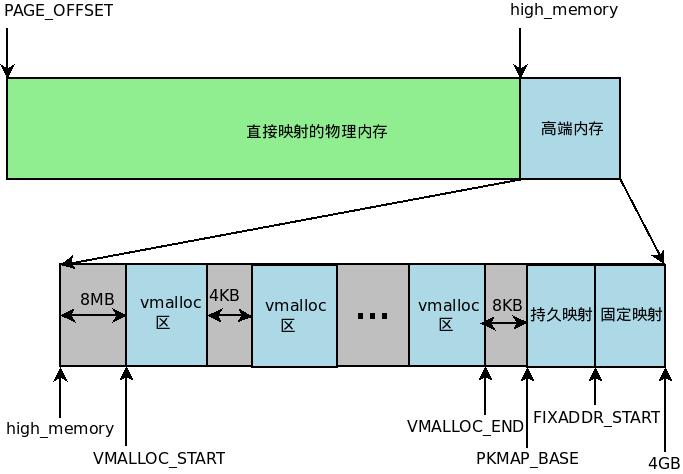
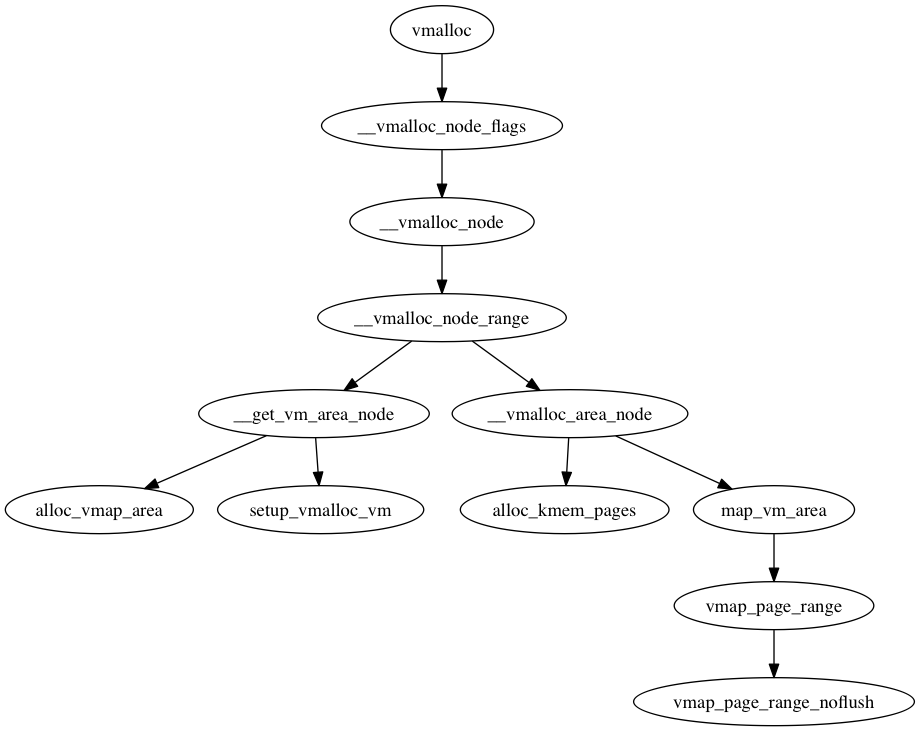
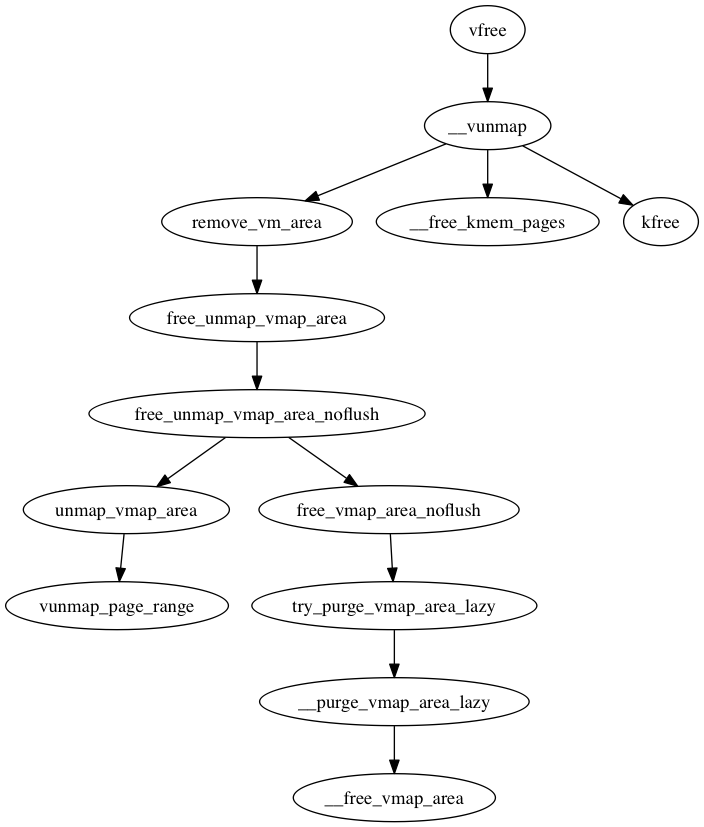
cgroup 是容器当中对资源进行限制的机制,完整的名称是叫 control group。经常提到的 hierarchy 对应的是一个层级,而subsystem 对应的是一个子系统,都是可以望文生意的。创建一个层级是通过挂载完成的,也就是说层级对应的是文件系统 root 目录的结构。
子系统目前有下列几种
devices 设备权限
cpuset 分配指定的 CPU 和内存节点
cpu 控制 CPU 占用率
cpuacct 统计 CPU 使用情况
memory 限制内存的使用上限
freezer 暂停 Cgroup 中的进程
net_cls 配合 tc(traffic controller)限制网络带宽
net_prio 设置进程的网络流量优先级
huge_tlb 限制 HugeTLB 的使用
perf_event 允许 Perf 工具基于 Cgroup 分组做性能检测
创建层级通过 mount -t cgroup -o subsystems name /cgroup/name,/cgroup/name 是用来挂载层级的目录(层级结构是通过挂载添加的),-o 是子系统列表,比如 -o cpu,cpuset,memory,name 是层级的名称,一个层级可以包含多个子系统,如果要修改层级里的子系统重新 mount 即可。子系统和层级之间满足几个关系。
/proc/[pid]/cgroup (since Linux 2.6.24) This file describes control groups to which the process/task belongs. For each cgroup hierarchy there is one entry containing colon-separated fields of the form:
5:cpuacct,cpu,cpuset:/daemons
The colon-separated fields are, from left to right:
1. hierarchy ID number
2. set of subsystems bound to the hierarchy
3. control group in the hierarchy to which the process belongs
This file is present only if the CONFIG_CGROUPS kernel configuration option is enabled.
