vLLM 分析 3 推理优化
这篇文章主要基于vLLM中做推理的优化做一个总结。
PagedAttention
从原始论文来看,显存的浪费主要有几种。
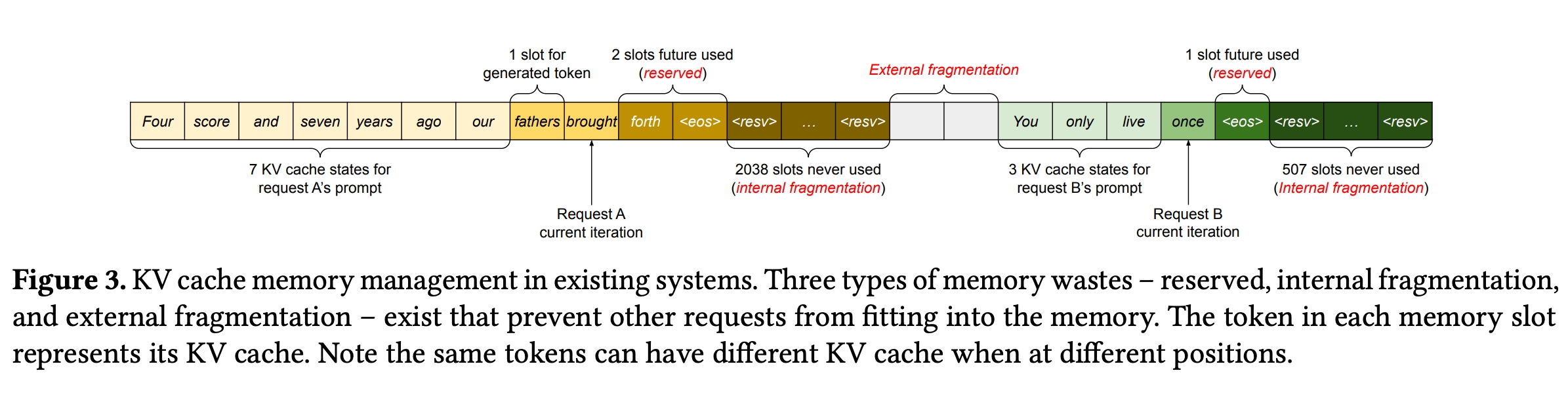
这张图里面表示的是每个token对应的kvcache的slot。对于一个context长度中用不到的slots部分,有预留的slots和不同空隙之间的slots空隙。
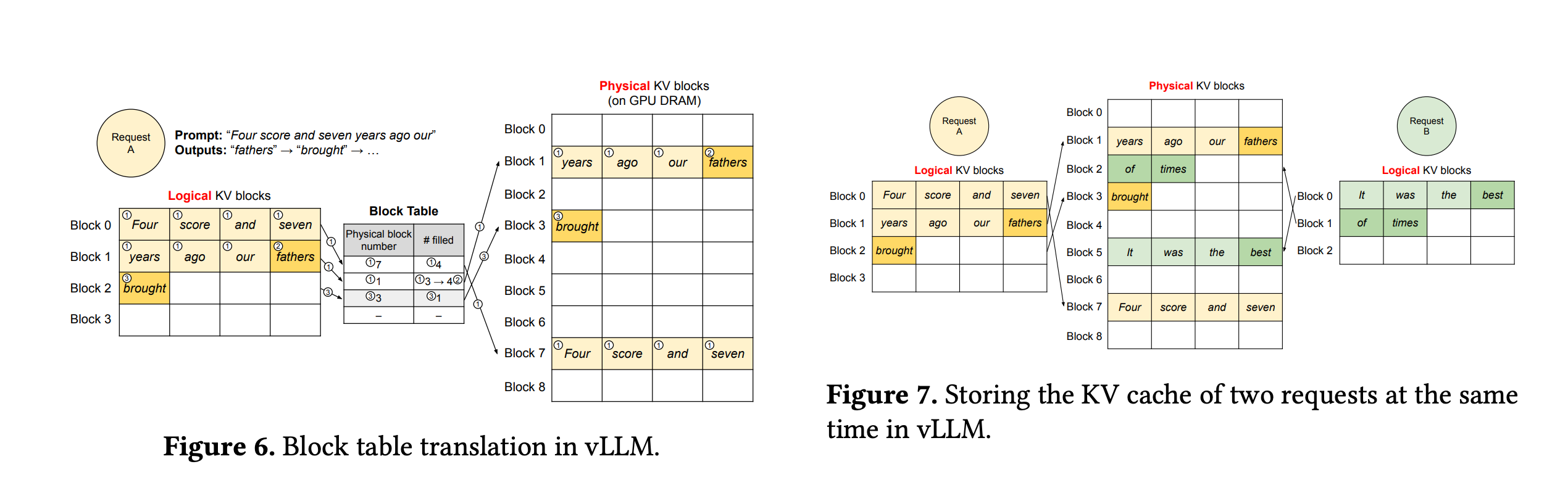
vLLM参考了虚拟内存和内存页分配的逻辑构造了一个block table用于 kv cache block slots 和 token之间的关系。通过block表的管理
可以像操作系统一下减少内存碎片。
因为不同的sequence中token是有位置信息的,所有他们对应的kv slot也不一定一样。下图展示了他们的关系。
Continuous Batching
“连续批量处理”(Continuous Batching),也称为”动态批量处理”(Dynamic Batching)或”迭代级调度批量处理”(Batching with Iteration-Level Scheduling),是一种选择Batch行的技术,用于优化计算和资源利用率。
它的主要区别在于与静态批处理相比,它会在每次推理迭代过程中动态调整Batch中的序列,例如vLLM会抢占部分序列,将序列的prefill阶段和decode阶段分开,不在同一个batch中处理。
