的 kv cache block 是已经缓存过的。
1 | request = self.waiting[0] |
最后把每个 request 分配到的 tokens 数量记录到 SchedulerOutput 当中。
update_from_output 接受 SchedulerOutput 和 ModelExecutorOutput,更新 request 的状态,例如更新已经计算的 token 数量,更新 kv cache 的 block 等。对于每个请求都会检查 request.num_computed_tokens == request.num_tokens 从而判断是否已经开始 decode 的部分了。然后构造 EngineCoreOutput,并且检查是否需要停止这个 request。_check_stop 方法会检查是否已经生成了 eos token 或者已经达到了最大长度,并且 free 掉对应的 request。所有没有 stop 的 request 会重新加入到 running 队列中。
1 | if request.num_computed_tokens == request.num_tokens: |
SchedulerOutput
该类包含了调度器的输出信息。以下是各个字段的作用:
scheduled_new_reqs: List[NewRequestData]
- 作用:存储新请求的数据列表,这些请求是刚刚被调度的。
scheduled_resumed_reqs: List[ResumedRequestData]
- 作用:存储恢复请求的数据列表,这些请求是之前被暂停,现在重新被调度的。
scheduled_running_reqs: List[RunningRequestData]
- 作用:存储正在运行请求的数据列表,这些请求在当前调度周期内继续运行。
num_scheduled_tokens: Dict[str, int]
- 作用:存储每个请求调度的token数量,键是请求的ID,值是对应的token数量。
total_num_scheduled_tokens: int
- 作用:存储所有请求调度的token总数。
scheduled_encoder_inputs: Dict[str, List[int]]
- 作用:存储每个请求的编码器输入,键是请求的ID,值是对应的编码器输入列表。
preempted_req_ids: Set[str]
- 作用:存储被抢占的请求ID集合,这些请求在当前调度周期内被暂停。
finished_req_ids: Set[str]
- 作用:存储已完成的请求ID集合,这些请求在当前调度周期内完成。
free_encoder_input_ids: List[Tuple[str, int]]
- 作用:存储空闲的编码器输入ID列表,每个元素是一个元组,包含请求ID和对应的编码器输入ID。