这个展示的是当前进程属于的 control groups, 每一行是一排 hierarchy,中间是子系统,最后是受控制的 cgroup,可以通过这个文件知道自己所属于的cgroup。
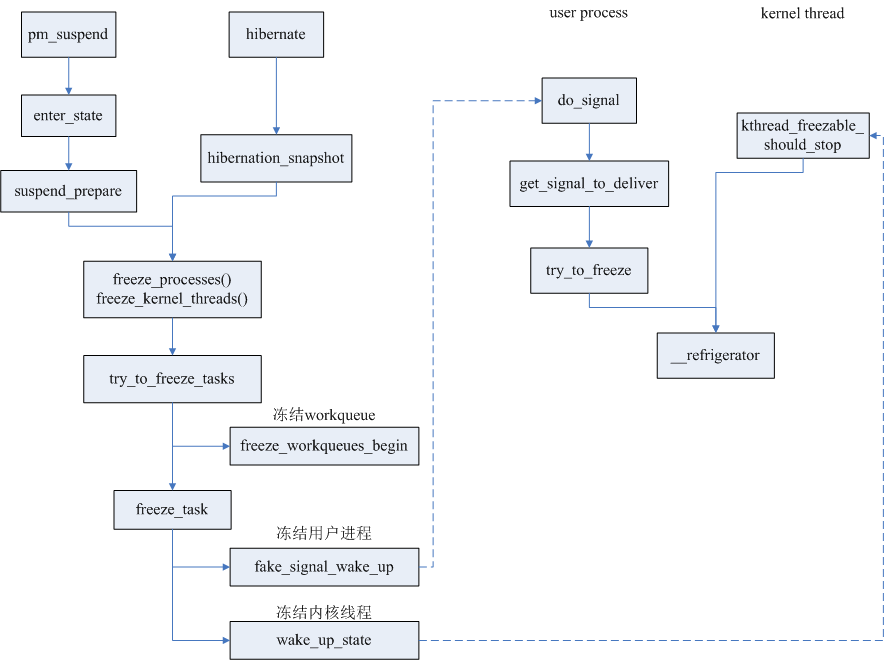
/* Refrigerator is place where frozen processes are stored :-). */ void refrigerator(void) { /* Hmm, should we be allowed to suspend when there are realtime processes around? */ long save;
task_lock(current); if (freezing(current)) { frozen_process(); task_unlock(current); } else { task_unlock(current); return; } save = current->state; pr_debug("%s entered refrigerator\n", current->comm); spin_lock_irq(¤t->sighand->siglock); recalc_sigpending(); /* We sent fake signal, clean it up */ spin_unlock_irq(¤t->sighand->siglock); /* prevent accounting of that task to load */ current->flags |= PF_FREEZING; for (;;) { set_current_state(TASK_UNINTERRUPTIBLE); if (!frozen(current)) break; schedule(); }
/* Remove the accounting blocker */ current->flags &= ~PF_FREEZING;
pr_debug("%s left refrigerator\n", current->comm); __set_current_state(save); }
if (!cgroup_lock_live_group(cgroup)) return -ENODEV;
freezer = cgroup_freezer(cgroup); spin_lock_irq(&freezer->lock); state = freezer->state; if (state == CGROUP_FREEZING) { /* We change from FREEZING to FROZEN lazily if the cgroup was * only partially frozen when we exitted write. */ update_freezer_state(cgroup, freezer); state = freezer->state; } spin_unlock_irq(&freezer->lock); cgroup_unlock();
bool freeze_task(struct task_struct *p, bool sig_only) { /* * We first check if the task is freezing and next if it has already * been frozen to avoid the race with frozen_process() which first marks * the task as frozen and next clears its TIF_FREEZE. */ if (!freezing(p)) { rmb(); /* 如果frozen标记了 * 说明已经冻结,就返回失败 */ if (frozen(p)) return false;
if (!sig_only || should_send_signal(p)) set_freeze_flag(p); else return false; }
if (should_send_signal(p)) { if (!signal_pending(p)) fake_signal_wake_up(p); } else if (sig_only) { return false; } else { wake_up_state(p, TASK_INTERRUPTIBLE); }
Linux is a multi-user operating system. Consider a scenario where user A spawns ten tasks and user B spawns five. Using the above approach, every task would get ~7% of the available CPU time within a scheduling period. So user A gets 67% and user B gets 33% of the CPU time during their runs. Clearly, if user A continues to spawn more tasks, he can starve user B of even more CPU time. To address this problem, the concept of “group scheduling” was introduced in the scheduler, where, instead of dividing the CPU time among tasks, it is divided among groups of tasks.