而HuggingFace的text-generation-inference的router文档中提到的:为了提高效率,特别是在文本生成和内存受限的LLM上,可以让客户端发送单个查询,然后路由器将这些查询合并或分离成批次,以最大限度地利用计算资源。这是因为在LLM中,运行模型的计算成本远远高于批处理的成本。当新请求到达时,当前正在forward的前向传播不中断,而是继续等待执行完毕。然后将当前正在处理的请求与新到的请求合并成一个批处理请求,再进行forward前向传播。在批处理请求中,任何一个请求完成(即模型产生了终止符或达到允许的最大长度),则从批处理请求中移除该请求,并释放相关资源。这种方法可以应用于多个请求,并且支持在不同参数下的处理(例如采样、不采样、温度控制等),因为每个请求在批处理中都可以独立进行处理。Anyscale 对这个过程有很好的解释。
Prefill 和 Decode
在LLM推理过程中,一个Prompt的第一次执行(称为prefill)和后续的前向传播(称为decode)是不同的。Prefill阶段需要计算整个注意力矩阵并将其缓存到KV缓存中,计算规模较大,尤其是对于长度为10K或100K的提示词。而在decode阶段,只需计算新生成的token的注意力矩阵,计算规模较小。
从Kimi的Mooncake论文中的图片来看:
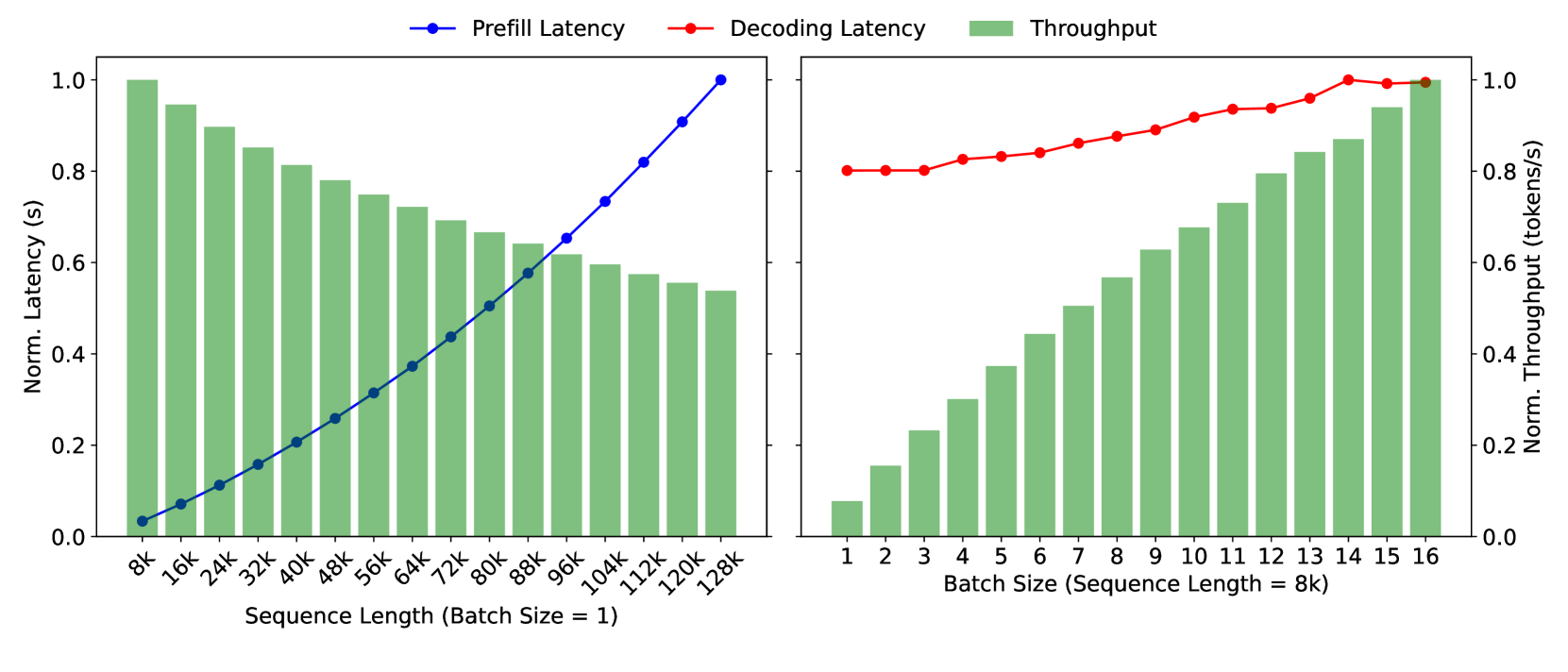
左图显示,当prompt长度增加时,计算时间呈平方级别增加。右图显示,decode阶段只生成一个token,计算规模比线性增长还要慢一点,但由于需要复用之前的KV缓存,因此显存开销较大。Mooncake的解决方案是将prefill和decode分开处理,prefill计算规模大,decode计算规模小,通过KV缓存共享机制传递KV缓存。论文还提到了一些关于缓存调度的细节,这里不再展开。
