前言 在现代数据驱动的世界中,对高效且可扩展的数据存储方案的需求前所未有地强烈。键值数据库因其简洁性和卓越性能而备受推崇。对于那些热爱Rust编程并希望构建自己的键值数据库的开发者来说,这本书将是您的理想起点。笔者将引导您一步一步,从零开始,使用Rust设计和实现一个键值数据库。
数据库领域既神秘又充满魅力。正如俗话所说,不亲手实践,就无法深刻理解。通过构建一个键值数据库,我们不仅能深入掌握这类数据库的设计哲学和实现细节,还能借此机会深化对Rust语言的理解和应用。
本书内容围绕一个基于LSM(Log-Structured Merge-tree)的键值数据库设计和实现展开,参考了LevelDB、RocksDB、PebbleDB、AgateDB和BadgerDB等多个成熟数据库的实现。全书示例代码均使用Rust编写,旨在通过实战演练加深读者对Rust特性的理解,同时探索数据库技术的精髓。
LevelDB相较于其他衍生品,虽然没有一些新的论文和工程实践带来的优化,但保留了最初的设计,其相对简单和完整。其他数据库或多或少都能找到LevelDB的影子。
与《Rust编程语言》一书不同,本书不旨在覆盖Rust语言的所有知识点。我们的目标是实现一个键值数据库,因此读者需要具备一定的系统编程基础,例如文件系统相关的读写调用和指针的使用(不仅在unsafe的情况下,有指针的基础也方便理解引用等概念)。这些知识点如果完全讲解清楚会占据很大的篇幅。本书将解释使用到的Rust语法和特性。即使您没有阅读过《Rust编程语言》,也能跟随本书学习Rust的语法。如果您在阅读本书的Rust语法部分遇到困难,可以参考《Rust编程语言》中的相关章节。笔者也是将《Rust编程语言》作为一本参考书反复阅读,并不需要一次性完全读完,书都是常看常新的。
Rust的设计初衷是确保内存安全,避免常见的程序错误,如空指针解引用。其显著特点包括独特的所有权系统、零成本抽象、可靠的错误处理机制以及完善的工具链,使其在系统编程领域尤为突出。
尽管LevelDB是用C++编写的,Rust在某些方面被视为C++的现代替代品。对于那些对C++有深入了解的开发者而言,转向学习Rust应该会相对轻松。然而,Rust提供了与C++不同的编程范式。例如,迭代器和闭包是Rust标准库和语法的一部分,作为语言的核心部分,引入了多种语法糖来支持这些功能,这可能会让熟悉Python的开发者感到亲切。
经典的内存错误包括使用已释放内存的指针、向量长度被修改但另一个引用仍保留原长度信息导致访问不确定内存地址等。Rust的所有权系统在编译阶段就能避免这些问题。
Rust借鉴了函数式编程的多种技巧,为开发者提供了一种既熟悉又新颖的编程体验,例如模式匹配、迭代器、闭包、泛型等。这些特性使得Rust在编写高效、安全和易维护的代码方面具有独特优势。
与有GC的语言相比,Rust可能让使用者感到不适应,许多在其他语言中理所当然的写法在Rust中行不通。Rust对指针的可变性有明确限制,并且只允许存在一个可变引用。这种所有权的检查使编译器变得非常严格,在一定程度上增加了编程的复杂性。然而,这也是Rust的优势之一,它能够在编译阶段发现许多潜在的错误。
相比暴露指针的语言,Rust对内存的解引用有严格的检查。尽管所有权系统有时会让代码显得冗长,但Rust提供了许多有趣的语法和特性,如模式匹配、错误处理宏、默认返回末端表达式等,使得编写Rust代码既轻便又高效。
Rust的性能非常出色,部分Linux内核驱动和Windows安全模块已经采用Rust实现。AWS也在许多地方使用Rust,飞书客户端的一部分代码也使用了Rust,这在一定程度上证明了Rust在系统编程领域的优异表现。如果需要选择一种新语言开发消息队列、数据库、文件系统等软件,Rust是一个非常不错的选择。这也是本书使用Rust实现的原因之一,以展示Rust在这些方面的优势。
在错误处理方面,Rust采用?问号宏简化了传统的错误处理流程,相比Go语言中显式处理错误的if err != nil {}模式是一种进步。这种简洁的错误处理方式不仅提高了代码的可读性,也加速了开发过程。
这些特色贯穿本书始终,在随后的章节中,您将探索到Rust的更多有趣特性。
笔者是一名Rust初学者,里面的很多实现可能存在不正确的写法,欢迎指正。
本书面向的读者
希望通过具体项目深入学习Rust,特别是在键值数据库方面的开发者。
对键值数据库的设计和实现感兴趣的初学者,希望通过实践学习相关内容。
想了解LevelDB架构和实现细节的读者,可以选择性地跳过实现部分进行阅读。
如何阅读和使用代码 本书的第一章主要是讲基础概念例如一些基础的数据结构。第二章开始分部分讲解实现的细节。对于
第一章Rust 完整讲解Rust的内容将要消耗大量篇幅,也不是本书的目的。本章节主要介绍在实现过程中会会涉及的一些的语法和特性,让读者在阅读代码的时候没有过多障碍。
数据类型 Rust 是一种静态类型的编程语言,其数据类型可以分为两大类:原始类型(Primitive Types)和复合类型(Compound Types)。以下是 Rust 中常见的数据类型:
原始类型(Primitive Types)
整数类型(Integer Types) :表示整数。有符号整数包括 i8、i16、i32、i64、i128,无符号整数包括 u8、u16、u32、u64、u128。
1 2 let signed_integer : i32 = -42 ;let unsigned_integer : u64 = 42 ;
浮点数类型(Floating-Point Types) :表示小数。Rust 有两个浮点数类型:f32 和 f64。
1 2 let float32 : f32 = 3.14 ;let float64 : f64 = 3.14 ;
布尔类型(Boolean Type) :表示逻辑值,只有两个可能的值:true 和 false。
1 2 let is_true : bool = true ;let is_false : bool = false ;
字符类型(Character Type) :表示单个字符。字符类型使用单引号 '。
1 2 let char_a : char = 'a' ;let char_heart : char = '❤' ;
复合类型(Compound Types)
数组类型(Array Type) :表示固定大小的数组。数组中的所有元素必须拥有相同的数据类型。
1 let array : [i32 ; 5 ] = [1 , 2 , 3 , 4 , 5 ];
元组类型(Tuple Type) :表示具有不同数据类型的有序集合。元组的长度是固定的。
1 let tuple : (i32 , f64 , char ) = (42 , 3.14 , 'a' );
切片类型(Slice Type) :表示对数组或其他集合的引用,但没有固定大小。切片是一种动态大小的视图。
1 2 let array : [i32 ; 5 ] = [1 , 2 , 3 , 4 , 5 ];let slice : &[i32 ] = &array[1 ..4 ];
字符串类型(String Type) :表示动态可变的文本字符串。它由 String 类型表示。
1 let my_string : String = String ::from ("Hello, Rust!" );
引用类型(Reference Type) :表示对值的引用。引用在 Rust 中被广泛用于实现借用和所有权系统。
1 2 let original_value : i32 = 42 ;let reference : &i32 = &original_value;
这些数据类型提供了灵活性和安全性,通过所有权、借用和生命周期等概念,Rust 的类型系统确保了内存安全和线程安全。在编写 Rust 代码时,正确使用这些数据类型有助于减少运行时错误并提高代码的可维护性。
基本语法 let用于声明变量。
可以使用:显式指定变量类型:
_表示“存在但不关心”的变量,用于有意忽略某些处理:
1 2 3 4 let _ = 1 ;let _ = get_thing ();
以_开头的变量表示暂时忽略以避免编译检查,适合在开发过程中使用:
let可以“覆盖”变量,使之前相同名称的变量失效,且变量类型可以不同:
1 2 3 let x = 1 ;let x = 1 + 2 ;let x = "str" ;
Rust也有元组,相当于固定长度的“容器”可以容纳不同的类型,元组可以指定类型。
1 2 3 let pair : (char , i32 ) = ('a' , 17 );pair.0 ; pair.1 ;
元组适用于解构,下面的代码中some_char是'a',some_int是17。结构也可以使用_忽略全部或者其中一部分。解构也适用于函数的返回值。
1 2 3 4 let (some_char, some_int) = ('a' , 17 );let (_, some_int) = ('a' , 17 );let (_, _) = ('a' , 17 );let (left, right) = slice.split_at (middle);
{}可以划分作用域,如果使用之前的覆盖规则,可以在内部作用域覆盖外部作用域的变量。
1 2 3 4 5 6 7 8 9 10 11 fn main () { let x = "out" ; { let x = "in" ; println! ("{}" , x); } println! ("{}" , x); }
在Rust中,语块也是表达式。
1 2 3 let x = 42 ;let x = { 42 };
语块可以包含多个语句,最后一个不以分号结尾的语句是这个语块的值,否则默认等于()。
1 2 3 4 5 let x = { let y = 1 ; let z = 2 ; y + z };
函数中也有类似的写法。
1 2 3 4 5 6 7 fn fair_dice_roll () -> i32 { return 4 ; } fn fair_dice_roll () -> i32 { 4 }
if语句也是表达式。
1 2 3 4 5 6 7 fn fair_dice_roll () -> i32 { if feeling_lucky { 6 } else { 4 } }
match语句也是表达式。
1 2 3 4 5 6 fn fair_dice_roll () -> i32 { match feeling_lucky { true => 6 , false => 4 , } }
结构体是用 struct 关键字声明的:
1 2 3 4 struct Vec2 { x: f64 , y: f64 , }
它们可以使用结构体字面量初始化,顺序不重要,只有名称重要。:
1 2 let v1 = Vec2 { x: 1.0 , y: 3.0 };let v2 = Vec2 { y: 2.0 , x: 4.0 };
还有一种用于从另一个结构体初始化剩余字段的快捷方式,这称为“结构体更新语法”,只能出现在最后位置,并且不能以逗号结束:
1 2 3 4 let v3 = Vec2 { x: 14.0 , ..v2 };
剩余字段也可以是所有字段,这样就可以复制整个结构体,而不是改变所有权:
结构体,像元组一样,可以被解构:
1 2 3 let v = Vec2 { x: 3.0 , y: 6.0 };let Vec2 { x, y } = v;
下面这种形式可以通过..让v.y会被忽略掉:
let模式可以用作if中的条件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 struct Number { odd: bool , value: i32 , } fn main () { let one = Number { odd: true , value: 1 }; let two = Number { odd: false , value: 2 }; print_number (one); print_number (two); } fn print_number (n: Number) { if let Number { odd: true , value } = n { println! ("Odd number: {}" , value); } else if let Number { odd: false , value } = n { println! ("Even number: {}" , value); } }
match 也是一种模式匹配,就像 if let 一样:
1 2 3 4 5 6 fn print_number (n: Number) { match n { Number { odd: true , value } => println! ("Odd number: {}" , value), Number { odd: false , value } => println! ("Even number: {}" , value), } }
match 必须是穷尽的:至少有一个分支需要匹配。
1 2 3 4 5 6 7 8 fn print_number (n: Number) { match n { Number { value: 1 , .. } => println! ("One" ), Number { value: 2 , .. } => println! ("Two" ), Number { value, .. } => println! ("{}" , value), } }
如果穷尽匹配很难满足,可以使用 _ 作为 “通配符” 模式:
1 2 3 4 5 6 7 fn print_number (n: Number) { match n.value { 1 => println! ("One" ), 2 => println! ("Two" ), _ => println! ("{}" , n.value), } }
可以给类型声明方法。
1 2 3 4 5 6 7 8 9 10 struct Number { odd: bool , value: i32 , } impl Number { fn is_strictly_positive (self ) -> bool { self .value > 0 } }
变量默认不可以改变。
1 2 3 4 5 6 7 8 fn main () { let n = Number { odd: true , value: 17 , }; n.odd = false ; }
不能被重新赋值
1 2 3 4 5 6 7 8 9 10 fn main () { let n = Number { odd: true , value: 17 , }; n = Number { odd: false , value: 22 , }; }
可以使用mut关键字来声明可变变量。
1 2 3 4 5 6 7 fn main () { let mut n = Number { odd: true , value: 17 , }; n.odd = false ; }
特征(Traits)在Rust中实现了类似其他语言中的多态功能:
特征定义了一组可以由多种类型共享的行为契约。其定义如下:
1 2 3 trait Signed { fn is_strictly_negative (self ) -> bool ; }
任何满足这些条件的类型都可以实现这个特征:
1 2 3 4 5 impl Signed for Number { fn is_strictly_negative (self ) -> bool { self .value < 0 } }
这样,Number 类型就拥有了 is_strictly_negative 方法。特征也可以包含默认实现:
1 2 3 4 5 6 7 trait Signed { fn is_strictly_negative (self ) -> bool { self .value () < 0 } fn value (&self ) -> i32 ; }