这些字段共同描述了调度器在一个调度周期内的所有操作和状态变化。
KVCacheManager
来自v1/core/kv_cache_manager.py,这是v1版本的实现。
kv cache比较简单,
这个博客中的图片很好地阐述了kvcache的作用。

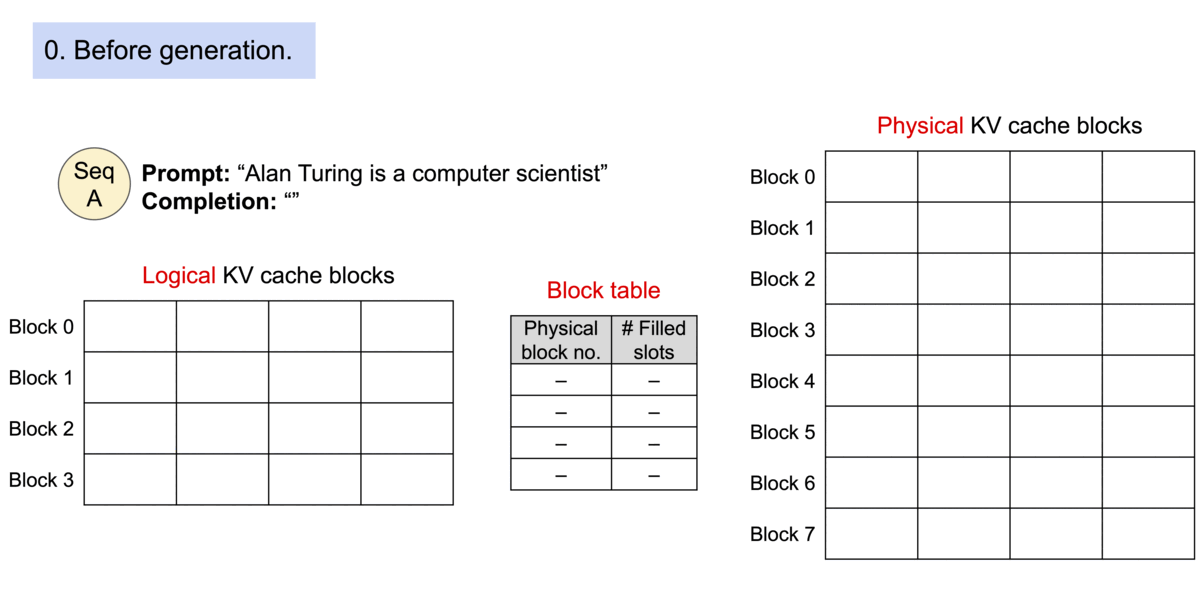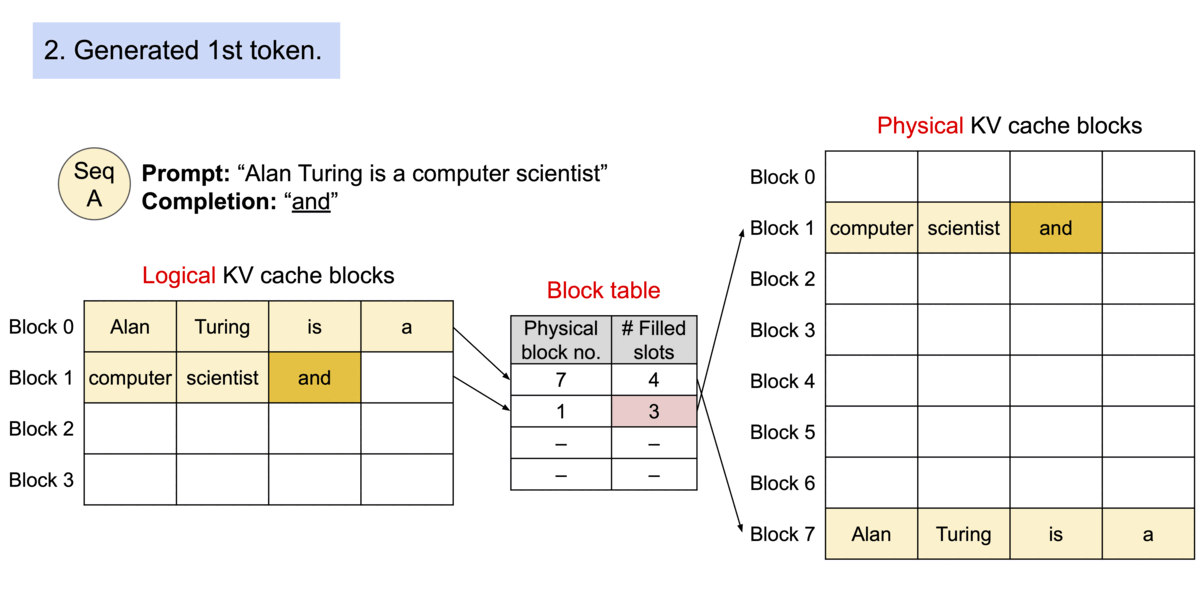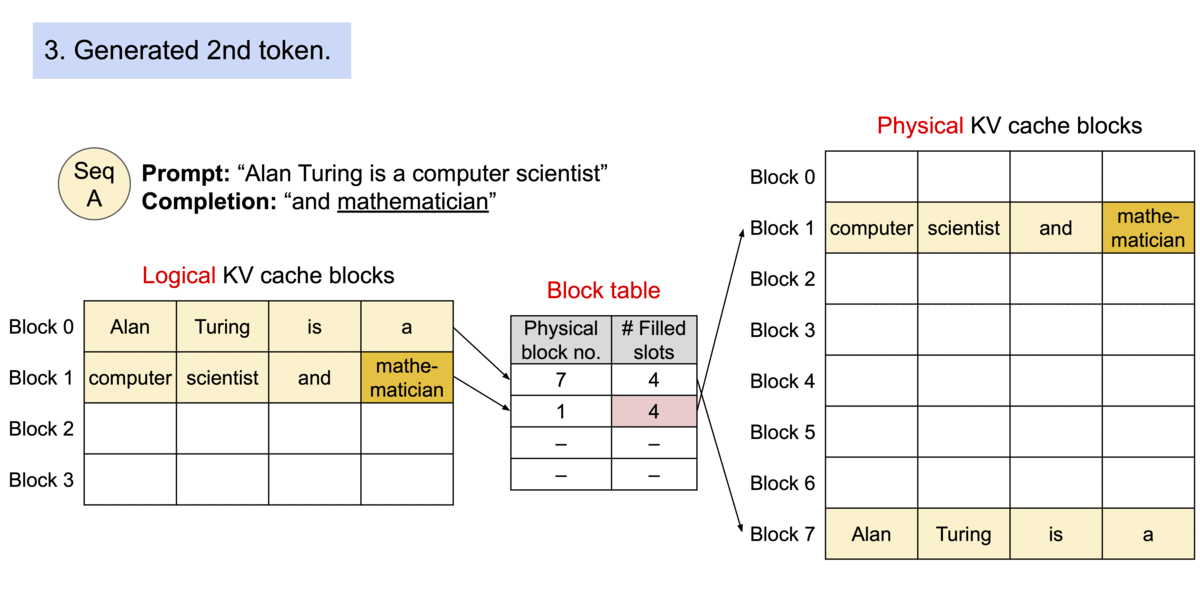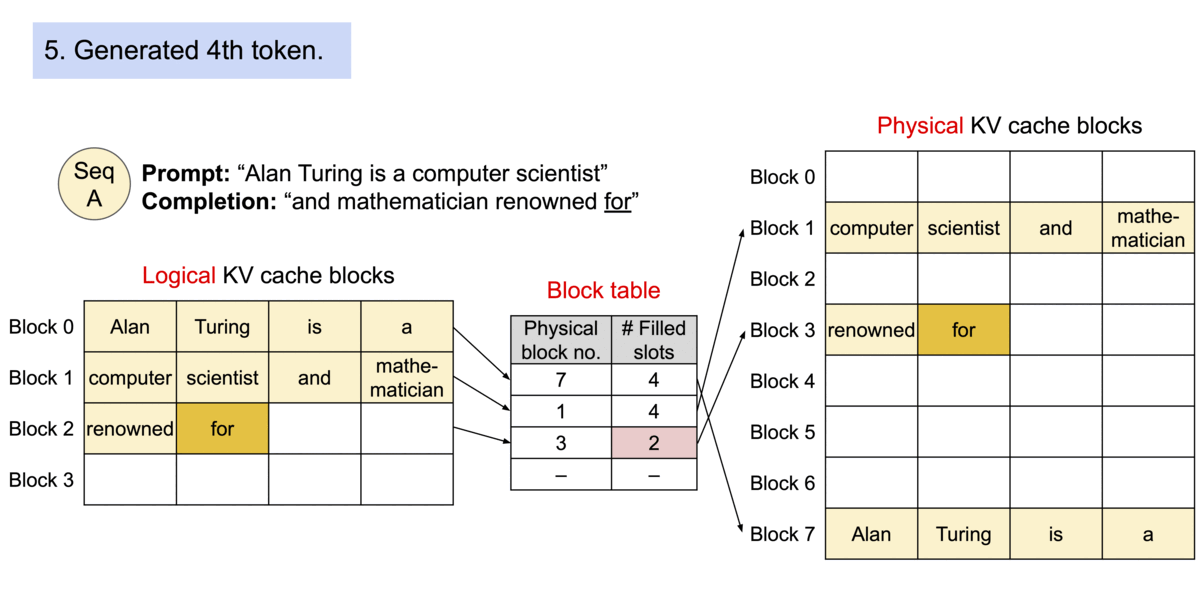
但涉及PagedAttention的实现,就需要管理block。这类似于操作系统中的虚拟地址、页表和物理页的关系。
PagedAttention的主要思想是基于操作系统中分页(paging)的经典概念。传统的注意力算法通常要求keys和values在内存空间中连续存储,
而PagedAttention则允许在非连续的内存空间中存储keys和values。
PagedAttention将每个序列(sequence)的KV缓存(KV cache)分成固定大小的块(block)。
每个块包含一个固定数量的token的key和value向量。这意味着,即使keys和values不连续存储,也可以有效地访问和操作它们。
block的管理会有一个类似于页表的结构,用于映射block的逻辑地址到物理地址。
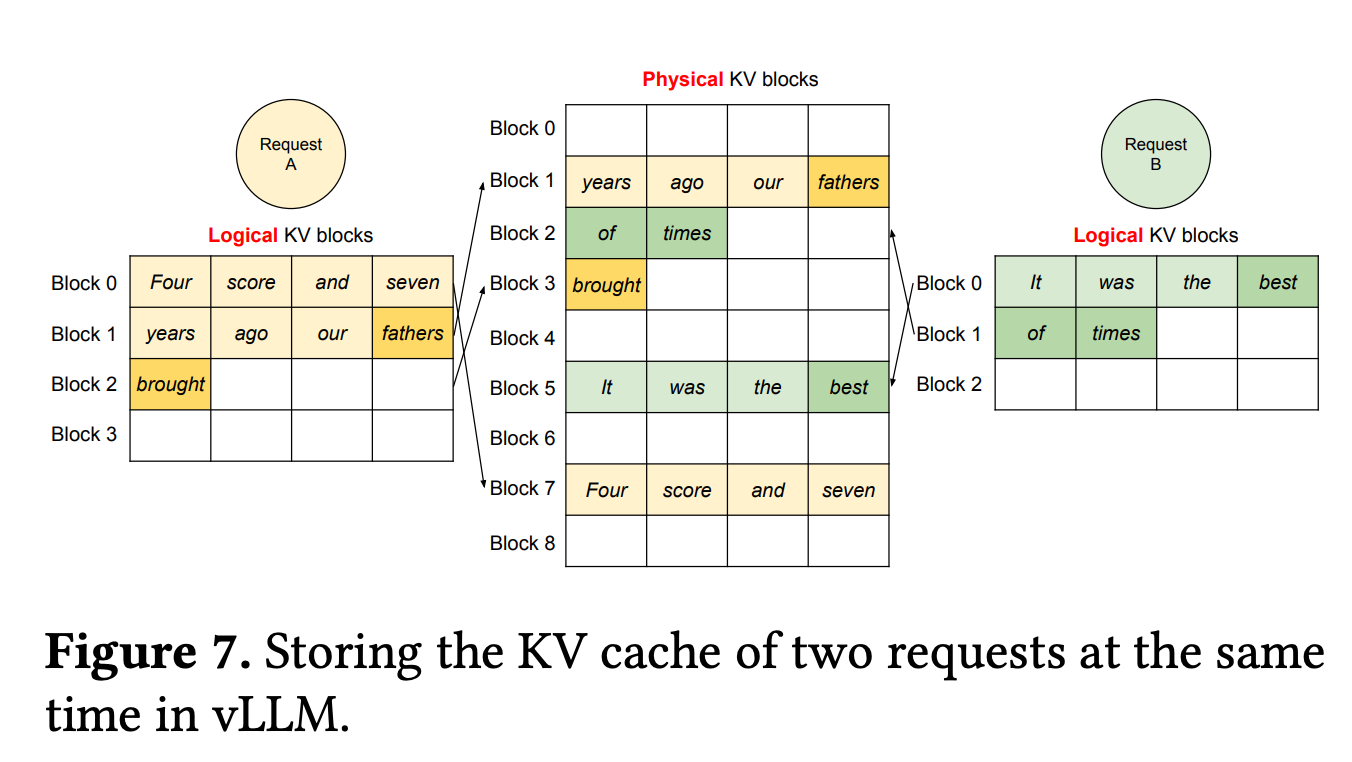
论文中的这个图很好的表示了他们的关系,如果新生成的token填满了当前block就会分配一个新的block用于新token的生成。
共享的prefix cache指的是提示词的前缀一样的情况,他们的位置编码也不变的情况下可以在不同的sequence之间共享。
例如对于一个英语到法语翻译的提示词,前面有很多事可以共享的,对于跨请求的kv cache来说可以基于这个前缀来共享kv cache的block。
| 序列 | 前缀 (Prefix) | 输入任务 (Task Input) | 完整提示 (Complete Prompt) | LLM 输出 (LLM Output) | 输出任务 (Task Output) |
|---|---|---|---|---|---|
| Sequence A | Translate English to French: “sea otter” => “loutre de mer” “peppermint” => “menthe poivrée” “plush giraffe” => “girafe en peluche” |
“cheese” => | Translate English to French: “sea otter” => “loutre de mer” “peppermint” => “menthe poivrée” “plush giraffe” => “girafe en peluche” “cheese” => |
