CacheBlend分析
CacheBlend的主要目标是在一些RAG场景下,多个文档Chunk之间不能像多轮对话那样构成Prefix Cache。
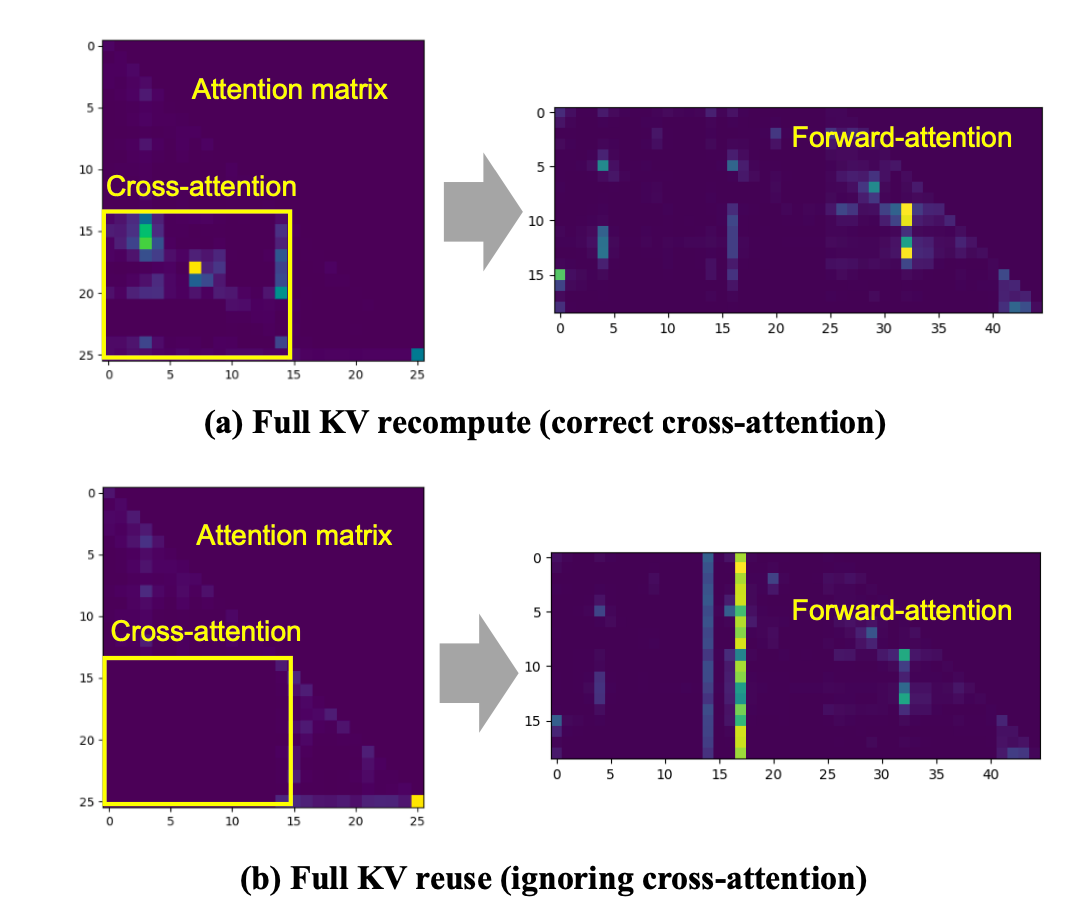
对于位置编码来说,RoPE得到的注意力是绝对位置无关的,所以两个下三角放到对应的位置就可以。但是,两个Chunk之间的交叉注意力机制实际上是空的,如果单纯这样使用会丢失交叉注意力的信息。
论文中提到了一个例子。
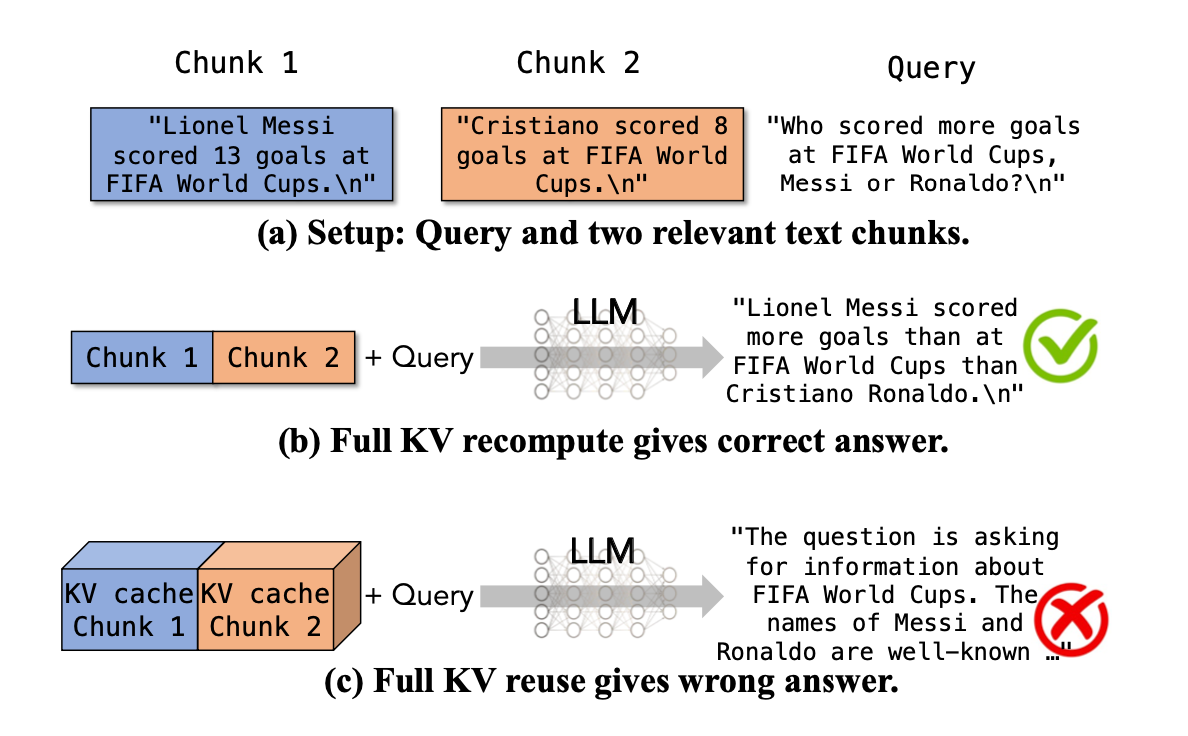
在比较两个球员进球数的场景中,就损失了球员之间的交叉信息。
为了弥补下面那个空的矩形的注意力,同时尽量节省计算量,根据一些insights提出了一种选择性计算的方法。
注意力矩阵是稀疏的,其中差异较大(颜色较深)的部分对最终结果贡献较大。另外,对于多层的Transformer,前几层的注意力差异往往会一直保持下去。因此,CacheBlend会完全重算第一层的注意力,然后标记差值较大的token,用它们的注意力来代表两个Chunk之间的完全注意力矩阵。当然,这还是有损的。