然后,类型只需要提供那些没有默认实现的方法:
1 2 3 4 5 impl Signed for Number { fn value (&self ) -> i32 { self .value } }
Rust 的一个核心特征是 Drop,它允许你定义当值离开作用域时应该发生的事情:
1 2 3 4 5 impl Drop for Number { fn drop (&mut self ) { println! ("Dropping {}" , self .value); } }
当 Number 实例离开作用域时,Rust 会自动调用 drop 方法。
枚举(Enums)允许你定义一个类型,该类型可以是多个不同变体中的一个。这对于值可以有多种但数量有限的类型特别有用:
1 2 3 4 5 6 7 enum WebEvent { PageLoad, PageUnload, KeyPress (char ), Paste (String ), Click { x: i64 , y: i64 }, }
与结构体一样,枚举的每个变体可以包含不同类型和数量的数据。你可以使用 match 表达式来操作枚举值:
1 2 3 4 5 6 7 8 9 fn inspect (event: WebEvent) { match event { WebEvent::PageLoad => println! ("page loaded" ), WebEvent::PageUnload => println! ("page unloaded" ), WebEvent::KeyPress (c) => println! ("pressed '{}'" , c), WebEvent::Paste (s) => println! ("pasted \"{}\"" , s), WebEvent::Click { x, y } => println! ("clicked at x={}, y={}" , x, y), } }
枚举也可以有方法:
1 2 3 4 5 6 7 8 9 10 11 impl WebEvent { fn describe (&self ) -> String { match self { WebEvent::PageLoad => String ::from ("page loaded" ), WebEvent::PageUnload => String ::from ("page unloaded" ), WebEvent::KeyPress (c) => format! ("pressed '{}'" , c), WebEvent::Paste (s) => format! ("pasted \"{}\"" , s), WebEvent::Click { x, y } => format! ("clicked at x={}, y={}" , x, y), } } }
没有返回值的空函数:
1 2 3 fn greet () { println! ("Hi there!" ); }
右箭头表示返回值类型:
模块管理 在Rust中,模块是用于组织代码、控制可见性以及支持代码重用的重要概念。Rust的模块系统是基于文件和目录组织的,这使得代码的组织变得清晰而灵活。下面是Rust模块管理的一些关键概念:
模块定义 模块通过mod关键字进行定义,可以在一个Rust文件中定义一个模块。例如:
模块路径 模块路径用于指定模块的位置。Rust使用::来表示模块路径。例如:mod_example::example。
Rust的模块系统与文件系统有很强的映射关系。一个模块可以对应于一个文件,也可以对应于一个目录,包含多个文件。这使得项目的文件和目录结构能够与代码组织一致。
pub关键字在Rust中,使用pub关键字来标识模块、结构体、枚举、函数等的可见性。只有被标记为pub的项才可以在其他模块中被访问。
1 2 3 4 5 6 7 8 mod example { pub struct MyStruct { } } use example::MyStruct;
mod.rs文件文件本身是可以被作为模块引用的,这样可以更好地组织代码。mod.rs文件,作为模块的“命名空间”,用于存放模块的具体实现。例如:
使用方式:
1 2 use example::sub_module;
这个目录用于存放模块的具体实现。这有助于清晰地分离模块的定义和实现。
crate 和 supercrate关键字用于表示当前crate的根模块,而super关键字用于表示当前模块的父模块。
1 2 3 4 5 6 7 8 9 10 11 12 mod my_module { mod sub_module { use super::super::my_function; } } fn my_function () { }
模块的可见性规则 默认情况下,模块和其中的项对外部是不可见的。可以通过pub关键字调整可见性。Rust的模块系统强调了显式性,即除非明确指定为pub,否则默认情况下所有项都是私有的。
pub 有多种用法,包括:
pub:在默认情况下,Rust 中的项是私有的,只能在定义它们的模块中访问。使用 pub 关键字可以将项声明为公共的,使其在整个 crate 中都可见。
1 2 3 4 5 6 7 pub struct MyStruct { pub field: i32 , } pub fn my_function () { }
在这个例子中,MyStruct 和 my_function 都被声明为公共的,可以在 crate 的任何地方访问。
pub(crate):限制了项的可见性仅在当前 crate 中。这使得项在 crate 外部是不可见的,但在同一个 crate 内的所有模块都可以访问。
1 2 3 4 5 6 7 pub (crate ) struct InternalStruct { } pub (crate ) fn internal_function () { }
在这个例子中,InternalStruct 和 internal_function 只能在定义它们的 crate 中的任何模块中访问。
pub(super):限制了项的可见性仅在其父模块(即包含该项的模块)和其父模块的子模块中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 mod parent_module { pub (super ) struct SuperStruct { } pub fn super_function () { } mod child_module { fn inner_function () { let my_struct = SuperStruct { }; super_function (); } } }
在这个例子中,SuperStruct 和 super_function 在 parent_module 中可见,但在 crate 中的其他模块不可见。
pub(self):限制了项的可见性仅在当前模块中。这使得项对于同一模块中的其他模块是不可见的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 mod my_module { pub (self ) struct ModuleStruct { } pub (self ) fn module_function () { } mod submodule { fn inner_function () { } } }
在这个例子中,ModuleStruct 和 module_function 只能在 my_module 中的任何模块中访问。
这些可见性修饰符允许 Rust 程序员精确地控制项的可见性,从而确保代码结构的封装和安全性。
use指令use 指令可用于将其他命名空间的名称 “引入作用域”:
1 2 3 use std::cmp::min;let least = min (7 , 1 );
也可以用紧凑的写法:
1 2 3 4 5 6 7 use std::cmp::min;use std::cmp::max;use std::cmp::{min, max};use std::{cmp::min, cmp::max};
*可以通配引入:
Rust的模块系统是一个强大的组织和抽象工具,支持创建清晰、可维护、可重用的代码结构。了解和熟练使用模块系统有助于提高代码的可读性和可维护性。
错误类型和可选项 Result 和 Option 是 Rust 中用于错误处理和可选值的两个重要枚举类型。它们在处理不同类型的情况时非常有用。
Option 枚举类型Option 类型用于表示一个值可能存在(Some)或不存在(None)。它通常用于返回一个可能为空的值。
1 2 3 4 enum Option <T> { Some (T), None , }
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 fn find_element (vec: &Vec <i32 >, index: usize ) -> Option <i32 > { if index < vec.len () { Some (vec[index]) } else { None } } let numbers = vec! [1 , 2 , 3 ];match find_element (&numbers, 1 ) { Some (value) => println! ("Found: {}" , value), None => println! ("Not found" ), }
Result 枚举类型Result 类型用于表示一个操作可能成功(Ok)或失败(Err)。它通常用于返回一个可能会出错的操作结果。
1 2 3 4 enum Result <T, E> { Ok (T), Err (E), }
示例:
1 2 3 4 5 6 7 8 9 10 11 12 fn divide (a: i32 , b: i32 ) -> Result <i32 , String > { if b == 0 { Err (String ::from ("Division by zero" )) } else { Ok (a / b) } } match divide (4 , 2 ) { Ok (result) => println! ("Result: {}" , result), Err (e) => println! ("Error: {}" , e), }
Result 和 Option 的关系
Option 用于表示一个值可能存在或不存在,而不涉及错误信息。Result 用于表示一个操作可能成功或失败,并且可以携带错误信息。
在某些情况下,可以将 Option 转换为 Result,例如在需要提供错误信息时:
1 2 3 4 5 6 fn find_element (vec: &Vec <i32 >, index: usize ) -> Result <i32 , String > { match vec.get (index) { Some (&value) => Ok (value), None => Err (String ::from ("Index out of bounds" )), } }
通过这种方式,可以更灵活地处理错误和可选值。
自定义错误类型 在 Rust 中,通常建议使用自定义的错误类型来更好地表达错误信息。可以通过枚举或结构体来定义自己的错误类型,并实现 std::fmt::Debug 和 std::fmt::Display trait 来提供可读的错误信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #[derive(Debug)] enum MyError { DivisionByZero, CustomError (String ), } impl std ::fmt::Display for MyError { fn fmt (&self , f: &mut std::fmt::Formatter<'_ >) -> std::fmt::Result { match self { MyError::DivisionByZero => write! (f, "Cannot divide by zero" ), MyError::CustomError (msg) => write! (f, "Custom error: {}" , msg), } } } fn divide (a: f64 , b: f64 ) -> Result <f64 , MyError> { if b == 0.0 { Err (MyError::DivisionByZero) } else { Ok (a / b) } } fn main () { match divide (10.0 , 0.0 ) { Ok (result) => println! ("Result: {}" , result), Err (error) => println! ("Error: {}" , error), } }
使用 ? 操作符 Rust 中的 ? 操作符可以用于快速地将 Result 或 Option 的值传递给包含错误处理的函数。它简化了错误传播的代码。例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 fn operation1 () -> Result <i32 , &'static str > { Ok (42 ) } fn operation2 () -> Result <i32 , &'static str > { Ok (10 ) } fn main () -> Result <(), &'static str > { operation1 ()?; operation2 ()?; Ok (()) }
错误处理 thiserror 和 anyhow 错误处理
我们的Result类型都是anyhow::Result并且通过thiserror的宏来自定义错误。
单元测试 通过配置宏 #[cfg(test)],我们可以指定某个模块为测试模块,并且可以为模块内的函数配置 #[test] 以指定某个函数为测试实例。在 Rust 中,习惯性地会创建一个与模块同级的名为 tests 的模块,然后在该模块中编写测试函数。这些测试代码一般位于与源代码相同的文件中(也可以分成独立的文件编写)。下面的示例代码演示了如何简单验证两个数的相加。在本书中,测试代码按照类似的格式提供,旨在验证实现的正确性,并一定程度上提供对应函数或方法的使用示例。assert_eq! 是一个宏函数,用来断言相等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 mod my_module { pub fn add (a: i32 , b: i32 ) -> i32 { a + b } } #[cfg(test)] mod tests { use super::my_module; #[test] fn test_add () { assert_eq! (my_module::add (2 , 3 ), 5 ); } }
本书的代码按章节模块化组织,每个章节都可以独立运行。使用 cargo test 命令,可以按章节前缀运行对应的单元测试(例如 cargo test ch1),也可以执行具体的测试函数(例如 cargo test ch1::skiplist::tests::it_works)。章节内容循序渐进,每章结束时会引入前面章节的模块。这种组织方式使读者能够逐步学习和理解每个模块的工作原理。每个章节相对独立,读者也可以跳跃式阅读。
读者可以根据需要修改每个独立模块,尝试理解其工作原理,或在自己实现过程中参考这些模块。这种结构旨在提供灵活性,使读者能够自由地使用和探索本书的代码。