在Prefill阶段,所有的提示词(prompt)都是已知的,因此可以并行计算多个token,计算并行度较高。而在Decode阶段,只需根据新生成的token计算下一个token(之前的KV缓存已经保存了中间结果),因此计算规模较小。如果将Prefill和Decode放在同一个batch中计算,由于计算规模不对等,容易产生计算空隙(bubble)。
Prefill像是一个矩阵和矩阵的乘法,而Decode则是一个向量和矩阵的乘法。
Chunked Prefill
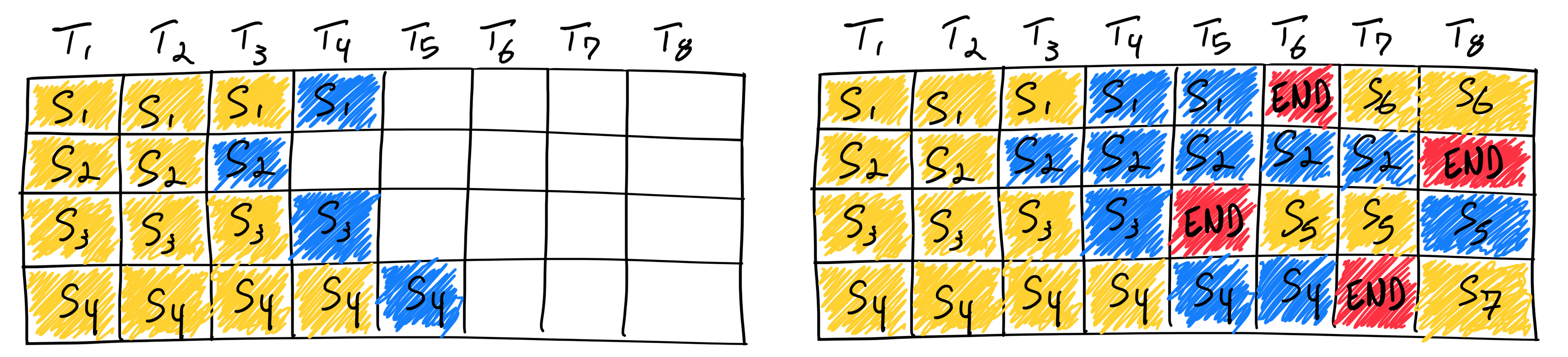
vLLM的文档很好的解释了prefill阶段和decode阶段的区别。
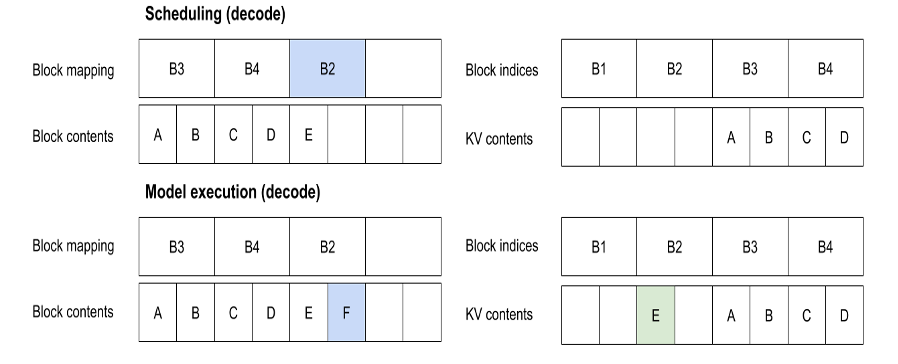
考虑到vLLM进行生成的序列“ABC”。当它到达时,KV缓存基于block size的预设值(这里是2)在内存中分配对应的block(B1,B2,B3,B4),但它是空的。
我们知道序列的内容(A,B,C),但我们没有token id到块索引的映射。

考虑到这种情况,下一步是为序列ABC进行prefill。在调度过程中,我们为序列中每个token块分配块索引(B3,B4),即([A, B], [C, _])。

一旦确定了块映射,我们就可以通过运行模型的前向传播。这会将ABC token的KV激活值写入KV缓存中的相应位置。此外,前向传播将导致新token “D” 被采样。D的KV值尚未知晓。

现在,序列已经完成了预填充。我们可以安排一个解码步骤。这涉及为新token “D” 分配块映射。然而,由于它适合现有的块映射,调度器不需要分配新的映射。

然后我们再次运行模型,计算并将“D”的KV写入KV缓存。这会生成一个新的token “E”。

这个过程会重复进行直到解码完成。请注意,后续的分配可能是不连续的。
Speculative Decoding
