xattention稀疏注意力的计算方法
本文讨论了稀疏注意力的计算方法,其核心思想是通过选择矩阵的分块,将重要的矩阵挑选出来参与计算。这是因为注意力矩阵具有稀疏性,而如何选择这些重点矩阵是各类算法需要解决的主要问题。
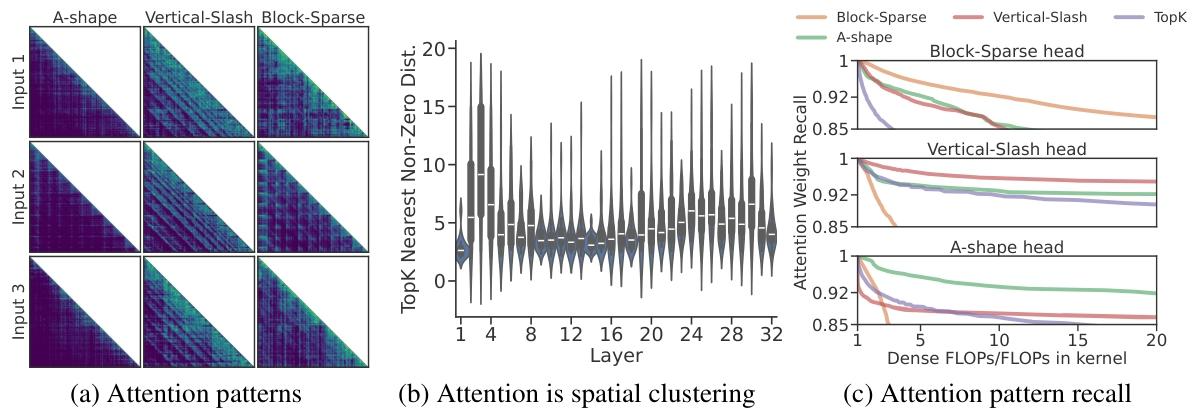
稀疏性模式总结
MInference 总结了三种稀疏性模式,这些模式具有动态特性,分别是:
- A-shape:注意力集中在初始词元及其相近词元上。
- Vertical-Slash:注意力集中在一些重点词元及其相近词元上。
- Block-Sparse:注意力具有明显的分块特性。
以下是稀疏性模式的示意图:
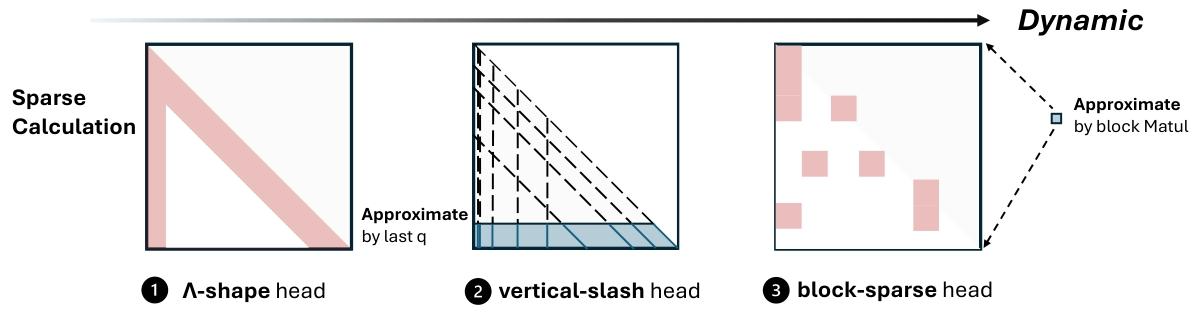
稀疏性的动态性从左到右逐渐增强:
MInference 算法
MInference 使用最后 64 个 Q 进行计算,选出 top-k 的垂线和斜线作为重点块的索引。对于 Block-Sparse 模式,使用 mean pool 方法选出 top-k。
FlexPrefill 算法
FlexPrefill 同样使用最后的 64 个 Q 进行 query-aware index selection,计算 QK^T 的 pool。通过 Jensen-Shannon divergence 计算分布距离,如果距离不满足条件,则回退到匹配垂线和斜线模式。
Xattention 算法
Xattention 采用分块和反斜对角线的形式选择块的索引。与仅使用最后一块 Q 进行选择的方式相比,Xattention 允许所有词元参与计算,不依赖垂线和斜线模式的连续性。
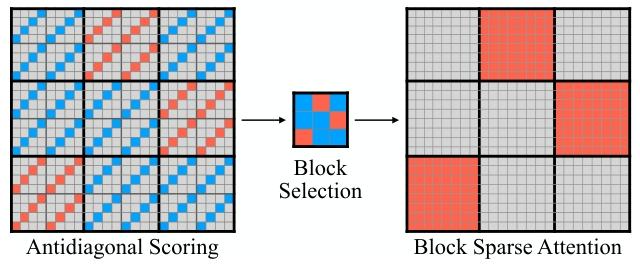
反斜对角线的构造
首先对矩阵进行分块,并按 stride 构造反斜对角线。与其说是反斜对角线,更像是一种形似反斜对角线的纹理构造方式:
反斜对角线的优势在于,它可以与垂线和斜线交叉,从而让相关词元参与计算:
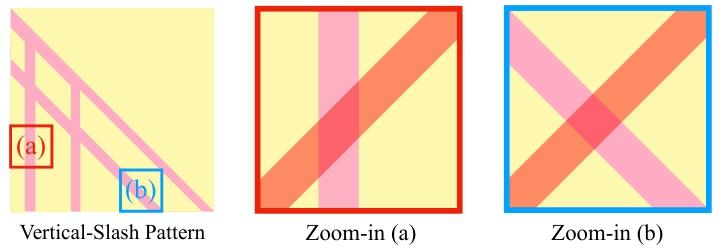
选择方式就是通过纹理匹配到的词元注意力进行求和,根据求和结果选择重要矩阵。