总结来说 CPU 的时间并不是分给独立的 task 的,而是分给 task_group 的,这样防止用户 A 的进程数远远大于 B 而导致 B 饥饿的情况。这一组task通过 sched_entity 来表示。能够导致进程分组的方式一种是把进程划入一个cgroup,一种是通过set_sid()系统调用的新session中创建的进程会自动分组,这需要CONFIG_SCHED_AUTOGROUP编译选项开启。
#ifdef CONFIG_FAIR_GROUP_SCHED struct sched_entity *parent; /* rq on which this entity is (to be) queued: */ struct cfs_rq *cfs_rq; /* rq "owned" by this entity/group: */ struct cfs_rq *my_q; #endif };
每个调度实体都有两个cfs_rq结构
1 2 3 4 5 6 7
struct cfs_rq { struct load_weight load; unsigned long runnable_load_avg; unsigned long blocked_load_avg; unsigned long tg_load_contrib; /* ... */ };
Each scheduling entity may, in turn, be queued on a parent scheduling entity’s run queue. At the lowest level of this hierarchy, the scheduling entity is a task; the scheduler traverses this hierarchy until the end when it has to pick a task to run on the CPU.
Tasks belonging to a group can be scheduled on any CPU. Therefore it is not sufficient for a group to have a single scheduling entity; instead, every group must have one scheduling entity for each CPU. Tasks belonging to a group must move between the run queues in these per-CPU scheduling entities only, so that the footprint of the task is associated with the group even during task migrations.
对于cpu.cfs_period_us和cpu.cfs_quota_us,是关于CPU bandwith的内容,论文CPU bandwidth control for CFS详细描述了其中的设计。论文中举例提到,shares 值只是使得CPU 的时间能够平均分配,但是实际运行时间可能会有变化,不能限制一个进程运行的上限。
/* track cpu usage of a group of tasks and its child groups */ struct cpuacct { struct cgroup_subsys_state css; /* cpuusage holds pointer to a u64-type object on every cpu */ u64 __percpu *cpuusage; struct kernel_cpustat __percpu *cpustat; };
/* * charge this task's execution time to its accounting group. * * called with rq->lock held. */ void cpuacct_charge(struct task_struct *tsk, u64 cputime) { struct cpuacct *ca; int cpu; /* 获取当前task属于的cpu */ cpu = task_cpu(tsk);
/* * Add user/system time to cpuacct. * * Note: it's the caller that updates the account of the root cgroup. */ void cpuacct_account_field(struct task_struct *p, int index, u64 val) { struct kernel_cpustat *kcpustat; struct cpuacct *ca;
rcu_read_lock(); ca = task_ca(p); while (ca != &root_cpuacct) { kcpustat = this_cpu_ptr(ca->cpustat); kcpustat->cpustat[index] += val; ca = __parent_ca(ca); } rcu_read_unlock(); }
struct cpuset { struct cgroup_subsys_state css; unsigned long flags; /* "unsigned long" so bitops work */ cpumask_var_t cpus_allowed; /* CPUs allowed to tasks in cpuset */ nodemask_t mems_allowed; /* Memory Nodes allowed to tasks */ struct fmeter fmeter; /* memory_pressure filter */ /* * Tasks are being attached to this cpuset. Used to prevent * zeroing cpus/mems_allowed between ->can_attach() and ->attach(). */ int attach_in_progress; /* partition number for rebuild_sched_domains() */ int pn; /* for custom sched domain */ int relax_domain_level; struct work_struct hotplug_work; };
Setting the flag ‘cpuset.memory_spread_page’ turns on a per-process flag PFA_SPREAD_PAGE for each task that is in that cpuset or subsequently joins that cpuset. The page allocation calls for the page cache is modified to perform an inline check for this PFA_SPREAD_PAGE task flag, and if set, a call to a new routine cpuset_mem_spread_node() returns the node to prefer for the allocation.
Similarly, setting ‘cpuset.memory_spread_slab’ turns on the flag PFA_SPREAD_SLAB, and appropriately marked slab caches will allocate pages from the node returned by cpuset_mem_spread_node().
/* * The caller (fork, wakeup) owns p->pi_lock, ->cpus_allowed is stable. */ static inline int select_task_rq(struct task_struct *p, int sd_flags, int wake_flags) { int cpu = p->sched_class->select_task_rq(p, sd_flags, wake_flags); /* * In order not to call set_task_cpu() on a blocking task we need * to rely on ttwu() to place the task on a valid ->cpus_allowed * cpu. * * Since this is common to all placement strategies, this lives here. * * [ this allows ->select_task() to simply return task_cpu(p) and * not worry about this generic constraint ] */ if (unlikely(!cpumask_test_cpu(cpu, tsk_cpus_allowed(p)) || !cpu_online(cpu))) cpu = select_fallback_rq(task_cpu(p), p);
简单说一下[sched_domain](https://www.ibm.com/developerworks/cn/linux/l-cn-schldom/ sched domain 的详细内容)的作用,其实就是划定了负载均衡的 CPU 范围,默认是有一个全局的sched_domain,对所有 CPU 做负载均衡的,现在再划分出一个sched_domain把 CPU 的某个子集作为负载均衡的单元。 每个 Scheduling Domain 其实就是具有相同属性的一组 CPU 的集合. 并且跟据 Hyper-threading, Multi-core, SMP, NUMA architectures 这样的系统结构划分成不同的级别,不同级之间通过指针链接在一起, 从而形成一种的树状的关系, 如下图所示。
调度器会调用partition_sched_domains()来更新自己的scehd_domains,调度域发生作用的地方是在时钟中断的时候会触发SCHED_SOFTIRQ对任务做迁移,或者p->sched_class->select_task_rq,会在选择运行 CPU 时进行抉择,看一下 CFS 的实现的select_task_rq的简化流程
// 向上遍历更高层次的domain,如果发现同属一个domain // 就是affine目标 for_each_domain(cpu, tmp) { /* * If both cpu and prev_cpu are part of this domain, * cpu is a valid SD_WAKE_AFFINE target. */ if (want_affine && (tmp->flags & SD_WAKE_AFFINE) && cpumask_test_cpu(prev_cpu, sched_domain_span(tmp))) { affine_sd = tmp; break; }
if (tmp->flags & sd_flag) sd = tmp; } // 如果上面的条件满足,从prev_cpu中选出一个idle的new_cpu来运行. if (affine_sd) { if (cpu != prev_cpu && wake_affine(affine_sd, p, sync)) prev_cpu = cpu; // 在同一个级别的sched domain向下找到一个idle的CPU. new_cpu = select_idle_sibling(p, prev_cpu); // 快速路径,有idle的CPU就不用负载均衡了. goto unlock; } // 遍历层级 while (sd) { // 找到负载最小的CPU group = find_idlest_group(sd, p, cpu, load_idx); if (!group) { sd = sd->child; continue; }
new_cpu = find_idlest_cpu(group, p, cpu); /* 如果最闲置的CPU没有变的话,或者没有找到的话,就向下遍历. if (new_cpu == -1 || new_cpu == cpu) { /* Now try balancing at a lower domain level of cpu */ sd = sd->child; continue; }
/* Now try balancing at a lower domain level of new_cpu */ cpu = new_cpu; weight = sd->span_weight; sd = NULL; // 如果选出的节点weight比其他节点都大的话. // 再向下一个层级遍历. for_each_domain(cpu, tmp) { if (weight <= tmp->span_weight) break; if (tmp->flags & sd_flag) sd = tmp; } /* while loop will break here if sd == NULL */ }
负载均衡的对象有个例外。
CPUs in “cpuset.isolcpus” were excluded from load balancing by the isolcpus= kernel boot option, and will never be load balanced regardless of the value of “cpuset.sched_load_balance” in any cpuset.