所有权和引用 所有权是由编译器检查的,因此检查会非常严格。在Rust中,浅拷贝会移交所有权(move),而深拷贝(Copy)则会复制对象,从而避免所有权冲突。如果一个对象实现了Copy trait,也可以进行复制,不会与所有权产生冲突。在Rust中,只有copy和move两种操作。
引用不会获得所有权,因此也没有权利调用Drop。创建引用在Rust中被称为借用,因此借用和引用有时会混用。借用被视为一个动词,而引用被视为一个名词。如果希望在不产生Copy的情况下修改一个对象,可以使用可变引用。
Rust规定一个对象只能有一个可变引用,且不能同时存在其他的可变或不可变引用。
笔者推荐更详细的内容可以阅Rust Book 和Rust nomicon ,这两本书都是比较全面且标准的Rust教程。
在本书的数据库实现中,我们主要使用字节向量和字节切片,分别用 Vec<u8> 和 &[u8] 表示,代表具有所有权的字节块和对字节块的借用。由于所有权的关系,如果我们只需要读取数据,会使用借用;如果需要保存写入的数据,则会使用具有所有权的对象 Vec<u8>。&mut [u8] 是可修改的借用,实际上也具有所有权,当我们需要修改连续内存的一部分时,可以使用这种类型。
如果我们不需要所有权,as_ref 和 as_mut 可以为我们提供相应的引用。
Rust约定的迭代器类型如下,注意 IntoIter 有些不同,如果是一个切片的 IntoIter,返回的仍然是引用。
1 2 3 IntoIter - T IterMut - &mut T Iter - &T
而 as_deref 和 as_deref_mut 可以帮助我们自动解多层引用。
避免盲目使用 .clone() 满足借用规则 借用检查器确保 Rust 用户在开发中不会产生不安全的代码。具体而言,它防止了两种情况:首先,只允许存在一个可变引用;其次,允许存在多个引用,但全部都是不可变引用。如果编写的代码不符合这些条件,当开发人员通过克隆变量来解决编译器错误时,就可能陷入这种反模式。
对于初学者而言,使用 .clone() 来解决借用检查器引起的混乱问题是很诱人的。然而,这样做会带来严重的后果。使用 .clone() 会导致数据的复制,两者之间的任何更改都不会同步,就像存在两个完全独立的变量一样。
有一些特殊情况,例如 Rc<T> 被设计成可以智能处理克隆。它在内部管理数据的精确一份拷贝,克隆它将只克隆引用。
还有 Arc<T>,它提供对在堆上分配的类型为 T 的值的共享所有权。在 Arc 上调用 .clone() 会产生一个新的 Arc 实例,它指向堆上与源 Arc 相同的分配,同时增加引用计数。
总的来说,克隆应该是经过深思熟虑的,要充分了解后果。如果使用克隆来消除借用检查器错误,这是可能正在使用这种反模式的一个很好的指示。
即使 .clone() 是一个糟糕模式的指示,有时写效率低下的代码也是可以接受的,比如:
开发者仍然是个新手
代码没有很大的速度或内存约束(比如黑客马拉松项目或原型)
满足借用检查器真的很复杂,而你更愿意优化可读性而不是性能
如果怀疑存在不必要的克隆,应该充分了解《Rust Book》关于所有权的章节,然后评估是否需要这个克隆。
同时,务必在项目中始终运行 cargo clippy,这个 lint 工具会帮你检查一些不必要的 clone。
函数借用参数的选择 函数参数会用到大量的借用,因为借用不会产生拷贝,但在使用借用的时候尽量使用直接的借用类型 &str、&[T]、&T 而不是 &String、&Vec<T>、&Box<T>。在作为参数的时候,后面的拥有所有权的类型(智能指针)可以自动转换成前面的类型,而反过来则不可以。例如,下面这个函数如果把参数改成 &String 是无法编译的。原因是直接的引用类型需要再分配一个对应的所有权类型才能和所有权类型的引用对齐,但是反过来进行一次解引用就可以获得直接引用。比如 a = Box<T>,其实相当于 &(*a),编译器自动进行了转化先解引用对应的直接类型然后直接引用。反过来的话 a = &T,那就得 &Box::new(*a),需要多创建这个 Box 对象,编译器就直接拒绝了。
1 2 3 4 5 6 7 8 9 fn demo (word: &str ) {} fn main () { let ferris = "Ferris" ; let curious = "Curious" .to_string (); demo (ferris); demo (&curious); }
不可变引用和 Rc 不可变引用的生命周期必须小于所有权的生命周期,但Rc不要求,只要最后一个引用离开生命周期则回收。
临时的可变性 可以将可修改对象重新赋值让可变性消失。这样做有一个好处就是如果你明确在之后不想修改该对象,而又人为(可能被合作者,或者两个月后的自己)错误地修改了,编译器就会帮你检查出来。我觉得更多的是在人的“阅读期”直观地明确代码的可变性。
1 2 3 4 5 6 let data = { let mut data = get_vec (); data.sort (); data };
1 2 3 4 5 let mut data = get_vec ();data.sort (); let data = data;
协同性 协同性是Rust里面最难的部分了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 fn two_refs <'big : 'small , 'small >(big: Vec <&'big u32 >, small: Vec <&'small u32 >) { take_two (big, small); } fn take_two <T>(_val1: T, _val2: T) {}#[cfg(test)] mod tests { use super::*; #[test] fn it_works () { let skl = SkipList { head: None }; } }
NonNull本质是一个*const T,从而使得NonNull可以与T协变,通过强制转换的方式让这个指针是可修改的。这是标准库中常用的一个对象,目的是让Vec这样的类型使用起来与T具有协变性。
1 2 3 pub struct NonNull <T> { pointer: *const T, }
具体的解释可以参考这里 ,目前笔者也没有完全理解这个概念。
Subtyping is the idea that one type can be used in place of another.
范型 Rust 中的泛型是一种强大的特性,它允许你编写适用于多种数据类型的代码,同时保持类型安全。通过泛型,可以编写更加灵活、抽象和可重用的代码,同时保持 Rust 的内存安全和零成本抽象。
以下是 Rust 中泛型的一些关键概念和用法:
泛型函数 在 Rust 中,你可以编写泛型函数,使其适用于多种类型。示例:
1 2 3 4 5 6 7 8 9 fn print_twice <T>(value: T) { println! ("{:?}" , value); println! ("{:?}" , value); } fn main () { print_twice ("Hello, Rust!" ); print_twice (42 ); }
在这个例子中,print_twice 是一个泛型函数,可以接受任意类型的参数,并执行相同的打印操作。
泛型结构体 可以为结构体定义泛型类型参数,以实现对不同类型的结构体的抽象。示例:
1 2 3 4 5 6 7 8 9 struct Point <T> { x: T, y: T, } fn main () { let int_point = Point { x: 1 , y: 2 }; let float_point = Point { x: 1.5 , y: 2.5 }; }
在这个例子中,Point 结构体可以用于包含任何相同类型的坐标点。
泛型枚举 枚举也可以包含泛型类型参数,以增加其灵活性。示例:
1 2 3 4 5 6 7 8 9 enum Result <T, E> { Ok (T), Err (E), } fn main () { let success : Result <i32 , &str > = Result ::Ok (42 ); let failure : Result <i32 , &str > = Result ::Err ("Error message" ); }
在这个例子中,Result 枚举表示可能包含成功结果(Ok)或错误信息(Err),并分别包含了两个泛型类型参数。
泛型实现 可以对泛型类型实现 trait,以为多种类型提供相同的行为。示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 trait Printable { fn print (&self ); } impl <T: std::fmt::Debug > Printable for T { fn print (&self ) { println! ("{:?}" , self ); } } fn main () { "Hello, Rust!" .print (); 42 .print (); }
在这个例子中,Printable trait 定义了一个 print 方法,然后对所有实现了 Debug trait 的类型实现了这个 trait。
Rust 的泛型提供了强大的抽象能力,帮助编写更加灵活和通用的代码。通过泛型,你能够在不失去类型安全的前提下,减少代码的冗余并提高代码的可维护性。
Read 和 Write 在本书中用的 Trait 比较多的是 Read、Write 和 Seek。
在 Rust 中,Read、Write 和 Seek 是三个与 I/O 操作密切相关的 trait,它们为实现输入和输出操作提供了通用的接口。这三个 trait 可以用于文件、网络套接字等不同的数据源和目标。
Read Trait :
1 fn read (&mut self , buf: &mut [u8 ]) -> Result <usize , Error>;
这个方法从实现 Read trait 的类型中读取字节,并将它们存储到提供的缓冲区 buf 中。方法返回一个 Result,其中 Ok(n) 表示成功读取了 n 个字节,Err 表示发生了错误。
Write Trait :
1 fn write (&mut self , buf: &[u8 ]) -> Result <usize , Error>;
这个方法将提供的缓冲区 buf 中的字节写入到实现 Write trait 的类型中。方法同样返回一个 Result,其中 Ok(n) 表示成功写入了 n 个字节,Err 表示发生了错误。
Seek Trait :
1 2 3 fn seek (&mut self , pos: SeekFrom) -> Result <u64 , Error>;fn stream_len (&mut self ) -> Result <u64 , Error>;fn stream_position (&mut self ) -> Result <u64 , Error>;
seek 方法通过给定的 SeekFrom 枚举类型,将读写指针移动到指定位置。stream_len 方法返回数据源的总长度。stream_position 方法返回当前读写指针的位置。
SeekFrom 枚举有以下几种可能的值:
SeekFrom::Start(n):将指针设置到数据源的起始位置加上 n。SeekFrom::End(n):将指针设置到数据源的末尾位置加上 n。SeekFrom::Current(n):将指针从当前位置移动 n 个字节。
这些 trait 为实现了文件、内存缓冲区等不同类型的数据源和目标提供了通用的接口,使得可以方便地使用相同的 I/O 操作代码处理各种类型的输入输出。在标准库中,例如 File 和 BufReader 都实现了这些 trait,使得对文件和缓冲区的读写变得简单和灵活。
本书中会大量用到这些 Trait,因为 Vec<u8> 和 fs::File 都实现了这个接口。
Iterator Iterator用于不可变迭代,IntoIterator用于获取所有权并进行迭代,MutIterator用于可变迭代。
1 2 3 fn iter (&'a self ) -> Items<'a >;fn into_iter (self ) -> ItemsMove;fn iter_mut (&'a mut self ) -> ItemsMut<'a >;
Rust 的标准库为集合类型提供了一组通用的迭代方法,这些方法通常以 Iterator trait 的形式提供。这些方法通常分为三类,即标准的迭代方法 trio:
fn iter(&'a self) -> Items<'a>; 用来遍历&T。
这个方法返回一个不可变的迭代器,允许对集合中的元素进行只读的迭代。返回的 Items 类型是一个迭代器对象,其生命周期与集合本身相同,保证迭代器不会在集合被销毁前失效。
fn iter_mut(&'a mut self) -> ItemsMut<'a>; 用来遍历&mut T
这个方法返回一个可变的迭代器,允许对集合中的元素进行修改。返回的 ItemsMut 类型是一个可变迭代器对象,其生命周期与可变引用的生命周期相同,确保迭代器不会在可变引用结束后继续使用。
fn into_iter(self) -> ItemsMove; 用来遍历T,但如果T是一个引用类型其实和iter是类似的。
这个方法获取集合的所有权并返回一个拥有所有权的迭代器。这表示集合本身将不再可用,因为它的所有权已经转移到迭代器上。返回的 ItemsMove 类型是一个拥有所有权的迭代器对象。
为了提供更大的灵活性和符合 Rust 的所有权模型,这些方法还要求集合类型和对集合的(可变)引用都实现了 IntoIterator trait。这个 trait 提供了一个统一的方式,使得集合类型和引用都能够被用于 for 循环等需要迭代的上下文中。
这种设计使得 Rust 中的迭代更为一致和灵活,同时确保了在迭代过程中对所有权和可变性的严格控制。
两级迭代器(TwoLevelIterator)可以使用标准库的flat_map可以把两级迭代器展开成一个大的迭代器,适用于一些多层次迭代器的场景。
1 2 3 4 5 6 7 8 9 fn main () { let data = vec! [vec! [1 , 2 , 3 ], vec! [4 , 5 , 6 ], vec! [7 , 8 , 9 ]]; let flat_iter = data.iter ().flat_map (|inner| inner.iter ()); for &num in flat_iter { println! ("{}" , num); } }
