Mooncacke分析
LLM推理的核心在于KVCache的调度。
- 尽可能多次重用KV缓存,以减少所需的计算资源;
- 每批次最大化token数量,从而改善Model FLOPs Utilization (MFU)。
如果从远程内存获取KVCache,会增加数据传输时间,从而延长TTFT(Time To First Token)。因此,当本地KVCache的增量计算时间少于传输时间时,可以复用本地的KVCache,即使它不是最匹配的。而增大batch意味着系统处理的大批量数据,导致TBT(Token Between Token)延长,可以将负载均衡到低负载的Decode Instance。
架构
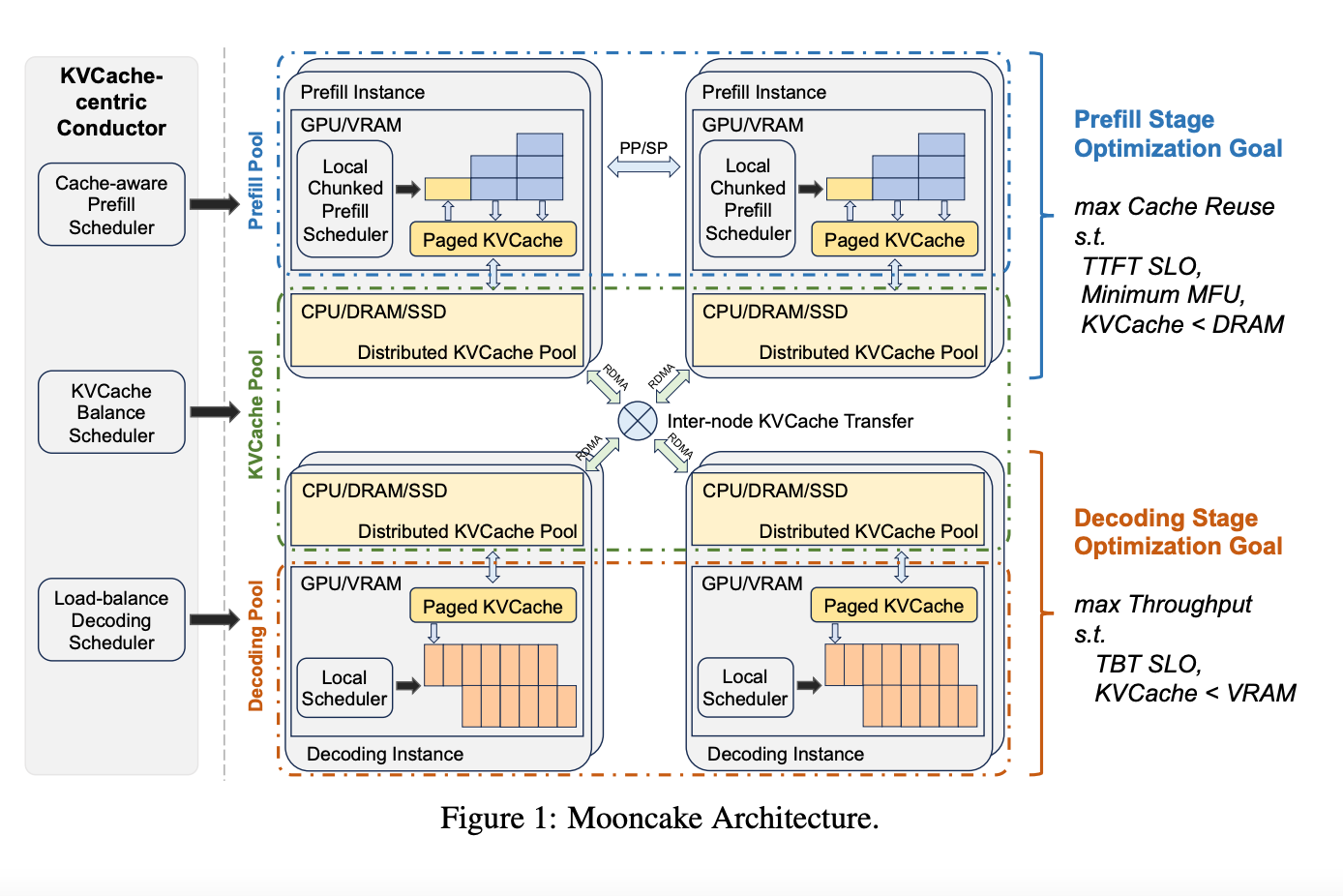
Mooncake的架构图主要分为三个部分:Prefill Instance,Decode Instance,Conductor。
- Cache-aware Prefill Scheduler:负责调度Request到Prefill Instance,主要考虑load和KVCache的复用率。
- KVCache Balance Scheduler:负责从匹配最多前缀的P2P传输KVCache到Instance(Decode和Prefill)。
- Load-balance Decoding Scheduler:负责负载均衡调度Request到Decode Instance。
Prefill Instance要满足TTFT SLO,最小化MFU,保证KVCache < DRAM。
Decode Instance要满足TBT SLO,保证KVCache < VRAM。
Inter-Node Transfer基于RDMA的P2P,这也是一个较大的开销。
Mooncake的方法总结如下:
- 转移可重用的KVCache,将尽可能多的可重用KVCache转移至Prefill Instance,减少增量计算的时间。