/* * The core object. the cgroup that wishes to account for some * resource may include this counter into its structures and use * the helpers described beyond */
struct res_counter { /* * the current resource consumption level */ unsigned long long usage; /* * the maximal value of the usage from the counter creation */ unsigned long long max_usage; /* * the limit that usage cannot exceed */ unsigned long long limit; /* * the limit that usage can be exceed */ unsigned long long soft_limit; /* * the number of unsuccessful attempts to consume the resource */ unsigned long long failcnt; /* * the lock to protect all of the above. * the routines below consider this to be IRQ-safe */ spinlock_t lock; /* * Parent counter, used for hierarchial resource accounting */ struct res_counter *parent; };
获取方式是通过该结构相关的封装接口提供的,比如mem_cgroup_usage就是通过res_counter_red_u64来获取对应的res_counter的RES_USAGE对应的值的,也就是unsigned long long usage这个成员。(如果不是root,还会递归获取rss和page cache的合。
static inline u64 mem_cgroup_usage(struct mem_cgroup *memcg, bool swap) { u64 val; if (!mem_cgroup_is_root(memcg)) { if (!swap) return res_counter_read_u64(&memcg->res, RES_USAGE); else return res_counter_read_u64(&memcg->memsw, RES_USAGE); } /* * Transparent hugepages are still accounted for in MEM_CGROUP_STAT_RSS * as well as in MEM_CGROUP_STAT_RSS_HUGE. */ // 如果是root就把所有的内存使用量都算进来. val = mem_cgroup_recursive_stat(memcg, MEM_CGROUP_STAT_CACHE); val += mem_cgroup_recursive_stat(memcg, MEM_CGROUP_STAT_RSS); if (swap) val += mem_cgroup_recursive_stat(memcg, MEM_CGROUP_STAT_SWAP); return val << PAGE_SHIFT; }
static int __do_fault(struct mm_struct *mm, struct vm_area_struct *vma, unsigned long address, pmd_t *pmd, pgoff_t pgoff, unsigned int flags, pte_t orig_pte) { pte_t *page_table; spinlock_t *ptl; struct page *page; struct page *cow_page; pte_t entry; int anon = 0; struct page *dirty_page = NULL; struct vm_fault vmf; int ret; int page_mkwrite = 0;
/* * If we do COW later, allocate page befor taking lock_page() * on the file cache page. This will reduce lock holding time. */ if ((flags & FAULT_FLAG_WRITE) && !(vma->vm_flags & VM_SHARED)) {
if (unlikely(anon_vma_prepare(vma))) return VM_FAULT_OOM;