Speculative Decoding利用小型、快速的草案(draft)模型生成初始token(token是输入信息的基本单元)时的高效性,而在验证阶段则依赖更大的、更准确的大型语言模型(LLM)进行验证。
这个过程可以分为两步:
- 初始token生成:使用小型、快速的草案模型生成初始token。这一步骤快速生成token序列,使得下一步骤可以快速开始。
- 验证:使用更大的、更准确的LLM对初始token进行验证。这一步骤确保生成的token序列是准确的和有效的。
这种技术通过将任务分成两个阶段来实现高效性和准确性:快速生成初始token,然后验证这些token以确保准确性。
其实现方式如下:
- 使用小模型进行多次decode,生成多个token序列。
- 将这些token序列传递给大模型进行验证。大模型会生成对应的logits,形状为
(batch, sequence, vocab_size),并进行softmax处理。 - 对于单步decode,logits的形状为
(batch, 1, vocab_size),其中的1表示最后一个token,在词汇表(vocab_size)上的概率分布。
例如,将小模型生成的”abcd” token序列传递给大模型,得到”ABCD”的logits。A对应的是用于预测B的概率分布,在这个序列中就是预测第二个token的概率分布。将b对应的token id在A的vocab_size长度的log prob中的值取出,对应的可能是B token id的概率,也可能不是。
1 | a | b | c | d |
最后,将b、c、d在大模型中对应的logits prob求和并取平均值。如果这个值大于一个阈值,就认为这个token是合理的,否则就拒绝。
这种方法通过结合小模型的快速生成能力和大模型的高准确性,实现了高效且准确的token生成过程。