归并迭代器可以实现两个有序迭代器的归并排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 struct MergeSortIterator <L, R>where L: Iterator , R: Iterator <Item = L::Item>, { left: L, right: R, left_value: Option <L::Item>, right_value: Option <R::Item>, } impl <L, R> MergeSortIterator<L, R>where L: Iterator , R: Iterator <Item = L::Item>, { fn new (left: L, right: R) -> Self { let mut sorter = MergeSortIterator { left, right, left_value: None , right_value: None , }; sorter.fetch_values (); sorter } fn fetch_values (&mut self ) { self .left_value = self .left.next (); self .right_value = self .right.next (); } } impl <L, R> Iterator for MergeSortIterator <L, R>where L: Iterator , R: Iterator <Item = L::Item>, L::Item: Ord , { type Item = L::Item; fn next (&mut self ) -> Option <Self ::Item> { match (self .left_value.take (), self .right_value.take ()) { (Some (left), Some (right)) => { if left <= right { self .left_value = self .left.next (); self .right_value = Some (right); Some (left) } else { self .left_value = Some (left); self .right_value = self .right.next (); Some (right) } } (Some (left), None ) => { self .left_value = self .left.next (); Some (left) } (None , Some (right)) => { self .right_value = self .right.next (); Some (right) } (None , None ) => None , } } } fn main () { let iter1 = vec! [1 , 3 , 5 , 7 , 9 ].into_iter (); let iter2 = vec! [10 ,11 , 12 , 13 , 14 ].into_iter (); let merge_iter = MergeSortIterator::new (iter1, iter2); for item in merge_iter { println! ("{}" , item); } }
幽灵数据 如果SkipIterator使用&'a Link很奇怪,因为Link本身就是个Rc
1 2 3 4 5 6 7 8 9 10 11 12 struct SkipIterator <'a > { head: Link, marker: PhantomData<&'a SkipNode>, } impl <'a > Iterator for SkipIterator <'a > { type Item = &'a SkipNode; fn next (&mut self ) -> Option <Self ::Item> { None } }
性能调优 TODO
perf profile tracing 第二章理解键值数据库 键值数据库的介绍 键值数据库(Key-Value Database)在NoSQL(非关系型数据库)范畴中占据重要地位,其采用简洁的键值的结构对数据对象进行存储和检索。
许多键值数据库支持分布式架构,能够在多个节点上存储数据,以提高性能和可靠性。亚马逊的DynamoDB是一个典型的例子,于1999年提出并成为高度可扩展的键值数据库系统,满足了亚马逊的分布式存储需求,其思想和设计对后来的键值数据库系统产生了深远的影响。
Redis是另一备受欢迎的键值数据库,由Salvatore Sanfilippo于2009年创建。它是一种开源的内存中数据结构存储系统,支持多种数据结构,包括字符串、哈希表和列表,因而成为广泛使用的键值数据库。
LevelDB是由Google开发的高性能键值数据库,采用LSM树(Log-Structured Merge Tree)的结构。在2012年,RocksDB发布,进一步优化了性能和存储效率,受到了广泛的应用。
键值数据库以其快速的读写性能而著称,尤其在需要快速检索特定键的情境下表现出众。它们通常具备横向可扩展性,能够通过添加更多节点来处理更大的负载。其对值的数据结构没有强制规定,因此可以灵活存储各种类型的数据。本书聚焦于单机键值数据库,不会涉及一些集群数据库相关的分布式能力和扩展能力。
LSM 本书将会实现一个类似LevelDB的键值数据库,其核心数据结构是LSM(Log-Structured Merge Tree)。
LSM最早来源于1996年的一篇论文[^1],而被广为人知的契机则是Google的BigTable[^2]论文,其中的文件格式基于LSM。Google开源了类似键值数据库的单机版本,即LevelDB[^3]。传统数据库通常使用B-Tree类的数据结构,它具有许多优点。随着LevelDB的诞生,基于LSM-Tree的数据结构也逐渐进入人们的视野。
LSM是一种用于存储和管理大规模键值对数据的数据结构,它在特定应用场景中非常有效,具有以下优势:
高写入吞吐量 :LSM树通过将写入操作追加到顺序写的文件中,并使用内存和磁盘两级存储结构,实现了高效的写入吞吐量。写入操作可以在内存中迅速完成,然后异步地合并到磁盘上的存储文件中。
压缩和合并 :LSM树通过定期合并和压缩磁盘上的存储文件,提高了读取性能。这些合并操作使得数据在磁盘上以更为紧凑的形式存储,减少了读取时需要扫描的数据量。
高吞吐读取 :LSM树的结构使得范围查询更加高效,因为数据在磁盘上以顺序方式存储。这对于分析型工作负载非常有利。
容错性 :由于LSM树的写入操作是追加到预写日志文件中的,这提供了一种容错机制。即使在写入过程中出现故障,系统也可以通过重新应用日志来恢复。
可扩展性 :LSM树适用于大规模的分布式存储系统,支持数据的水平扩展。各个节点可以独立地执行写入和合并操作,从而提高了系统的可扩展性。
减少随机I/O :LSM树的追加写入方式减少了磁盘上的随机I/O,有助于提高写入性能。这对于使用磁盘作为主要存储介质的系统尤为重要。
[^1]: 《The Log-Structured Merge-Tree (LSM-Tree)》:这是LSM的原始论文。
HDD和SSD LevelDB是为了针对HDD的追加写的特性而设计的,有很多优化是基于SSD的。
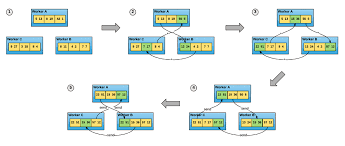
第三章构建数据库引擎 基本架构 整个数据库的基本架构下图,一般来说,一个实现LSM键值存储接口所使用的对象是任意字节流。
用到这追加写的文件就是预写日志。可靠的单机数据库需要确保用户调用写入接口返回成功后,即使进程重启(甚至因机器宕机而中断)也不会导致数据丢失。writer_buffer相关的配置指的就是这个MemTable的大小,因为某种程度上它就是预写日志的内存缓存。
当MemTable达到容量上限(大多数数据库的默认设置为4KB),内存表的内容会被保存在持久化的文件存储中,接着日志文件可以安全删除。
数据库会对SSTable进行分层合并,由上层(或上上层)的SSTable合并成新的SSTable,并写入到下一层。
为了限制内存大小,当MemTable达到一定大小后,会转换为不可变内存表。
当有新的文件产生时需要一个清单文件对这些文件进行记录,一般会使用一个叫MANIFEST的文件保存,用于记录各阶段文件集合信息。
对于读操作,需要从内存表、不可变内存表、level-0 SSTable里查找,然后再从level 1中的文件开始查找。
MemTable MemTable是一个内存中的数据结构,在数据被刷新到SST文件之前保存它们。它相当于一个读写的缓存——新的写总是将数据插入到MemTable中,而读必须在从SST文件读取之前查询MemTable,因为MemTable中的数据是较新的。一旦内存表被填满,它就变成不可变的,并被一个新的内存表所取代。一个后台线程将MemTable的内容刷新到一个SST文件中,之后MemTable就可以被销毁了。MemTable的大小一般是64MB。
SkipList SkipList(跳表)是一种常用于实现有序存储的数据结构,通常用于构建内存表(MemTable)等应用场景。相比于平衡树等结构,SkipList 不需要复杂的旋转调整来保持平衡,其实现较为简单且易于理解。
SkipList 由一系列节点组成,每个节点包含键值对以及多个层级的指针。节点的高度由一个概率随机决定,这使得 SkipList 在期望上具有 O(log n) 的搜索复杂度。节点结构如下:
1 2 3 4 5 6 struct SkipNode { key: Vec <u8 >, value: Vec <u8 >, h: usize , next: Vec <Link>, }
SkipList的搜索操作是SkipList中的基本操作之一。从头节点开始,逐层向下搜索,如果找到等于目标键的节点,则返回对应值;如果找到大于目标键的节点,就下移一层继续搜索;如果找到小于目标键的节点,就向右移动。这样,通过多层级的指针,可以有效地减少搜索路径。
1 1 -> 2 -> 3 -> 4 -> 5 -> 6 -> 7 -> 8
这个搜索是线性的,但是如果再加一个链表,每隔一个结点取一次,可以节省一半的时间,从最高level的链表开始到小于后置节点时向下一个level搜索,这时5要搜索4次(1,3,5),找到4需要3次(1,3,4)。
1 2 1 - - - - 3 - - - - 5 - - - - 7 1 -> 2 -> 3 -> 4 -> 5 -> 6 -> 7 -> 8
以此类推,再增加一个链表的话,此时5只要搜索2次(1,5),4则没变还是3次(1,3,4)。
1 2 3 1 - - - - - - - - - 5 - - - - - 1 - - - - 3 - - - - 5 - - - - 7 1 -> 2 -> 3 -> 4 -> 5 -> 6 -> 7 -> 8
这里每个节点的元素只需要存一次,但是每个节点的高度之内都要保存对应指针。
SkipList相较于一些有序数据结构比如平衡树来说不需要做一些旋转的调整来保持树的平衡,节点的高度是基于概率的,如果设置概率为1/2的话可以通俗的理解为“丢硬币,每次正面则这个节点的高度提高一层”,从期望上来说是可以被证明为log(n)的。因为SkipList和链表很接近,相较于平衡树来说手写更容易实现。但不巧的是链表在Rust里面是地狱难度的实现,本章的篇幅因此会比较长。
首先我们通过rand::Rng生成一个u32的随机数,用最低位的连续1的数量作为高度,每次最低位为1时,高度加1,并且随机数右移,模仿丢硬币的过程。
1 2 3 4 5 6 7 8 9 10 11 12 use rand::Rng;fn random_height (total: usize ) -> usize { let mut h = 0 ; let mut r = rand::random::<u32 >(); while r & 1 == 1 && h < total { h += 1 ; r >>= 1 ; } h }
首先我们定几个数据结构,Rc是引用计数,节点会被多个前置节点指向,所以我们需要使用Rc包裹我们的节点。RefCell是一个智能指针,可以将借用的规则推迟到运行时检查,通过borrow_mut方式及时对象没有使用mut声明Option用来表示空指针。所以组合起来我们构造了一个Link类型。
1 2 3 use std::cell::RefCell;use std::rc::Rc;type Link = Option <Rc<RefCell<SkipNode>>>;
我们围绕的对象都是字节串,所以键值都用Vec来存储,为了突出代码的说明性质不引入过多的复杂性,这里没有使用范型。
1 2 3 4 5 6 const MAX_HEIGHT: usize = 32 ;struct SkipList { head: Link, }
下面两个函数都被包裹在impl SkipList {}中,为了阅读方便进行了省略,创建SkipList的时候会创建一个非None的key和value都为vec![]的占位节点。
搜索操作是 SkipList 中的基本操作之一。从头节点开始,逐层向下搜索,如果找到等于目标键的节点,则返回对应值;如果找到大于目标键的节点,就下移一层继续搜索;如果找到小于目标键的节点,就向右移动。这样,通过多层级的指针,可以有效地减少搜索路径。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 fn get (&mut self , key: &[u8 ]) -> Option <Vec <u8 >> { let mut cur = self .head.clone (); for l in (0 ..MAX_HEIGHT).rev () { while let Some (next) = cur.clone ().unwrap ().borrow ().next[l].clone () { if &next.borrow ().key[..] > key { break ; } else if &next.borrow ().key[..] < key { cur = Some (next); } else { return Some (next.borrow ().value.clone ()); } } } None }
如果是ge的实现,则在level为0时选择大于的值返回。
1 2 3 4 5 6 7 std::cmp::Ordering::Greater => { if l == 0 { return Some ((next.borrow ().key.clone (), next.borrow ().value.clone ())); } break ; }
插入和搜索类似,当找到下一项大于自己或者为None时将自己链接到当前节点之后,如果下一项小于自己则向后移动。插入操作也是 SkipList 中的关键操作。从头节点开始,逐层向下搜索,找到合适的位置插入新节点。为了保持 SkipList 的有序性,需要在每一层级中正确地插入节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 fn insert (&mut self , key: &[u8 ], value: &[u8 ]) { let h = random_height (MAX_HEIGHT); let new_node = Rc::new (RefCell::new (SkipNode { key: key.to_vec (), value: value.to_vec (), h, next: vec! [None ; MAX_HEIGHT], })); let mut cur : Link = self .head.clone (); for l in (0 ..h + 1 ).rev () { while let Some (cur_node) = cur.clone () { let mut cur_node = cur_node.borrow_mut (); match cur_node.next[l].clone () { Some (next) => { if &next.borrow ().key[..] < key { cur = Some (next); } else if &next.borrow ().key[..] > key { cur_node.next[l] = Some (new_node.clone ()); new_node.borrow_mut ().next[l] = Some (next.clone ()); break ; } else { next.borrow_mut ().value = value.to_vec (); break ; } } None => { cur_node.next[l] = Some (new_node.clone ()); } } } } }