/* 分配内存并且映射到内存区间 */ cow_page = alloc_page_vma(GFP_HIGHUSER_MOVABLE, vma, address); if (!cow_page) return VM_FAULT_OOM; /* 进行统计 */ if (mem_cgroup_newpage_charge(cow_page, mm, GFP_KERNEL)) { page_cache_release(cow_page); return VM_FAULT_OOM; } } else cow_page = NULL;
static unsigned long mem_cgroup_reclaim(struct mem_cgroup *memcg, gfp_t gfp_mask, unsigned long flags) { unsigned long total = 0; bool noswap = false; int loop;
if (flags & MEM_CGROUP_RECLAIM_NOSWAP) noswap = true; if (!(flags & MEM_CGROUP_RECLAIM_SHRINK) && memcg->memsw_is_minimum) noswap = true;
for (loop = 0; loop < MEM_CGROUP_MAX_RECLAIM_LOOPS; loop++) { if (loop) drain_all_stock_async(memcg); total += try_to_free_mem_cgroup_pages(memcg, gfp_mask, noswap); /* * Allow limit shrinkers, which are triggered directly * by userspace, to catch signals and stop reclaim * after minimal progress, regardless of the margin. */ if (total && (flags & MEM_CGROUP_RECLAIM_SHRINK)) break; if (mem_cgroup_margin(memcg)) break; /* * If nothing was reclaimed after two attempts, there * may be no reclaimable pages in this hierarchy. */ if (loop && !total) break; } return total; }