根据论文[https://arxiv.org/pdf/2406.14066]来说,在continus batching的情况下,Speculative Decoding可以提高推理速度,减少计算资源的浪费。
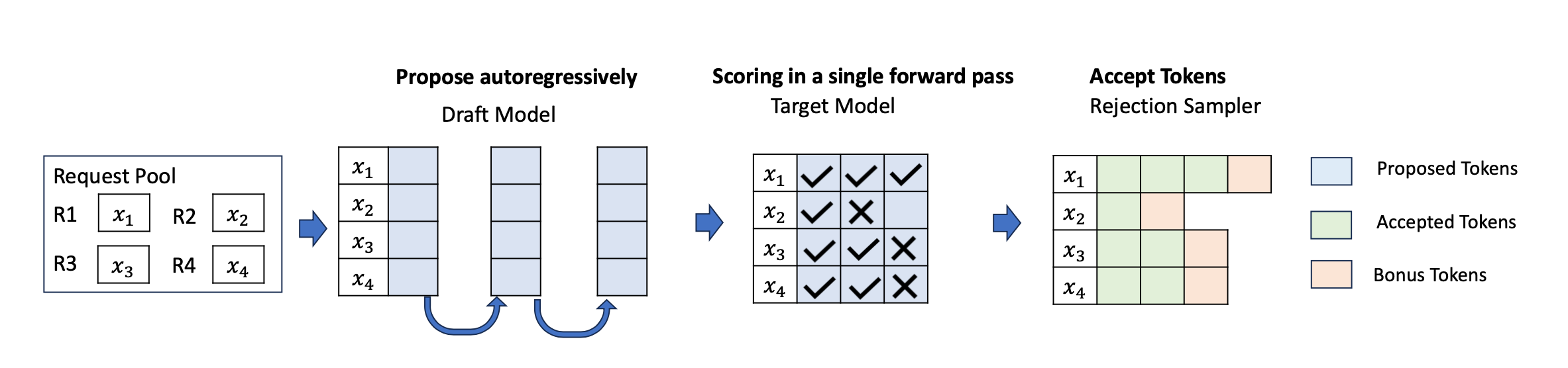
在Target模型验证完以后,还会多生成一个bonus token,也就是上面的那个D。
其中Decoding也产生了很多的方法,有基于模型的,也有model free的,才用大模型的一部分,或者直接从外部数据库来获取。
结果表明,在低请求率下(具体来说,请求率为 4),提出 3 个或 5 个令牌会带来最显著的加速。然而,随着请求率的增加,提出更多令牌的优势迅速减弱:当请求率超过 12 时,提出 5 个令牌不再带来性能提升。同样,在请求率大于 16 时,提出 3 个令牌会导致性能下降。
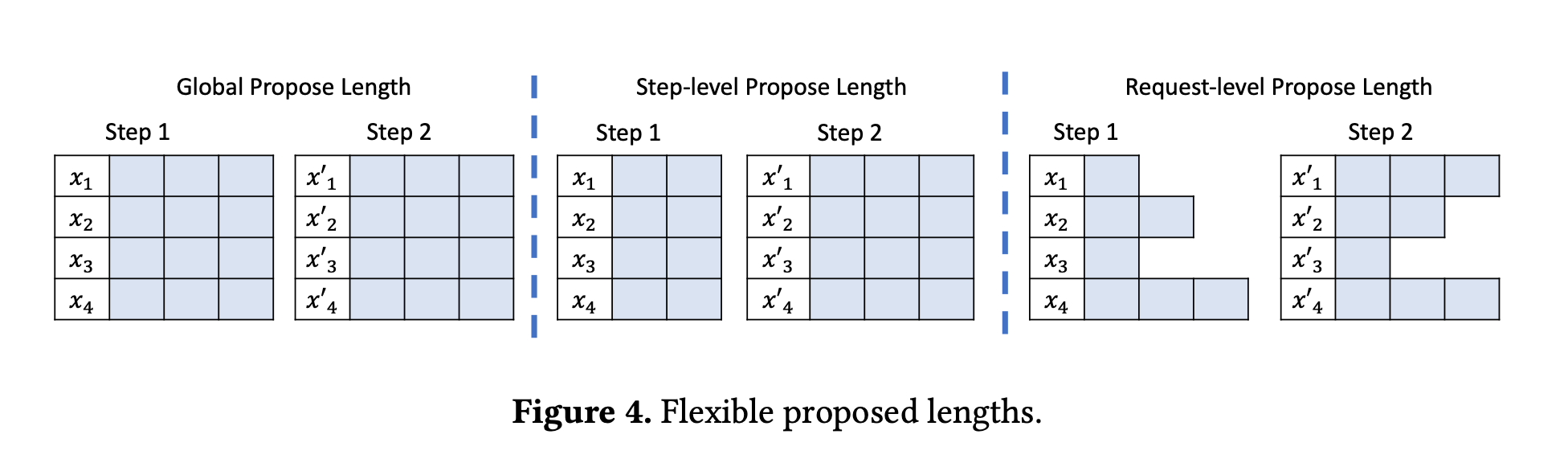
其中不同的颗粒度的猜测长度也会对性能有影响。
全局统一的长度;每个step所有request用一个长度;每个step每个request用不同的长度。
相较于吞吐,Goodput规定只有没被拒绝的token才计算,用来衡量最总的性能。
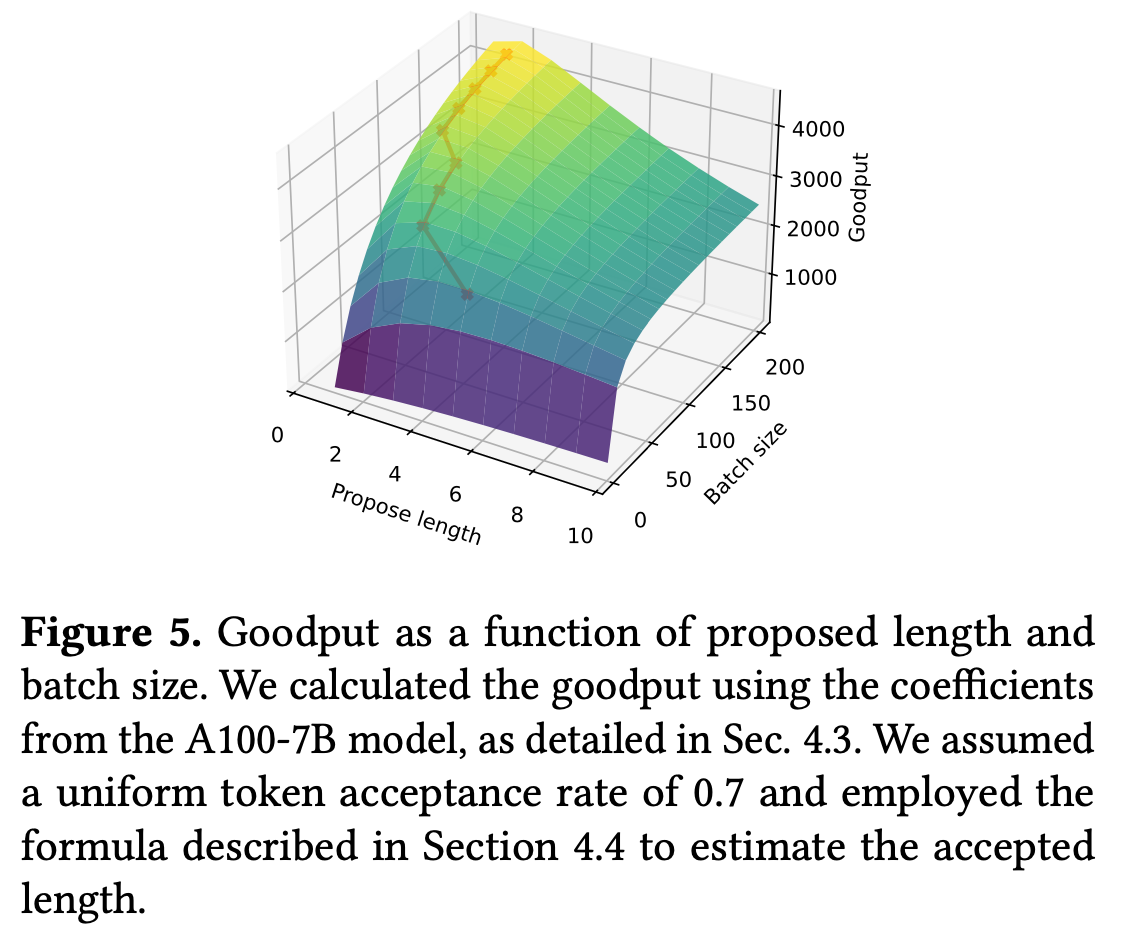
这张图展示了猜测长度和batch size对于Goodput的影响。
对于小批次,要多猜测(propose),小批次尺寸下每次请求需提议超 4 个 token 以实现最大有效吞吐量(goodput),且随着批次尺寸增大,最优猜测长度会降低;
对于大批次,则要少猜测,甚至不进行推测反而能获得更高有效吞吐量,因为大批次下推测失败成本显著增加,超过潜在收益。