fromage | fromage |
| Sequence B | Translate English to French: “sea otter” => “loutre de mer” “peppermint” => “menthe poivrée” “plush giraffe” => “girafe en peluche” |
“I love you” => | Translate English to French: “sea otter” => “loutre de mer” “peppermint” => “menthe poivrée” “plush giraffe” => “girafe en peluche” “I love you” => |
Je t’aime | Je t’aime |
free_block_queue是一个链表,用于分配block,初始化时将block_pool中的所有blocks串起来。它通过链表实现对KVCacheBlock的管理,删除操作是O(1)的,没有使用标准库中的dequeue。
KVCacheBlock除了prev和next指针,还有ref_count和_block_hash,用于prefix caching的计算。其key是父block的hash和当前block的tokens ids的hash。
block_pool代表物理block的映射关系,例如0 -> 第一块block。
1 | # A Block pool of all kv-cache blocks. |
cached_block_hash_to_block 保存的数据结构是 {block_hash: {block ID: block}}
req_to_blocks 保存了 request到 block列表的映射关系,{request ID: [block ID]}
block的eviction的定义,eviction candidate == in free queue and ref_cnt == 0。
get_computed_blocks方法
根据request获取已经计算过(缓存过)的block,获取kv cache blocks的方式是通过block hash 从cached_block_hash_to_block寻找的。
hash的计算是之前的block hash加上当前token ids做一次hash,第一个block则没有父block只用当前自己的token ids做hash。
append_slots方法
会为需要新计算的token ids分配block(如果现有的block不够的话)。
Worker
GPUModelRunner
v1/worker中的gpu_runner.pyv1版本的实现。