其中的权衡在于选择多少比例的token来代表两个Chunk之间的注意力矩阵,这个比例是可以调整的。
一个平衡点在于从异构存储中加载KVCache和重计算KVCache的时间。如果选择性计算token的时间大于加载的时间,则可以将这个过程流水线化。在计算当前层时,加载下一层的KVCache。
比率r%刚好满足计算时间和加载时间相等。
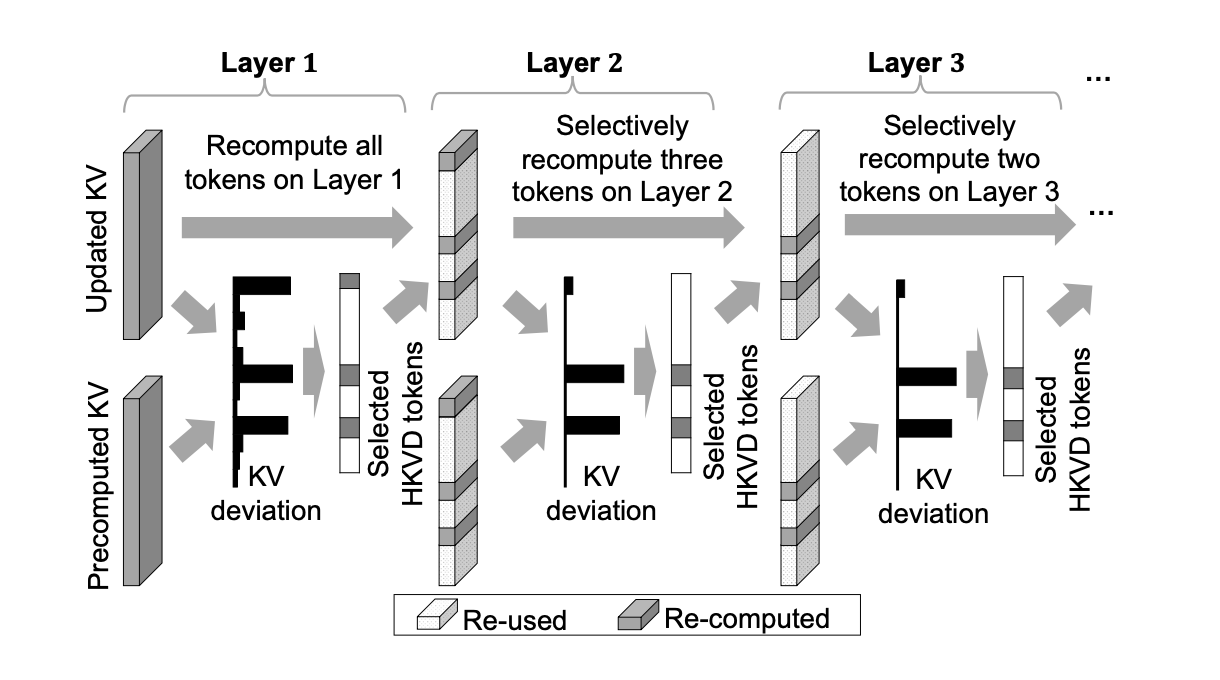
尽管第一层高差异化的token的注意力比较重要,但只看第一层似乎不太合理。CacheBlend会用一个比r%更大的范围选择token,然后每一层逐渐递减r%,以容许更多的可能性。只从第一层选择r%可能会丢失一些重要信息。
总体来说,利用交叉注意力的稀疏性选择性重计算Chunk之间的交叉注意力,并平衡加载和计算,使得计算过程和加载是并行的,时间损耗无影响。在精度上,选择一个较大的r%再每层缩小到理想r%来满足准确性。最终实验效果显示,与完全重算的交叉注意力相比,结果还是很接近的。