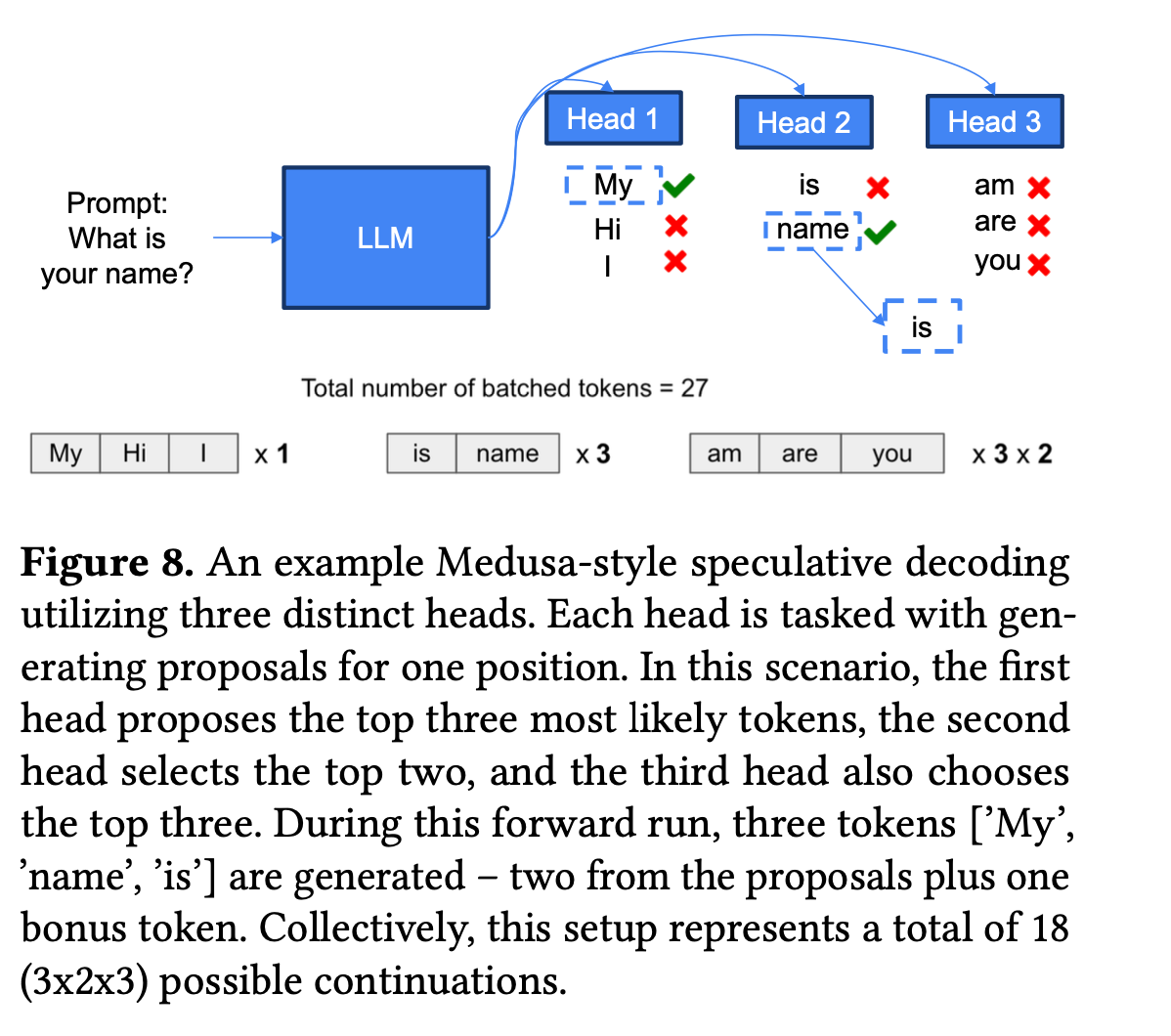
除了朴素的猜测模型,里面也提到了Medusa风格的猜测模型。预测3个token就有三个head分别预测每个位置。
里面的例子head 1猜了三个,对了1个,head 2猜了2个对了一个,head3猜了3个全错了,然后加上LLM的bonus token。
SmartSpec 估算Goodput的方法就是根据成功率计算期望长度再乘上Request对应的时间。
然后根据不同的batch size计算Goodput,让Goodput最大化,得到最佳Goodput从而让吞吐最大化。
Automatic Prefix Caching
一般的LLM请求的提示词会非常长,据说OpenAI的系统提示词已经有几K了,这个规模很适合做前缀缓存。
前缀缓存是指将提示词分成多个前缀,然后将这些前缀缓存到KV缓存中,这样在生成token的时候就可以直接使用KV缓存中的值,
而不需要重新计算。这样可以减少计算量,提高推理速度。
当然在vLLM中kv cache是分块的,所以prefix 也是分块的。
1 | Block 1 Block 2 Block 3 |
Multi-LoRA Serving
VLLM当中的LoRA Adaptor是可以动态加载的,因为他本身和基座模型保持独立。
这里要注意的一个点是,如果词汇表修改了,会影响最后的llm head,比如英文基座模型用中文词汇表,那么 vocab_size 就不一样了。
会导致llm head的输出维度不一样,这个时候就需要重新训练llm head。
所以要注意最后的llm head的输出维度。
Tensor Parallelism