链表这类数据结构是Rust中地狱级难度,如果要实现一个通用的链表类的数据结构涉及到协同性(Covariance),标准库中用到了很多unsafe的实现,通过指针的方式简化了代码,例如我们要实现双向链表的话Rc就不适用了,因为指向时成环的。
我们在实现链表的时候是无法依赖编译器帮我们自动释放空间的,因为编译器默认的行为会是一个递归调用Drop。
1 2 3 4 5 6 impl Drop for Box <Node> { fn drop (&mut self ) { self .ptr.drop (); deallocate (self .ptr); } }
所以链表我们要手动实现Drop函数,这里面把box替换出来变成Empty,这样在“死亡”时就可以避免调用next了(毕竟next已经为空了不会有递归调用)。
我们不可以move一个可变引用即使move给了自己,理论上这不算错误,所以需要mem::replace,如果想要实现move就得通过replace的方法。
1 2 3 4 5 6 7 8 9 10 struct Buffer <T> { buf: Vec <T> }impl <T> Buffer<T> { fn replace_index (&mut self , i: usize , v: T) -> T { let t = self .buf[i]; self .buf[i] = v; t } }
1 2 3 4 5 6 7 8 9 10 11 12 13 impl Drop for List { fn drop (&mut self ) { let mut cur_link = mem::replace (&mut self .head, Link::Empty); while let Link ::More (mut boxed_node) = cur_link { cur_link = mem::replace (&mut boxed_node.next, Link::Empty); } } }
[并发写入] todo!()
[插入提示] todo!()
预写日志 下面我们展开讲解预习日志的相关知识和实现方式,日志文件切分成了大小为32KB的连续block块,block由连续的log record组成。
Record Record的格式如下,首先是一个4个字节的CRC校验值紧跟着一个两个字节的u16表示长度,然后是一个字节表示类型,最后是实际的负载。
1 2 3 +---------+-----------+-----------+--- ... ---+ |CRC (4B) | Size (2B) | Type (1B) | Payload | +---------+-----------+-----------+--- ... ---+
如果我们使用u64保存长度是可以存储很大的数据的,RocksDB的一篇数据库键值规模的分析[^4]中提到一般的键是几十个字节,
[^4]: 《Characterizing, Modeling, and Benchmarking RocksDB Key-Value Workloads at Facebook》
负载长度的扩展 我们按照LevelDB的格式使用Type表示记录的连续性,Log Type有4种:FULL = 1、FIRST = 2、MIDDLE = 3、LAST = 4。FULL类型表明该log record包含了完整的用户数据,用户数据可能比较大,超过了当前block的剩余大小,就需要分成几条log record,第一条类型为FIRST,中间的为MIDDLE,最后一条为LAST。也就是:
FULL ,说明该log record包含一个完整的用户数据;FIRST ,说明是log record的第一条用户数据;MIDDLE ,说明是log record中间的用户数据;LAST ,说明是log record最后的一条用户数据。
A: length 1000
B: length 97270
C: length 8000
A作为FULL类型的record存储在第一个block中; B将被拆分成3条log record,分别存储在第1、2、3个block中,这时block3还剩6byte,将被填充为0; C将作为FULL类型的record存储在block 4中。
由于一条log record长度最短为7(4个字节的CRC加2个字节的Size加1一个字节的Type),如果一个block的剩余空间小于等于6个字节,那么将被填充为 空字符串,长度为7的log record是不包括任何用户数据的空记录。
LevelDB将WAL文件按块划分还有一个好处是能够按块进行切分。对于一些类似MapReduce的处理程序来说比较友好,
大小端 大小端(Endian)是计算机体系结构中的一个重要概念,用于描述多字节数据在内存中的存储方式。
大端序(Big-Endian):在大端序中,最高有效字节(Most Significant Byte,MSB)位于最低内存地址,而最低有效字节(Least Significant Byte,LSB)位于最高内存地址。这意味着数据的各个部分从高位到低位依次存储。举例来说,十进制数值513在大端序下会以两个字节0x02(512)和0x01(1)的顺序存储。
小端序(Little-Endian):相反,小端序中,最低有效字节(LSB)位于最低内存地址,而最高有效字节(MSB)位于最高内存地址。这意味着数据的各个部分从低位到高位依次存储。以相同的例子,十进制数值513在小端序下会以两个字节0x01和0x02的顺序存储。
1 2 3 4 5 6 7 8 let le_bytes = 513u16 .to_le_bytes ();println! ("Little-endian bytes: {:?}" , le_bytes);let be_bytes = 513u16 .to_be_bytes ();println! ("Big-endian bytes: {:?}" , be_bytes);
这两种字节序的差异可能在跨平台数据交换或者数据解释方面引发问题。例如,当你从一个大端序计算机向一个小端序计算机传输数据时,需要进行字节序转换,以确保数据正确解释。这样的差异在网络通信、文件存储、数据传输等领域都有广泛的应用。
计算机体系结构、操作系统和编程语言通常会规定默认的字节序,但程序员和开发人员需要了解大小端的概念,以确保数据在不同系统之间正确传递和解释。在考虑兼容性的情况下,我们可以选择固定一种大小端的方式。在本书中,我们选择小端编码,这也是X86的CPU的模式。
CRC CRC(Cyclic Redundancy Check,循环冗余校验)是一种高效的检错码,用于数据的校验。它基于模二除法进行计算,通过计算结果的余数来生成校验值。模二除法相当于是一种不借位的减法,因为0减1在模二运算后仍为1。在二进制领域,模二运算等效于异或操作,因此CRC可以通过位移和异或的方式进行快速计算。
CRC32是一种广泛使用的CRC类型,其余数为32位,对应的除数是33位的多项式。该多项式表示为:X^{32}+X^{26}+X^{23}+X^{22}+X^{16}+X^{12}+X^{11}+X^{10}+X^8+X^7+X^5+X^4+X^2+X^1+X^0 ,用二进制表示为0x4c11db7。在具体实现中,这个多项式的概念并不直接涉及,而是专注于基于二进制的计算过程。CRC32常用于键值数据库,以4字节大小保存校验和。
CRC的数据开头添加0不影响结果,所以会预设置一个余数初始值0XFFFFFFFF,和结果异或值0XFFFFFFFF,这个值在其他CRC类型中可能是别的值。
CRC一般的实现有一个反向bit顺序,这个和一些硬件的传输顺序有关系,有些硬件设备是把最低位的bit先进行传输,同时在软件层面代码的实现上会更简单一点,相当于我们把最低位当成了最高位,在一些教科书中可能不会明确这个具体实现上的差异。逆向计算的时候,0x4c11db7的逆向表示是0xedb88320。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 pub fn crc32 (data: &[u8 ]) -> u32 { let mut crc : u32 = 0xffffffff ; for byte in data { crc ^= u32 ::from (*byte); for _ in 0 ..8 { if crc & 1 == 1 { crc = (crc >> 1 ) ^ 0xedb88320 ; } else { crc >>= 1 ; } } } crc ^ 0xffffffff }
当然这个实现是最简单的版本,每次只进行1bit的位移。
CRC32有一个查表法的快速计算方法。CRC32的查表法是一种用于加速计算的优化方式,通过预计算并存储查表,可以显著提高CRC的计算速度。这种优化的核心思想是将CRC的计算过程中的每个字节或更小颗粒度的数据提前计算并存储在一个查表中,以便在实际计算中直接查表获取结果,而不需要逐位进行运算。
在实际应用中,可以按照字节、4位或16位的颗粒度进行预计算并存成表。这样,每次计算CRC时,只需按颗粒度查表,从而大幅减少了计算的复杂度,提高了效率。
除了查表法,CRC32的另一种优化方式是通过指令级优化,主要依赖于SSE(Streaming SIMD Extensions)和PCLMULQDQ指令集。
SSE指令集:SSE是Intel引入的一组指令,用于执行单指令多数据(SIMD)操作。通过使用SSE指令,可以同时对多个数据进行相同的操作,从而提高并行计算能力,加速CRC32的计算过程。
PCLMULQDQ指令集:PCLMULQDQ指令集是Intel和AMD的x86-64架构中的一组指令,用于执行多项式乘法。CRC32的计算可以看作是多项式乘法,因此使用PCLMULQDQ指令集可以更高效地执行这一计算过程。
通过结合SSE和PCLMULQDQ指令集,可以在硬件层面上进一步提升CRC32的计算性能,使其更适用于高性能计算和大规模数据处理。一些快速计算crc的库基本是运用了
VARINT Varint使用7个比特的组合来表示整数的值,其中每个字节的最高位用于指示是否有更多的字节。如果最高位为1,表示后面还有一个字节;如果最高位为0,表示这是最后一个字节。这种设计使得解码过程相对简单,而且可以高效地处理不同大小的整数。use Varint,u64就会拥有to_varint_bytes的方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 pub trait Varint { fn to_varint_bytes (self ) -> Vec <u8 >; fn from_varint_bytes (data: &[u8 ]) -> (Self , usize ) where Self : Sized ; } impl Varint for u64 { fn to_varint_bytes (self ) -> Vec <u8 > { let mut value = self ; let mut bytes = Vec ::new (); loop { let mut byte = (value & 0b0111_1111 ) as u8 ; value >>= 7 ; if value != 0 { byte |= 0b1000_0000 ; } bytes.push (byte); if value == 0 { break ; } } bytes } fn from_varint_bytes (data: &[u8 ]) -> (Self , usize ) { let mut value = 0 ; let mut shift = 0 ; let mut bytes_read = 0 ; for &byte in data { value |= ((byte & 0b0111_1111 ) as u64 ) << shift; shift += 7 ; bytes_read += 1 ; if byte & 0b1000_0000 == 0 { break ; } } (value, bytes_read) } }
内部Key 存储于数据库中的Key携带了额外信息:Sequence和Meta。
| User key (string) | sequence number (7 bytes) | meta (1 byte) |
Rust定义如下:
1 2 3 4 5 6 pub struct InternalKey { pub user_key: Vec <u8 >, trailer: u64 , } const INTERNAL_KEY_SEQ_NUM_MAX: u64 = (1 << 56 ) - 1 ;
编解码的方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 fn make_trailer (seq: u64 , kind: InternalKeyKind) -> u64 { (seq << 8 ) | (kind as u64 ) } pub fn decode (mut encoded_key: Vec <u8 >) -> Option <InternalKey> { if encoded_key.len () >= 8 { let trailer = u64 ::from_le_bytes (encoded_key[encoded_key.len () - 8 ..].try_into ().unwrap ()); encoded_key.resize (encoded_key.len () - 8 , 0 ); return Some (InternalKey { user_key: encoded_key, trailer, }); } None } pub fn encode (self ) -> Vec <u8 > { let mut encoded_key = self .user_key; encoded_key.extend_from_slice (&self .trailer.to_le_bytes ()); encoded_key }
trailer是一个u64,高位56bit保存sequence number,最后一个字节保存meta,目前只保存了key的类型标志。
在Rust中如果一个对象实现了Deref,编译器可以自动帮助该对象进行引用的类型转换,这样就是为什么函数参数一般用&str而不是用&String,因为&String可以被编译器自动转换成&str。为了让编译器让&InternalKey可以自动转换成&[u8],我们实现如下的DerefTrait。标准库中的Path、PathBuf、String、str和[u8]的引用都是Deref所以看到这些类型和函数的入参不一致的时候可以看看是不是有这个规则被编译器自动解引用了。
1 2 3 4 5 6 7 8 impl Deref for InternalKey { type Target = [u8 ]; fn deref (&self ) -> &Self ::Target { &self .content } }
在如下的代码中会方便很多,尽管参数是&[u8]但还是依旧可以用&InternalKey作为参数。
1 2 3 4 5 6 7 8 fn takes_slice (slice: &[u8 ]) { println! ("{:?}" , slice); } fn main () { let key = InternalKey::new (b"123" ); takes_slice (&key); }
但有些看起来可以自动deref的其实不行例如:&u64和&usize,因为usize不一定是64位的所以标准库没有实现AsDeref。
Sequence Number 我们的数据库目前没有完整的事务,但是提供了一定的读的一致性视图和批量写入的原子性,put key2成功之后在del key1之前失败了,
1 2 3 value = get key1 put key2 = value del key1
通过原子的批量写可以避免这个问题