首先依赖一个大的config参数vllm_config,包含了model_config,cache_config,scheduler_config,device_config等。
初始化kv cache的dtype,对照表如下,half就是fp16,float就是fp32,默认是和模型的dtype一样。
1 | STR_DTYPE_TO_TORCH_DTYPE = { |
初始化sliding_window的配置,这个东西在Qwen里面才用到。
初始化block_size,决定了kv cache中连续保存的token的数量,也就是PagedAttention中的那个block的大小,Prefix cache也是以block为维度的。
初始化kv_heads,这个决定了kv head的数量,如果指定了 tensor_parallel_size,会根据这个参数平均分给每个GPU。
初始化head_size,基于model config,是model config里面的head_dim。
初始化hidden_size,就是model config里面的hidden_size,就是d_model或者embed_dim,代表同一个长度。
初始化kv_cache。
初始化encoder_cache encoder结果的缓存。
初始化input_registry 和多模态的支持有关系。
初始化requests dict用于request的状态保存,这里的request就是一个文本的sequence。
初始化InputBatch,max_num_seq决定了batch的宽度,max_model_len决定了batch的长度。这个Batch对象负责管理在用于前向传播的batch当中的request的插入和删除。
初始化use_cuda_graph 这个由 enforce_eager 决定,默认是会加载整个计算图。
初始化positions: torch.zeros(self.max_num_tokens, dtype=torch.int64, device=self.device)。
初始化input_embeds,可以看到,宽度是max_num_tokens,长度是hidden_size,这个是用来存储输入的embedding的。
1 | self.inputs_embeds = torch.zeros( |
InputBatch
InputBatch在整个工程中负责管理和处理批量输入请求,确保请求的高效处理和管理。
execute_model 方法
execute_model是整个schedule | compute | update循环中的核心部分,负责执行模型的前向传播。
_update_states方法
在每次运行一个 batch 时,会根据调度器(scheduler)的要求调整每个 batch 中请求的优先级。调度器会更新请求的状态缓存 id -> CachedRequestState 和 input_batch 的缓存,移除被抢占和停止的请求,并将新加入的请求放入 batch 中。因此,runner 只负责执行,具体的策略由调度器决定。