张量并行(Tensor Parallelism)是一种将大型模型的计算任务分解到多个GPU上并行执行的技术。它通过将模型的权重矩阵切分成多个子矩阵,并将这些子矩阵分配到不同的GPU上进行计算,从而实现并行计算。
在Transformer模型中,QKV(Query, Key, Value)矩阵乘法是计算量最大的部分之一。通过将QKV矩阵切分成更小的子矩阵,并将这些子矩阵分配到不同的GPU上,可以显著提高计算效率。
例如,对于一个具有d_model维度的QKV矩阵,可以将其切分成n个子矩阵,每个子矩阵的维度为d_model / n。然后,将这些子矩阵分配到n个GPU上进行并行计算。这样,每个GPU只需要计算一个较小的子矩阵,从而减少了计算时间。
张量并行的实现方式如下:
- 切分权重矩阵:将模型的权重矩阵切分成多个子矩阵。例如,对于一个
d_model x d_model的权重矩阵,可以将其切分成n个d_model x (d_model / n)的子矩阵。 - 分配子矩阵:将切分后的子矩阵分配到不同的GPU上。例如,将第一个子矩阵分配到GPU 0,第二个子矩阵分配到GPU 1,以此类推。
- 并行计算:在每个GPU上并行执行矩阵乘法计算。例如,在GPU 0上计算输入矩阵与第一个子矩阵的乘积,在GPU 1上计算输入矩阵与第二个子矩阵的乘积,以此类推。
- 聚合结果:将所有GPU上的计算结果聚合起来,得到最终的输出。例如,将所有子矩阵的乘积结果相加,得到最终的QKV矩阵乘积结果。
通过张量并行,可以显著提高大型模型的计算效率,减少推理时间,从而提高模型的推理速度和性能。
Pipeline Parallelism
Pipeline Parallelism通过将模型的不同层分配到不同的GPU上来实现并行计算,特别是一些大型模型。这种方法可以提高计算效率,但也会引入一些挑战,例如在层之间传递数据时可能会产生延迟。此外,由于不同层的计算时间可能不一致,可能会导致某些GPU在等待其他GPU完成计算时处于空闲状态,从而产生计算空隙(bubble)。