why ‘memory+swap’ rather than swap. The global LRU(kswapd) can swap out arbitrary pages. Swap-out means to move account from memory to swap…there is no change in usage of memory+swap. In other words, when we want to limit the usage of swap without affecting global LRU, memory+swap limit is better than just limiting swap from an OS point of view.[12]
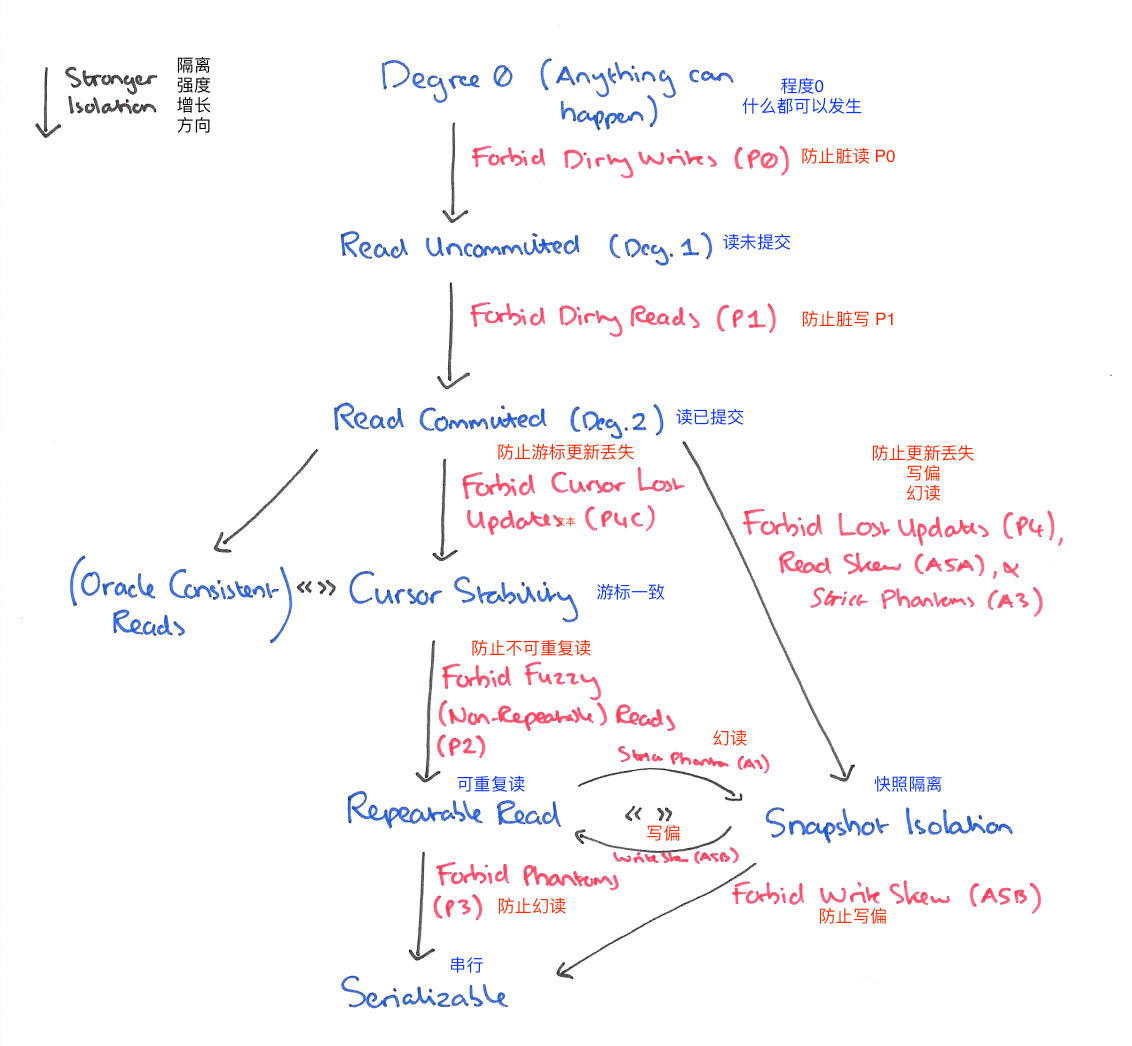
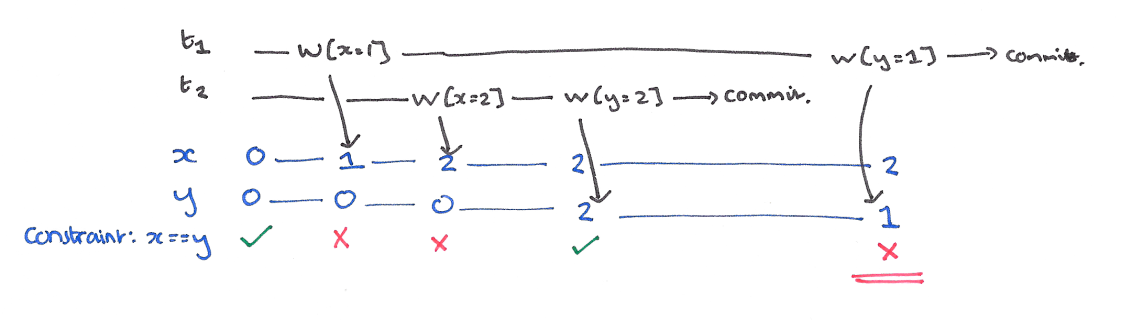
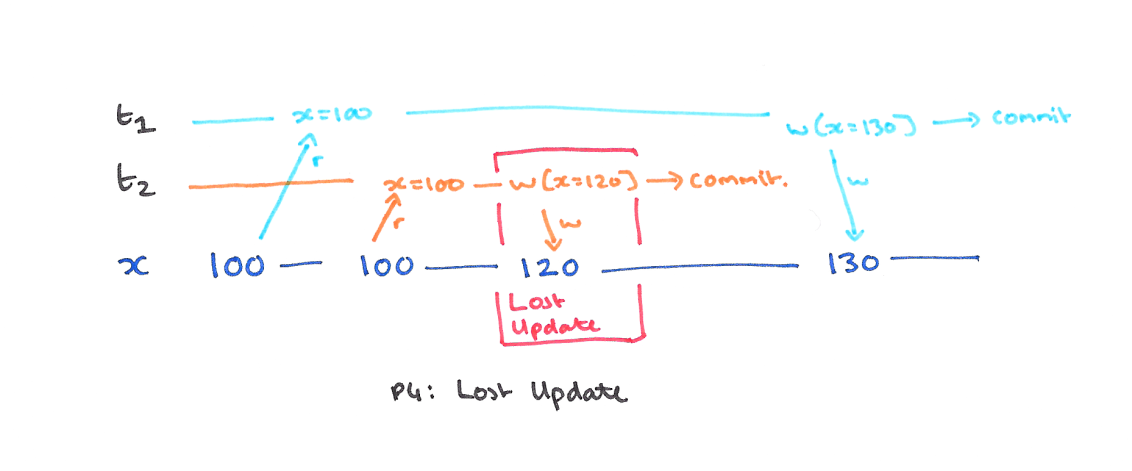
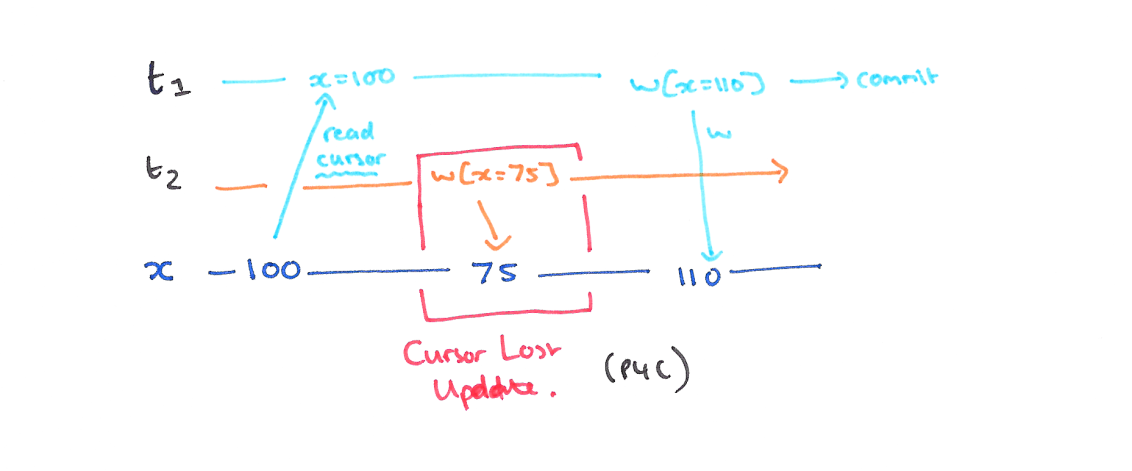
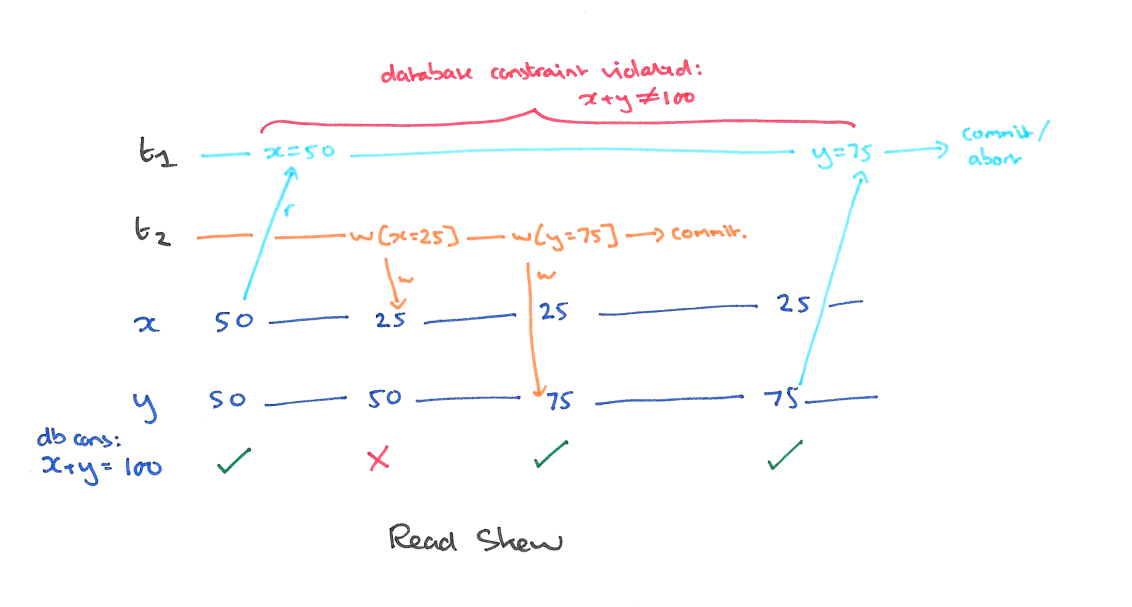
使用快照隔离 (Snapshot Isolation),快照隔离是基于 MVCC 的。当一个 T 事务开始的时候,T 会获得一个抽象的时间戳(版本),当对数据 X 进行读取的时候,并不是直接看到最新写入的数据而是在 T 开始前的所有执行中的事务中最后一个对 X 标记的版本(如果 T 修改过 X,那么看到的是自己的版本)。也就是说 T 是基于当前的数据库的一个镜像进行操作的,有点类似于 Copy And Swap,而 T 开始执行是获得的版本就是这个快照的凭证。这样能保证所有的读都是基于一个一致的状态获取的。
SI 解决冲突的方法一般是 “First-Commiter-Wins” 也就是说,如果两个并发的事务修改了同一个数据,先写的事务会成功,而后写的事务会发现版本和原本的不一致而退出事务。
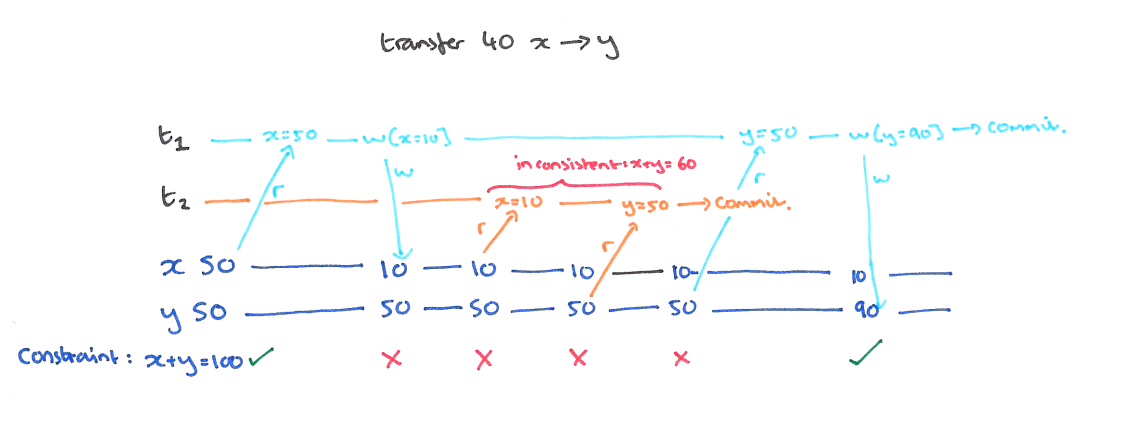
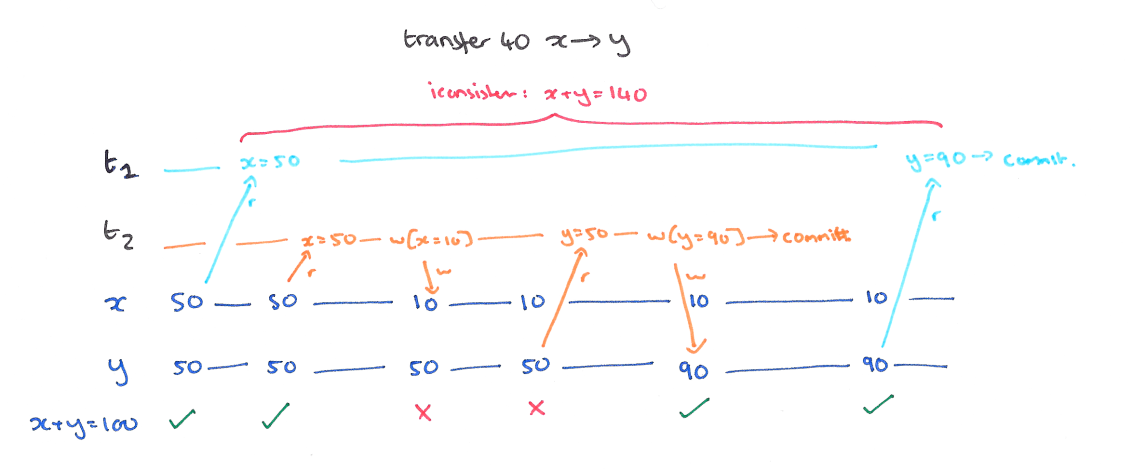
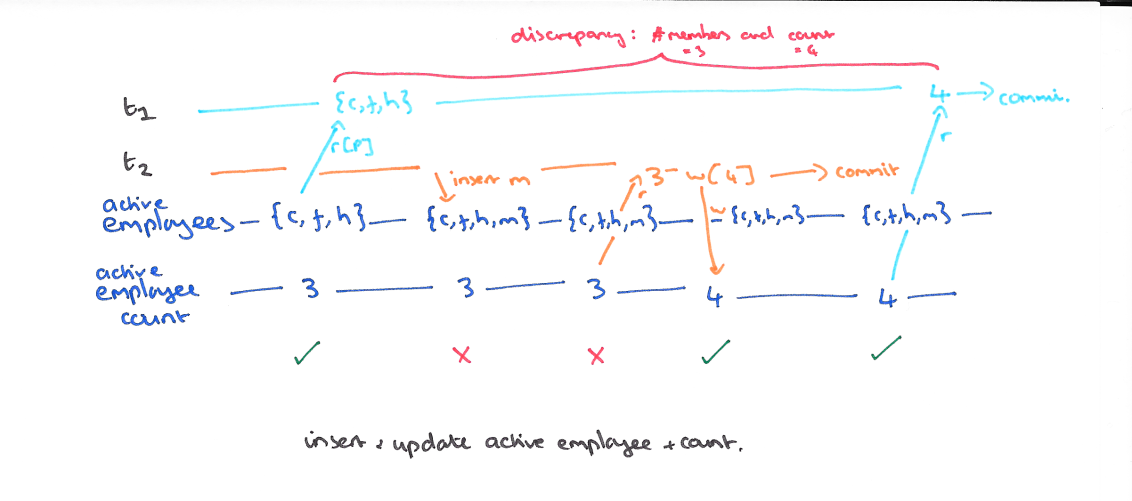