- Prefill Instance Pool分层并分块处理,并持续输出给对应的Decode Instance。分层指的是Layer-wise KVCache的异步保存,分块指的是Chunked Pipeline Parallelism。
- 独立的Decode Instance Pool加载KVCache,通过连续批处理解码tokens。
Mooncake的主要特点是将prefill和decode拆开,并调度KVCache块。
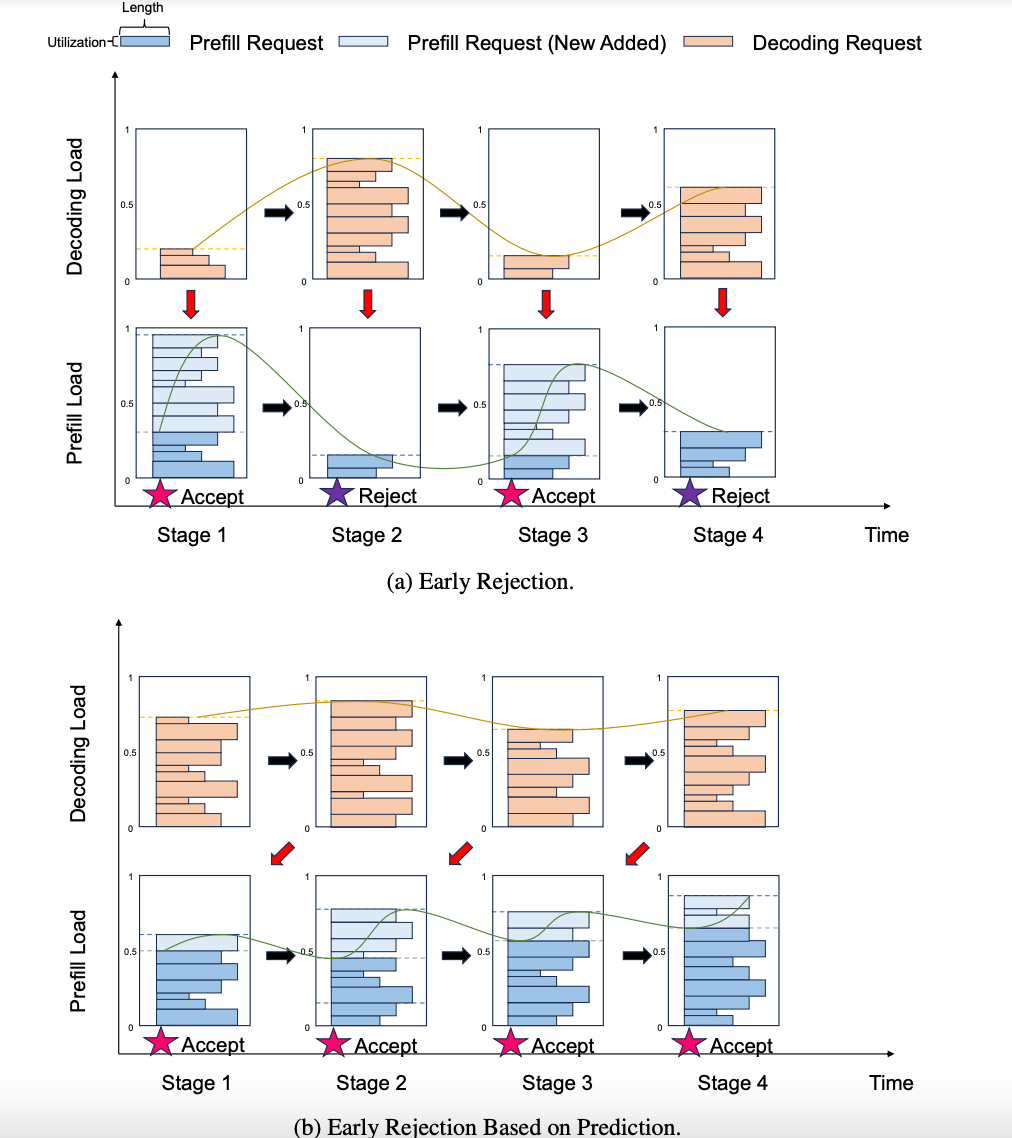
Reject Policy:如果一个请求不能在服务水平内完成其完整的执行,那么就应该尽早拒绝这个请求,基于这个理念需要设计一些拒绝策略,被称作Overloaded-Scheduling。
KVCache的复制
KVCache的调度主要是利用KV Cache(VRAM,DRAM),利用RDMA带宽。
下图是一个Prefill和Decode分离的计算过程。
如果了解vLLM中的prefill和decode以及管理block的方法,这个图其实很简单。
首先通过Hash判断block是否相同,例如很多系统提示词都是一样的,这部分的复用率很高。
Prefill Instance已经有了ABCDE(这里是一个P2P的过程,但我看开源的版本有个KVCache Store的WIP,不知道后面会不会有一个中心化的KVCache Store的组件)。然后计算了FGHI,存入了KV Cache(在CPU mem上),论文里面提到这个prefill在超过prefill_chunk tokens数量会做chunked prefill。
接着通过Messenger以RDMA的方式发给Decode Instance。Decode Instance基于ABCDEFGHI的prompt对应的KV Cache开始decode的过程。