1 2 3 4 5 value = get key1 wb = new write batch wb.del key1 wb.put key2 = value wb.write
只有全部写入以后seq才能增加,不然在数据库重新启动以后发现了大于commited的seq就会放弃重放这些数据。
原子批量写也可以得益于批量写的能力增加写入的带宽。
WriteBatch WriteBatch将多个写合并成一个写来实现原子性,格式如下。
开头是一个被所有entry共享的sequence,之后跟着一个u32的计数器。
1 2 3 +-------------+------------+--- ... ---+ | SeqNum (8B) | Count (4B) | Entries | +-------------+------------+--- ... ---+
每个entry的开头是一个byte的Kind(上文提到的Put,Del等类型标记),然后是一个或者两个varbytes,就是常见的varuint32的长度和对应N个字节的数据,取决于类型,例如删除就只有一个。
1 2 3 +-----------+-----------------+-------------------+ | Kind (1B) | Key (varstring) | Value (varstring) | +-----------+-----------------+-------------------+
Rust的实现如下:
1 2 3 pub struct Batch { entries: Vec <u8 >, }
设置count和sequence号,
1 2 3 4 5 6 7 fn set_count (&mut self , count: u32 ) { self .entries[8 ..12 ].copy_from_slice (&count.to_le_bytes ()); } pub fn set_seqnum (&mut self , seqnum: u64 ) { self .entries[..8 ].copy_from_slice (&seqnum.to_le_bytes ()); }
put操作,del操作也是类似的只是没有value,并且meta是类型不是Value而是Deletion。
1 2 3 4 5 6 7 8 9 10 pub fn put (&mut self , key: &[u8 ], value: &[u8 ]) { self .entries.push (InternalKeyKind::Value as u8 ); self .entries .extend_from_slice (&(key.len () as u32 ).to_varint_bytes ()); self .entries.extend_from_slice (key); self .entries .extend_from_slice (&(value.len () as u32 ).to_varint_bytes ()); self .entries.extend_from_slice (value); self .set_count (self .count () + 1 ); }
在WAL中保存WriteBatch Snapshot Snapshot提供一致性的读视图,本质是一个sequence生成器和管理器,任何大于snapshot的key都不会被读取,从而保证读的一致性(特别是在遍历的时候)。在获取的时候会使用sequence来搜索,小于该sequence的key不会被搜索到。
1 2 3 4 5 6 7 8 9 10 11 12 13 fn get_internal (&self , key: &[u8 ], seq: u64 ) -> Option <Vec <u8 >> { let lookup = InternalKey::new (key, seq, InternalKeyKind::Value); if let Some ((internal_key, value)) = self .mt.get_ge (&lookup.encode ()) { let internal_key = InternalKey::decode (internal_key).unwrap (); if internal_key.user_key == key && internal_key.trailer & 0xff != InternalKeyKind::Deletion as u64 { return Some (value); } } None }
内部比较器 InternalKey可以重载比较符,在一些场景下比较方便。&[u8]进行比较,这个时候重载比较符是不被允许的。
可以看到上面我们使用了get_ge代表搜索大于等于这个internal key的key。get_ge的方法,寻找第一个大于等于key的函数,SkipList的搜索过程中
1 2 3 4 5 6 7 std::cmp::Ordering::Greater => { if l == 0 { return Some ((next.borrow ().key.clone (), next.borrow ().value.clone ())); } break ; }
自定义比较函数,使用静态结构体保存函数集合。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 use std::{ cmp::{self , min, Ordering}, mem, }; #[derive(Clone, Copy)] pub struct Comparator { pub cmp: fn (&[u8 ], &[u8 ]) -> Ordering, } pub const INTERNAL_COMPARATOR: Comparator = Comparator { cmp: internal_cmp };pub (super ) fn internal_cmp (a: &[u8 ], b: &[u8 ]) -> Ordering { assert! (a.len () >= 8 ); assert! (b.len () >= 8 ); match &a[0 ..a.len () - 8 ].cmp (&b[0 ..b.len () - 8 ]) { Ordering::Less => Ordering::Less, Ordering::Greater => Ordering::Greater, Ordering::Equal => { let a_trailer = u64 ::from_le_bytes (a[a.len () - 8 ..].try_into ().unwrap ()); let b_trailer = u64 ::from_le_bytes (b[b.len () - 8 ..].try_into ().unwrap ()); b_trailer.cmp (&a_trailer) } } } pub const BYTEWISE_COMPARATOR: Comparator = Comparator { cmp: cmp::Ord ::cmp };
一个是默认的字节序比较器,一个是根据seq做降序比较的比较器,最后的一个字节是type,但是Comparator。
至于说为什么不定义成InternalKey的方法是因为,我们的比较
我们可以类似这样定义一个持有引用的对象然后给这种对象增加方法,
InternalComparator是包含UserComparator的这样就可以支持用户自定义的排序排序方式。
1 2 3 4 5 type InternalKeyRef = &[u8 ];impl InternalKeyRef { cmp (self , other: Other)... }
SSTable SSTable(Sorted String Table)是用于各种键值数据库(如LevelDB、RocksDB和Cassandra)的基本数据结构。它旨在高效地存储和检索键值对,同时保持不变性、键有序和基于磁盘存储的原则。
SSTable的内容通常由以下部分组成:
排序键值数据: SSTable主要包含按特定顺序排序的键值对,以实现键的范围查询和键的单一检索。其中,值和键通常为字符串或字节序列。
数据块: 数据块是SSTable中存储一系列键值对的部分,专门设计用于高效读取操作。每个块可以包含固定数量的键值对,并且通常会进行压缩以节省磁盘空间。
块缓存:块缓存是一个组件,旨在通过在内存中存储频繁访问的SSTable块来提高读取性能。
元数据块: SSTable通常还包括有关其自身基本信息的元数据,在文件版本、结构等方面提供帮助以正确管理和读取SSTable属性等详细信息。
索引块: 索引模块在快速数据检索方面起着关键作用,其中包含元数据和与之相关联的键引用信息,能够快速获取从特定文件偏移量到相应数据块之间映射关系,并支持高效随机访问特定键值对,索引块是一种元数据块。
布隆过滤器: 某些情况下,SSTable可能还会附带Bloom过滤器作为概率型数据结构来判断是否存在特定键,在查找操作期间允许系统跳过不必要I/O请求并减少磁盘读取次数。
压缩:SSTable中的压缩涉及到应用算法来减少数据块的大小。常用的压缩算法有Snappy、LZ4和zlib。
墓碑: 在支持删除功能的数据库中,SSTable可能会包括墓碑来标记已删除的密钥,并确保这些被删除密钥仍然被考虑进去以保持一致性。
文件格式: SSTable内容采用特定文件格式进行组织和编码,在不同数据库系统之间可能存在差异;该设计旨在实现高效读写操作及合并重叠SSTable、有效管理磁盘空间等压缩过程。
校验和: 一些SSTable可能包含校验和或哈希值,在读取操作期间验证数据完整性;校验和有助于确保存储或传输过程中没有损坏。
RocksDB中的SSTable 的格式如下:
LevelDB是每个block有一个专有的filter,但考虑到我们的sst文件的filter并不大,所以参考RocksDB的默认实现只用一个full filter。
每个SSTable的block的最大的大小是典型的和page大小一致的4K大小,在一般的数据库或者存储系统中都会使用这个大小,因为
目前我们先实现一个只有一个block的SSTable,规定SSTable的第一层只能是4K,先实现block内部的数据结构。后面我们可以扩展
我们希望Table有搜索的能力(使用于查找某个键的时候),也有遍历的能力(使用于归并的时候)。
搜索基于二分查找,读取每个restart的开头key作为比较的key,二分查找对应的restart(该restart是key所在的区间)然后遍历restart查找该key。
Data Block构建器 BlockBuilder对key的存储是前缀压缩的,对于有序的字符串来讲,这能极大的减少存储空间。但是却增加了查找的时间复杂度,为了兼顾查找效率,每隔K个key,leveldb就不使用前缀压缩,而是存储整个key,这就是重启点(restartpoint)。重启点不依赖之前的前缀读取完整的key,可以作为二分查找的分界点,合适的间隔是对压缩效率和查询效率的平衡。
1 2 3 4 5 6 <beginning_of_file> [data block 1] [meta block 1: filter block] [metaindex block] [Footer] <end_of_file>
其中一个block由多个restart构成。
1 2 3 restart 1 restart 2 restarts_length
每个restart由一个header和一对kv构成,plen表示和之前的key的共享长度的部分可以省略存储的空间,klen表示不共享的长度部分,
1 2 3 4 5 plen klen vlen key value
作为可选项,可以对block进行压缩,所以block后会追加一个字节表示压缩算法再追加一个crc32的校验值,总共要多5个字节。block data | type(1B) | crc32(4B)。
压缩 Snappy Snappy 是由 Google 开发的一种快速数据压缩和解压缩算法。
Snappy 的压缩算法基于一系列的变长编码和字典压缩。
Data Block读取
Block 结构
Block 结构包含两个字段,content 是块的二进制内容,restarts 是存储重启点偏移的数组。
Block::new 方法
通过 Read 实例读取整个块的内容。
解析末尾的重启点数量,获取重启点偏移数组。
截断块的内容,去除重启点信息,返回 Block 实例。
Block::restart_iter 方法
根据给定的重启点索引,初始化 RestartIterator 实例,用于迭代重启点范围内的条目。
计算重启点的起始和结束位置。
Block::iter 方法
返回 BlockIterator 实例,用于迭代整个块的内容。
将块的内容、重启点数组、以及迭代状态传递给 BlockIterator。
RestartIterator 迭代过程
迭代器按顺序遍历重启点范围内的条目。
每个条目由键和值组成,通过解析块内容的头部信息获取长度信息,依次读取键和值。
BlockIterator 迭代过程
迭代器按顺序遍历整个块的内容。
对于每个条目,解析块内容的头部信息,获取键和值的长度,依次读取键和值。
Block::get_ge 方法
使用二分查找在块的重启点中找到第一个大于等于给定键的位置。
通过迭代器查找该位置对应的键值对,返回找到的值。
Block::get 方法
使用二分查找在块的重启点中找到等于给定键的位置。
通过迭代器查找该位置对应的键值对,返回找到的值。
总体来说,块的读取过程通过迭代器实现对块内容的顺序访问,而二分查找用于在重启点中快速定位目标位置,提高查找效率。
统一Filter Block构建 分块的Filter Block构建 Full Filter适合SSTable的key比较少的情况,每个SSTable用一个full filter即可,如果SSTable的key较多的情况下,full filter一次性要load太多
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [filter 0] [filter 1] [filter 2] ... [filter N-1] [offset of filter 0] : 4 bytes [offset of filter 1] : 4 bytes [offset of filter 2] : 4 bytes ... [offset of filter N-1] : 4 bytes [offset of beginning of offset array] : 4 bytes lg(base) : 1 byte
这个设计在RocksDB里面被废弃了而采用了完整Filter Block。
布隆过滤器 LevelDB BloomFilter Double Hash
Bloom Filter的基本原理是,当一个元素被插入集合时,通过K个哈希函数将这个元素哈希成K个位置,然后将这些位置的位都设为1。检查一个元素是否在集合中时,通过同样的哈希函数找到K个位置,如果任何一个位置的位为0,则元素一定不在集合中;如果所有位置的位都为1,则元素可能在集合中。
在LevelDB中,Bloom Filter被用作SSTable的一部分,用于减少不必要的磁盘读取。当查找一个键时,首先使用Bloom Filter判断这个键是否可能在SSTable中,如果可能在,则进行磁盘读取;否则,直接跳过这个SSTable,从而减少了不必要的磁盘读取。
Bloom Filter的优点是空间效率和查询时间都极高,特别适合于元素数量巨大,但内存空间有限的场景。缺点是存在一定的误判率。
Bloom Filter本身是个bit vector,最后一个字节保存K的值。