为了减少这些计算空隙,可以使用Chunked Prefill技术。Chunked Prefill通过将计算任务分成更小的块,从而缩短每个计算任务的时间。这使得在流水线并行中可以更灵活地安排计算任务,从而尽可能地填满计算空隙,提高整体计算效率。
通过结合Pipeline Parallelism和Chunked Prefill,可以在保持高效计算的同时,最大限度地利用计算资源,减少计算空隙,提高模型推理的速度和效率。
在vLLM当中 TP=n 且 PP=m 时,vLLM 引擎总共会有 n*m + 1 个进程。即使使用单个 GPU,我们也会有 2 个进程。
衡量LLM的服务指标
在衡量LLM服务性能时,Token相关的数据是一个重要的方面。以下是一些常见的Token相关指标:
Token Throughput
Token Throughput表示每秒生成的token数量。它是衡量模型生成速度的一个重要指标,通常以tokens per minute (TPM)为单位。
Token Latency
Token Latency表示生成一个token所需的时间。它是衡量模型响应速度的一个重要指标,通常以毫秒(ms)为单位。Token Latency包括以下几个子指标:
- **TTFT (Time To First Token)**:从请求到第一个token生成的时间。例如,当prompt变长时,TTFT会变长;或者当kv cache不足时被抢占,TTFT也会变长。
- **TBT (Time Between Tokens)**:生成两个token之间的时间。例如,当batch size变大时,TBT会变大。