根据请求模式,它可以使用缓存淘汰算法,如LRU(最近最少使用),LFU(最不常用的),或基于请求特征的算法。这些KVCache块在CPU和GPU之间的传输由一个独立的(GPUDirect)RDMA组件Messenger处理。这种架构还使我们能够为外部用户提供KVCache缓存API,从而实现更高的缓存重用性。
Mooncake已经开源了他的代码,目前只有Transfer Engine。
基于这个架构,Conductor的主要功能是:
- 根据当前的KVCache分布和工作负载,分发请求。
- 复制或交换某些KVCache块,以便于未来推理。如果某些块的数据在未来被频繁访问,Conductor可能会将其复制到其他节点上,从而提高推理效率。
Mooncake的一个争论点是,是否需要在存在chunked prefill的情况下采用这种分离架构。毕竟,chunked prefill可以填补许多pipeline中的气泡,并且能让prefill和decode节点相对统一,只需要关心一种instance,对于scheduler比较友好。
不分离的优点:
- 所有节点被视为平等,使调度更简单;
- 将chunked prefill内联到解码批处理中可以提高解码批次的计算强度,从而提高MFU。
分离的优点:
- 长文本的跨节点并行和VRAM的节省。长文本输入是输出的10倍甚至100倍,对于相同的模型来说,prefill需要多节点配置才能满足显存需求。prefill阶段可以进行layer-wise prefill,每次保存大量KVCache,而decode阶段每次只需保存一个KVCache。因此,prefill阶段可以通过layer-wise prefill来减少VRAM占用。
是这么理解么?异步的Store KVCache可以节省保存的时间,但这是Prefill和Decode分离的理由么?Decode阶段应该是不保存KVCache?