在LevelDB的Bloom Filter中,使用了一种称为双重哈希(Double Hashing)的技术。这种技术的主要目的是为了解决哈希冲突,即当两个不同的输入产生相同的哈希值时,如何处理。
双重哈希的基本思想是,当哈希冲突发生时,不是简单地在哈希表中寻找下一个空闲位置,而是使用第二个哈希函数来确定探测序列。这个第二个哈希函数会根据输入的键值生成一个新的哈希值,这个新的哈希值会与原始的哈希值结合在一起,用于确定在哈希表中的位置。
在LevelDB的Bloom Filter中,双重哈希的实现方式是,首先使用一个哈希函数将键值哈希到Bloom Filter的某个位置,然后使用第二个哈希函数生成一个新的哈希值,这个新的哈希值用于确定在Bloom Filter中的第二个位置。这样,每个键值在Bloom Filter中都会对应两个位置,大大降低了哈希冲突的可能性,从而提高了Bloom Filter的效率和准确性。
在Bloom Filter中,K值表示我们使用的哈希函数的数量。如果K值大于2,我们将对每个插入的元素应用K个哈希函数,然后在Bloom Filter中设置对应的K个位置。
以下是一个简单的例子,假设我们有一个空的Bloom Filter,长度为m,和3个哈希函数(即K=3)。当我们插入一个元素时,我们将对这个元素应用这3个哈希函数,得到3个哈希值。然后,我们将这3个哈希值对m取模,得到在Bloom Filter中的3个位置,然后将这3个位置的位都设为1。
当我们要检查一个元素是否在集合中时,我们也会对这个元素应用这3个哈希函数,得到3个哈希值,然后查看Bloom Filter中对应的3个位置。如果这3个位置的位都为1,那么我们认为这个元素可能在集合中;如果这3个位置中有任何一个位为0,那么这个元素肯定不在集合中。
需要注意的是,随着K值的增大,误判率会降低,但是插入和查询的时间复杂度也会增大。因此,选择合适的K值是一个需要权衡的问题。
如果你有很多点查找操作(例如Get()),那么Bloom Filter可以帮助加速这些操作,相反,如果你的大部分操作是范围扫描(例如Scan()),那么Bloom Filter就没有帮助了。因为Range两端的两个key可能不存在,这样过滤器就不会生效了,大部分情况下都退化成了一次搜索大于左边界的键和从当前位置遍历直到超过右边界。
murmurhash有比较好的平衡分布的特性,计算速度快也比较简单,LevelDB使用的是最简单的murmur1。他之所以叫murmur的原因是因为他的算法就是两次乘法(multiply)和右移操作(Right shift),在版本三种这个R其实是(Rotate Left)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 fn murmur1 (bytes: &[u8 ], seed: u32 ) -> u32 { let m : u32 = 0xc6a4a793 ; let r = 24 ; let mut h : u32 = 0 ; let mut h : u32 = seed ^ (bytes.len () as u32 ).wrapping_mul (m); for chunk in bytes.chunks (4 ) { if chunk.len () == 4 { let w = u32 ::from_le_bytes ([chunk[0 ], chunk[1 ], chunk[2 ], chunk[3 ]]); h = h.wrapping_add (w); h = h.wrapping_mul (m); h ^= h >> 16 ; } else { for (i, &b) in chunk.iter ().enumerate () { h += u32 ::from (b) << (i * 8 ); } h = h.wrapping_mul (m); h ^= h >> r; } } h }
LevelDB使用Double Hashing模拟多个哈希函数。第一个函数是一个类似murmur的hash函数,而第二个函数则是一个将后15bit和前17bit兑换的简单函数。数据结构包含一个k用来标记hash函数的个数,bits用来保存bit数组。
1 2 3 4 pub struct BloomFilter { bits: Vec <u8 >, k: usize , }
Index Block Index Block 的 key,按照RocksDB 的Wiki,
经历了几次优化比如把 first encode 到value中,这次就不做这个实现。
理论上用 last key 就可以,但是为了减小大小可以优化一下选择一个较小的key。
比如 [0,1,2] 和 [0,2,3] 当中 [0,1,2]和[0,2]都满足要求。
shortestseperator
shortestseperator是比较器的一部分,在这里作为index block的切分作用,所以在这里做介绍。shortest_separator的功能:找到一个最字节串介于两个key或者边界之间。+1的字节(小于255),然后
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 fn shortest_separator (start: &mut Vec <u8 >, limit: &[u8 ]) { let min_length = min (start.len (), limit.len ()); let mut diff_index = 0 ; while diff_index < min_length && start[diff_index] == limit[diff_index] { diff_index += 1 ; } if diff_index < min_length { let diff_byte = start[diff_index]; if diff_byte < 255 && diff_byte + 1 < limit[diff_index] { start[diff_index] += 1 ; start.resize (diff_index + 1 , 0 ); } } }
如果是内部key的话,如果分割者比sart短的话,就要完善这个内部ke的构成,我们需要补上一个MAX_SEQUENCE_NUMBER << 8 | ValueType::TypeForSeek as u64,这样就可以保证分割者比start大。TypeForSeek表示这个key并没有代表使用的key,而是在index block中起索引作用的key。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 fn internal_shortest_separator (start: &mut Vec <u8 >, limit: &[u8 ]) { assert! (start.len () >= 8 ); assert! (limit.len () >= 8 ); let l = &start[0 ..start.len () - 8 ]; let j = &limit[0 ..limit.len () - 8 ]; let mut tmp = l.to_vec (); (UserKeyComparator.separator)(&mut tmp, j); if tmp.len () < l.len () { let pack = MAX_SEQUENCE_NUMBER << 8 | ValueType::TypeForSeek as u64 ; tmp.extend_from_slice (pack.to_le_bytes ().as_ref ()); assert! (internal_cmp (start, &tmp) == Ordering::Less); assert! (internal_cmp (&tmp, limit) == Ordering::Less); mem::swap (start, &mut tmp); } }
TableBuilder SSTable是不可修改的,只存在创建和删除。
Option 用于管理选项,例如restart_block_interval,block_size等。
TableReader block的设计有一个好处可以根据block index去读取block。
Block Cache LRU Cache 需要一个队列和HashMap并且,为了缓解缩的压力也可以对key分片做分段锁。
Index 和 Filter Cache 会把level0的index block 和 filer block 缓存起来。
块缓存用来来缓存未压缩的数据块,它的大小一般来说可以是总内存预算的1/3左右。
LRU Cache 为了加速读取可以将最近使用的一些Table缓存到内存中加速Table的加载。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 pub struct LRUCache <K, V> { map: HashMap<K, V>, order: VecDeque<K>, capacity: usize , } impl <K: Clone + Eq + Hash, V> LRUCache<K, V> { pub fn new (capacity: usize ) -> Self { LRUCache { map: HashMap::with_capacity (capacity), order: VecDeque::with_capacity (capacity), capacity, } } pub fn get_or_insert_with <F: FnOnce () -> V>(&mut self , key: &K, f: F) -> &V { if self .map.contains_key (key) { self .refresh (key); self .map.get (key).unwrap () } else { self .put (key.clone (), f ()); self .map.get (key).unwrap () } } pub fn put (&mut self , key: K, value: V) { if self .map.contains_key (&key) { self .refresh (&key); } else { if self .map.len () == self .capacity { if let Some (oldest) = self .order.pop_back () { self .map.remove (&oldest); } } self .order.push_front (key.clone ()); } self .map.insert (key, value); } fn refresh (&mut self , key: &K) { if let Some (position) = self .order.iter ().position (|k| k == key) { let key = self .order.remove (position).unwrap (); self .order.push_front (key); } } }
Block Cache TODO
Table Cache 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 pub struct TableCache { cache: LRUCache<u64 , Table<File>>, opt: Options, } impl TableCache { fn new (opt: Options) -> Self { Self { cache: LRUCache::new (100 ), opt, } } fn get_table (&mut self , file_num: u64 ) -> &Table<File> { self .cache.get_or_insert_with (&file_num, ||{ let file = std::fs::OpenOptions::new () .read (true ) .open (format! ("{}.sst" , file_num)) .unwrap (); Table::from_reader (file, self .opt).unwrap () }) } }
MANIFEST MANIFEST也是一个基于record的日志。
相关文件的管理 lognum 用来创建 log 文件。
当 manifest 文件超过一定大小后会进行压缩,按照全部新建的 edit 进行追加写。
不需要 version,维护一个 table 的引用计数(rc),当 rc 为 0 时就删除。
需要将 manifest 转换成符合重放的追加写的 edit,这样在重放时可以恢复成原本的 manifest。
合并 合并的基本思想是:数据按多个level组织,目标大小呈指数级增长,例如level0的SSTable的大小是4MB的话,
minor compaction 和 major compaction
寻找level,选择自身大小除以目标大小的比率最大的level。
在合适的level中挑选合适的文件,比如和下级文件重叠最多的文件,节省空间。
将文件与下一个level的文件(可能多个)进行归并排序组合成新的文件(可能多个),同时之前的墓碑值也可以在合并的时候顺带删除掉。
Major Compaction主要有三种分别为:
Manual Compaction,是人工触发的Compaction,由外部接口调用产生。
Size Compaction,是根据每个level的总文件大小来触发,注意Size Compation的优先级高于Seek Compaction。
Seek Compaction,每个文件的 seek miss 次数都有一个阈值,如果超过了这个阈值,那么认为这个文件需要Compact。
compact_pointer 就是 round robin的标记,如果没找到就从第一个文件开始。LevelDB挑选文件的方式很简单。
读写存储放大 读写存储放大(Read/Write/Space Amplification)是数据库系统中一个重要的性能问题,特别是对于基于磁盘的存储引擎。
我们衡量读写存放大的指标是这么计算的:
读放大:读取过程中读取的全部数据/实际读取本身所需要的数据。
写放大:写入过程中写入的全部数据/实际写入本身所需要的数据。
存放大:存储数据占用的磁盘空间/实际存储的数据本身占用的磁盘空间。
数据库的大量优化除了操作执行的时间之外,很重要的性能指标就是这些“放大”,合并当中的很多优化都是围绕它们展开的。
Version Version中的level的映射可以使用Vec,files是有序的也只需要一个Vec,然后根据file的Smallest和Largest的Key做二分搜索既可以。
Version一个引用计数器,读的时候Ref,读结束的时候UnRef,当没有引用的时候从VersionSet当中删除。
Verion和Compaction的关系是一对一的。
LevelDB在合并和打开数据库的时候会删除不需要的文件,这个不需要是通过live_files获取的。
合并涉及到删除操作,但是可能当前有相关文件的读操作还没有结束,所以我们希望在没有引用的情况下再删除改文件。
Version相较于MANIFEST是内存中的对象,每次重启以后只会初始化一个只有一个Version的VersionSet。
1 2 /// VersionSet managed the various versions that are live within a database. A single version /// contains references to the files on disk as they were at a certain point.