CachedRequestState 记录了请求 ID、使用的缓存块 ID 以及已计算的 token 数量。
_excute_encoder方法
执行多模态中的encoder,对于新的多模态的encode,调用model.process_mm_inputs存入到encoder_cache当中。
self.model.compute_logits使用vllm/model_executor/layers/logits_processor.py中的LogitsProcessor,从hidden_states计算logits。
self.model.sample使用vllm/model_executor/layers/sampler.py中的sampler进行sample。
最终得到sampled_token_ids = sampler_output.sampled_token_ids。
_gather_encoder_outputs 方法
从encoder_cache中获取当前batch需要用到的encoder的输出。
_prepare_inputs方法
input_batch.block_table 在 GPU 上,而 input_batch.block_table_cpu_tensor 在 CPU 上。
前面提到 batch 的整理是在 CPU 上进行的,这里是将要推理的部分拷贝到 GPU 上的 block_table 中。由于使用了 PagedAttention,因此所有的序列都是按 block 为粒度进行切分的。
获取input_ids,构造出传给FlashAttention的数据,例如block_table,和query_start_loc和seq_start_loc用于定位query和seq的位置。
input_ids, attn_metadata, logits_indices
_prepare_sampling方法
构造出sampling的参数,获取每个request的temperature,top_k,top_p等参数。
GPUWorker
v1/worker中的gpu_worker.pyv1版本的实现。
初始化GPUModelRunner,如果开始了VLLM_TORCH_PROFILER_DIR就会调用torch.profiler.profile。
determine_num_available_blocks会通过profile的方式决定可以使用的block数量。
然后根据block数量调用Runner的initialize_kv_cache。
做一些GPU的dtype支持检查,比如一些老的GPU是不支持bf16的。
FlashAttentionMetadata 包含了input的结构和对应的block table的映射。