然而,经过仔细考虑,论文决定保持Mooncake的分离架构。只有在请求的prefill可以不进行chunking且不影响TBT SLO的情况下,才会将其内联到解码批次中。我们这样决定的主要原因有两个:
Prefill节点需要不同的跨节点并行设置来处理长上下文 (§5.1)。
这为节省VRAM提供了独特的机会 (§5.2)。
大模型需要部署在多机上,进行TP后,每一层都需要进行一次基于RDMA的reduce,这个过程开销巨大。虽然有一些Sequence Parallelism的方法,但效果并不理想,且无法避免跨节点通信。而Mooncake采用的是CPP(Chunked Parallelism Pipeline),将序列按
prefill_chunk大小切分,交给prefill pool的不同节点,这些节点被切分成更小的节点池(pipelined prefill node group)。
疑问:他们是pipe的不同部分?还是完全对等的?目前感觉是PP是分layer做Pipe,而CPP是sequence分chunked做pipe。24引用的论文中提到的Sequence Pipeline可以再看一下,应该对理解这个有帮助。
- Layer-wise prefill,这有点像airllm项目,在计算过程中动态加载KVCache。在每次注意力计算时,KVCache是异步加载的,计算当前层时可以异步加载下一层,并且当前层结束后可以异步保存当前层。论文中认为KVCache的保存时间可以被完全省略(相较于加载计算保存的线性循环)。这样也可以降低VRAM的占用。
调度算法
选择Prefill实例:
- 如果Prefill节点上缓存了足够的前缀(由
kvcache_balancing_threshold控制),则选择预估TTFT最小的实例:TTFT = min(T_queue + T_prefill)。 - 如果Prefill节点上缓存不足,则选择
TTFT = min(T_queue + T_prefill + T_transfer)最小的实例,其中T_transfer指的是有最长匹配的KVCache的实例拷贝到当前实例的预估时间。
- 如果Prefill节点上缓存了足够的前缀(由
选择Decode实例:
- 通过负载均衡的方式预估TBT。
- 如果TBT和TTFT不满足SLO,则拒绝请求,并触发KVCache的传输。
预测模型:
- 预估模型用于预测传输时间和决策传输。
- 数据传输时间难以预测,因为它不仅取决于数据大小,还依赖于当前网络状态,特别是当发送节点处于拥塞状态时。
KVCache复制:
- 热门的KVCache块需要被复制以确保高可用性。
调度器目标:
- 保证低Cache负载和高Cache命中率。
高负载情况下的策略:
- 请求可能不会被直接发送给缓存最长前缀的实例,而是转发给备选实例。备选实例会主动从缓存持有者处检索KV缓存并存储本地。
- 当最佳的远程前缀匹配长度不超过当前本地可重用前缀的阈值时,系统优先使用本地缓存,而不是从远程实例获取令牌。
这些策略不仅减少了请求的Prefill时间,还自动复制热点缓存,使其在多台机器上更广泛地分布。
拒绝策略
论文提到了一种基于预测的拒绝策略。Prefill和Decode的负载节奏是相反的,可能在Decode负载高时,Prefill负载较低。此时如果拒绝请求,会导致Decode负载下降,而Prefill完成后Decode负载又会升高,进而再次拒绝请求。引入预测拒绝策略后,可以使Prefill过程更加平滑,减少频繁拒绝请求的情况,从而减小负载节奏的波动。