版本保存了当前LSM结构的元信息,版本信息对应的是每个level有哪些文件存在,删除的文件不会立即删除
如果有读事务位于旧的文件,那么暂时就不能删除。因此利用引用计数,只要一个Verison还活着,就不允许删除该Verison管理的所有文件。当一个Version生命周期结束,它管理的所有文件的引用计数减1。
当sst文件不再被“活着”的版本引用的时候就可以删除对应的文件了。
有几种情况
重启的时候对log的重放
minor compaction
major compaction 没有文件合并
major compaction 有文件合并
VersionEdit会以追加写的Record形式追加到manifest当中。
这样重放的时候不需要全部堆到level0。
sst_0
MANIFEST文件和LOG文件一样,只要DB不关闭,这个文件一直在增长。我查看了我一个线上环境,MANIFEST文件已经膨胀到了205MB。
试试上,随着时间的流逝,早期的版本是没有意义的,我们没必要还原所有的版本的情况,我们只需要还原还活着的版本的信息。MANIFEST只有一个机会变小,抛弃早期过时的VersionEdit,给当前的VersionSet来个快照,然后从新的起点开始累加VerisonEdit。这个机会就是重新开启DB。
LevelDB的早期,只要Open DB必然会重新生成MANIFEST,哪怕MANIFEST文件大小比较小,这会给打开DB带来较大的延迟。
在系统(重新)启动时,最新的清单日志(manifest log)包含了数据库的一致状态。任何后续变化都会被记录到清单日志文件中。
Version和FileMetadata是多对1的,当没有Version引用这个FileMetadata的时候就可以删除对应的文件。
也可以通过比较当前Version和数据库目录下的文件删除不需要的,这个在数据库重启的时候比较有用。
VersionEdit VersionEdit是一次修改的记录,apply一次VersionEdit以后会生成一个新的Version。
1 2 3 4 +-------------+------ ......... ----------+ | Record ID | Variable size record data | +-------------+------ .......... ---------+ <-- byte --->|<-- varies by type -->
例如删除文件 RecordID 为 DeleteFile,保存了删除了哪个level的文件号。
1 2 3 4 5 6 Mark a file as deleted from database. +-----------------+-------------+--------------+ | kDeletedFile | level | file number | +-----------------+-------------+--------------+ <-- byte --->|<-- Var32 -->|<-- Var64 -->|
1 2 // The MANIFEST file describes the startup state of the db -- all LSM files and what level they're // at.
manifest记录了两个主要对象 levels 和 table。
changeSet 在rocksdb里面叫 versionedit
Manifest -> version
Levels 表示每个level包含的table信息,是一个数组,每个数组的元素是一个 table id的set。
这样根据 level 可以查找所包含的table,根据table id 可以查找所包含的 level 和 checksum。
level是从零开始连续的所以是个数组。
VersionEdit还有两个指标allowed_seeks和compaction_ptrs,一个代表的是seek操作的次数如果过多某种程度上代表了
VersionBuilder Version是一个静态只读的数据结构,当我们需要从一个Version转换成另外一个Version的时候,Version Builder这个Builder会将Version的file拷贝成map然后
除此之外这个
deleted_file上是一个file num的Set
VersionSet VersionSet是一个双向循环链表,但是在Rust中没有比较好的办法不用unsafe实现head.next=head,所以不得不用指针了。
其实不需要这个循环链表,交给Rust的ref去管理就行了。
FileMetadata不是和file一一映射的不能靠file metadata来回收。
链表还是有用的,得查找所有的存活的version。
合并时选择Level 选择文件是一个可以调优的选择,LevelDB用一个单线程的后台进程进行非常简单的RoundRobin轮询挑选。 Compaction操作在key空间中循环执行,详细讲一点就是,对于每个level,我们记录上次compaction的ending key。Level的下一次compaction将选择ending key之后的第一个文件(如果这样的文件不存在,将会跳到key空间的开始)。
这里我们考虑挑选文件的情况:
如果一个文件和下一级的N个文件有交集那么写放到就是近似于N倍,所有的N个文件都会被重写。kOldestSmallestSeqFirst 这里的Oldest代表最老,Smallest代表的是时间戳表示最老的更新。
另一种情况是热点键,选择最新更新是最老的文件,则代表的是最“冷”的文件,这样可以减少热点键向下一级移动。kOldestLargestSeqFirst 这里的Oldest代表最老,Largest代表的是时间戳表示最新的更新。
如果一个文件包含很多墓碑值,它可能会减慢迭代该区域的速度,因为我们仍然需要在合并的时候迭代那些墓碑键。此外,我们越早将墓碑键压缩到最后一层,就能越早回收磁盘空间,因此这有利于提高空间效率。
我们的默认压缩优先级kByCompensatedSize考虑了这种情况。如果文件中的删除(插入墓碑)次数超过插入次数,则更有可能选择该文件进行压缩。删除次数超过插入次数越多,它就越有可能被压缩。这个选项一般是为了解决数据库中有大量的键被删除导致的空间浪费和读放大。
BadgerDB选择的不太一样,是选择最少的overlap,然后这样重写的量最少写放大就会比较少。
我们的实现使用kOldestSmallestSeqFirst这个参数,按照RocksDB的设计。
RocksDB中关于合并的配置
1 2 3 4 cf_options.level_compaction_dynamic_level_bytes = true; opts.max_background_jobs = 6; options.bytes_per_sync = 1048576; options.compaction_pri = kMinOverlappingRatio;
合并是在后台进行的,level0一般都比较小,允许键有重叠,保存在MemTable中。
合并的参与者是两个level,挑选两个level的算法是一个可选项。total_size / target_size 最大那么就应该被选为合并对象。我们的理想情况应该是两个level合并之后文件的总大小减少最多,或者是让读放大减少。
选定上下两层level以后寻找overlap的部分进行归并排序。
合并完成之后会删除不需要的文件。
动态的Level尺寸 dynamic level size 。
例如,假设max_bytes_for_level_multiplier=10,num_levels=6,以及max_bytes_for_level_base=10MB。
因为level 1到4的目标尺寸不适用,所以它们将不会被使用。
随着数据的累积,尺寸目标根据level 5的实际数据进行调整。当level 5的数据达到50MB时,目标是这样的:
直到level 5的实际大小超过100MB,例如101MB。如果我们继续保持level 4作为基础级别,
1 [- - 1.01MB 10.1MB 101MB]
同样,当level 5进一步增长时,所有级别的目标也增长,如下所示:
直到level 5超过1000MB并变为1001MB,我们将level 2作为基础级别,
1 [- 1.001MB 10.01MB 100.1MB 1001MB]
依此类推…
具体可以参考leveled compaction
选择合并文件的边界 当选择文件以后我们需要划分出一个“干净的”边界(亦称clean cut或atomic compaction unit)。
提取来自 |compaction_files| 的最大文件 b1,然后在 |level_files| 中搜索一个文件 b2, user_key(u1) = user_key(l2)。如果找到这样的文件 b2(称为边界文件),则将其添加到 |compaction_files| 中,然后使用这个新的上限再次进行搜索。
之所以这样做的原因是因为:如果存在两个块,b1=(l1, u1) 和 b2=(l2, u2),并且 user_key(u1) = user_key(l2),如果我们压缩了 b1 但没有压缩 b2,那么后续的获取操作将产生不正确的结果(我们保持的恒定的性质:同一个user key,i层的seqnum要高于i+1层的seqnum,并且seqnum降序排序的),因为它将在第 i 层返回来自 b2 的记录而不是来自 b1,也就是b2的seqnum的key把b1中seqnum更大的key给“盖”住了。
在LevelDB当中,文件会”向右“扩展,视图去包含边界上的user key的更低的seqnum(内部key的seqnum是降序排序的)。在其他基于LevelDB的数据库中加入了一些优化。
重叠的分布 但我们讨论写放大的时候就需要考虑重叠的分布,如果一个重叠的分布比较均匀,那么范围越大重叠的文件就会越多。
RocksDB针对key的分布不均匀有一些优化,这里我们还是记住一个LevelDB的隐含考量:key的分布是均匀的,重叠越多~文件的写放大越大。
Trivial move “Trivial move” 是 LevelDB 在执行合并操作时的一个优化策略。如果一个文件在转移到下一层时,并不与下一层的任何文件有重叠,那么这个文件的移动就被认为是 “trivial” 的,即不需要进行复杂的合并操作,可以直接移动文件。这样做的好处是减少了不必要的数据复制,从而提高了整体的性能。另外补充一点:BadgerDB
为了利用这个”trivial”移动的优化还需要记录”grandparents”(也就是level i+2)层的重叠文件,LevelDB 通过判断待移动的文件是否与其 “grandparents level” 中的文件有大量 重叠来决定是否进行 “trivial move”。如果没有大量重叠,就可以直接移动文件,而不需要合并。这种策略有效地减少了I/O操作和提高了性能,特别是在处理大量数据时。这个大量在LevelDB里面是10*max_file_size(这里的10是每个层级的倍数),默认是25MB。
多路合并 从level到level+1需要对多个文件进行归并排序输出一个新的level+1的文件。我们要定义一个多路的归并器来处理这个问题。
创建一个CompactionState保存TableBuilder和outputfile
VersionSet MakeInputIterator
需要的Iterator的数量:
level 0 合并成一个 +1 = 2
leve > 0 的 size 1= size +1
文件的删除 到目前为止我们的数据库都没有涉及任何的文件删除的能力,所有的老文件都还存在着,当前使用的文件被记录在log当中。
当文件不再被引用的时候既可以删除,或者当Version被释放的时候比较current和目录中的文件集中清楚。
通过重载Drop,可以实现在FileMetadata没有被引用的时候删除这个文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 use std::fs;use std::path::PathBuf;use std::rc::Rc;use std::io;struct TempFile { path: PathBuf, } impl TempFile { pub fn new (path: PathBuf) -> Rc<Self > { Rc::new (TempFile { path }) } } impl Drop for TempFile { fn drop (&mut self ) { match fs::remove_file (&self .path) { Ok (()) => println! ("File {:?} was deleted successfully." , self .path), Err (e) => eprintln! ("Error deleting file {:?}: {}" , self .path, e), } } } fn main () -> io::Result <()> { let temp_path = PathBuf::from ("my_temp_file.txt" ); fs::write (&temp_path, "Temporary file contents" )?; let temp_file = TempFile::new (temp_path.clone ()); let temp_file_clone = Rc::clone (&temp_file); drop (temp_file); assert_eq! (fs::metadata ("my_temp_file.txt" ).is_ok (), true ); drop (temp_file_clone); assert_eq! (fs::metadata ("my_temp_file.txt" ).is_ok (), false ); Ok (()) }
扩展 Range Delete 在一些将键值数据库作为基础数据库的一些分布式数据库中涉及到删表操作。
干净的边界 TODO
事务 TODO
总结 实现LevelDB的过程中,体会到了Rus的很多语法糖和特性,和Go还有Python之间都有相互借鉴,是一个不吝啬引入语言语法复杂性的语言。