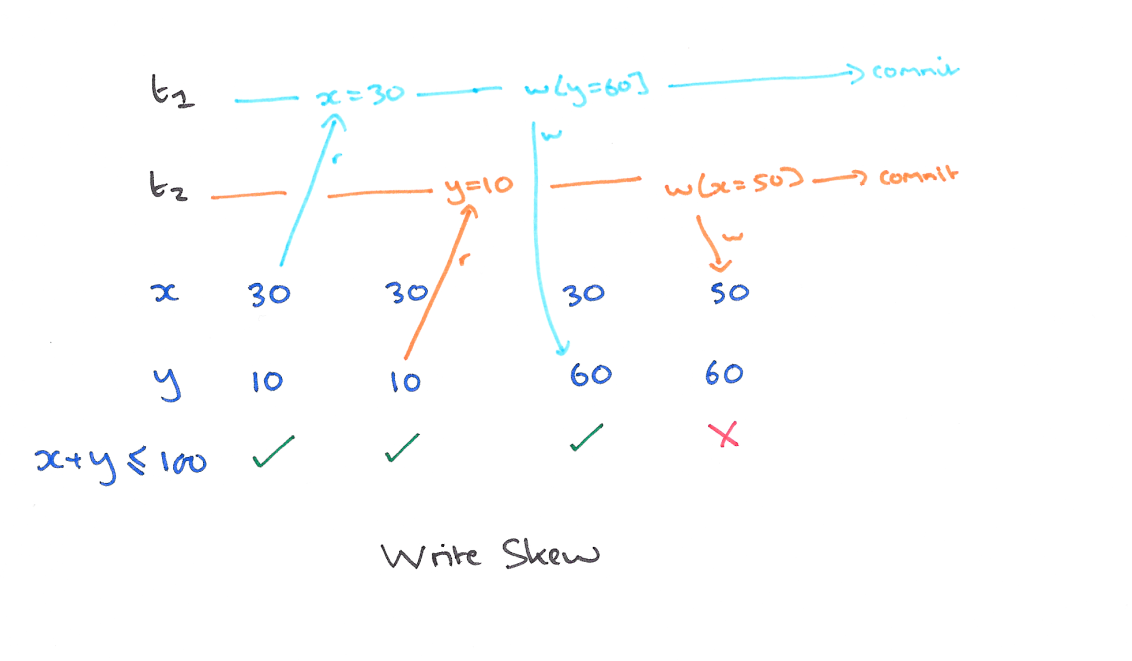
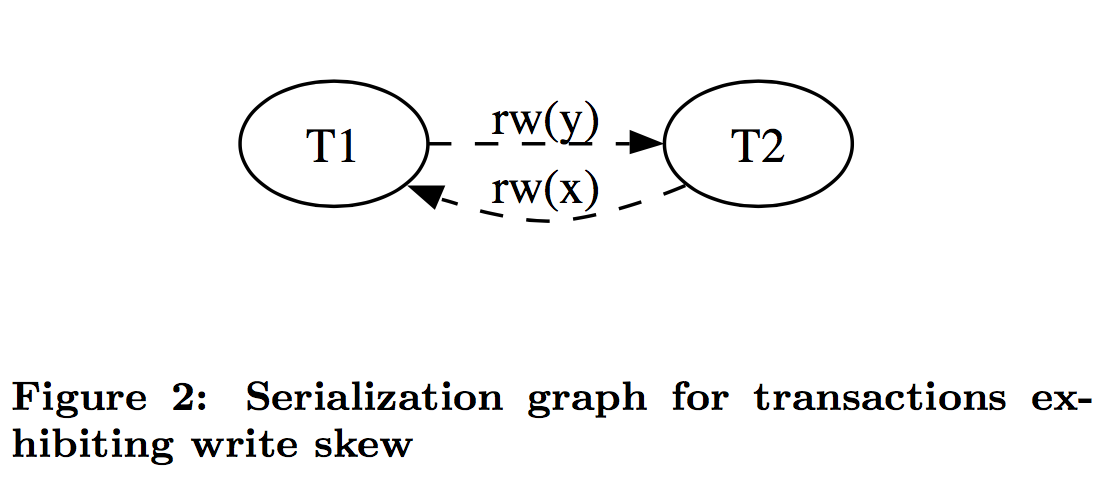
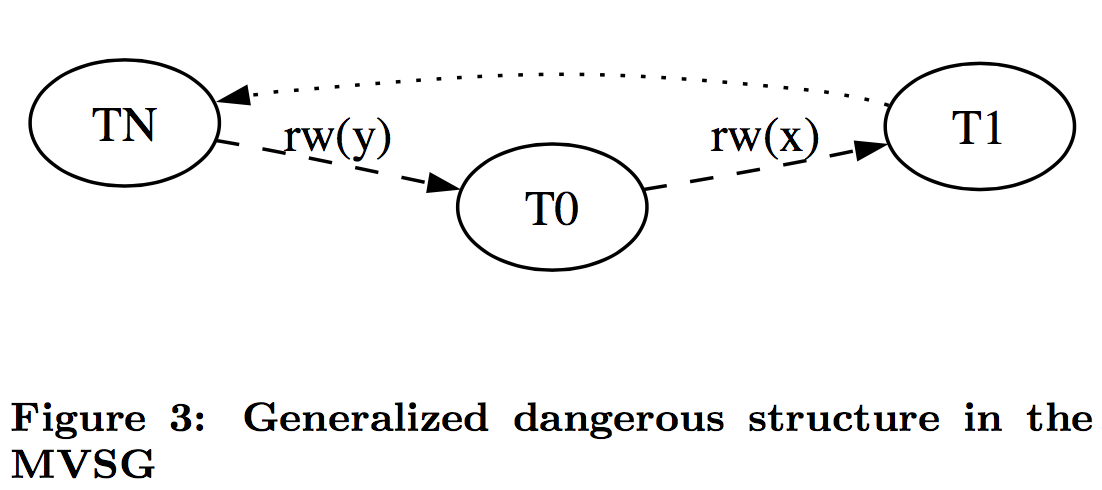
以我们的例子来说的话,T1 的 y 只会读到自己开始时候的版本,也就是 50,而不是 75,这样读偏就解决了。但是快照隔离还是不能解决另一个问题,就是写偏。这是我们要面临的新问题。
A5B write skew (写偏)
现象
这个和读偏类似,只不过,不一致在了整个系统上。T1 写锁有 y 的新版本,T2 写锁有 x 的新版本,他们没有写冲突,导致最后系统不一致,x+y 的钱变多了。
// Since coalesced heartbeats adds latency to heartbeat messages, it is // beneficial to have it run on a faster cycle than once per tick, so that // the delay does not impact latency-sensitive features such as quiescence. func (s *Store) startCoalescedHeartbeatsLoop() { s.stopper.RunWorker(func() { ticker := time.NewTicker(s.cfg.CoalescedHeartbeatsInterval) defer func() { ticker.Stop() }()
for { select { case <-ticker.C: s.sendQueuedHeartbeats() case <-s.stopper.ShouldStop(): return } } }) }
在 Store 这个层面是对每个 Replica (一个 raft group 的成员) 是有感知的,但是每个 raft group 是独立的,只是在发送是会检查对方节点是否和现在的 raft group 有交集, 从而尝试合并消息的发送,你可以理解为在节点之间的消息通道上对不同 raft group 之间多路复用。 这就是 MultiRaft 对多个 raft group 的网络吞吐做的一个优化,代价是可能造成消息的延迟,因为毕竟是被缓存到队列里了。
其次是对SSTable的合并,SSTable是分层存储的,第一层也就是Level0(被称作 young level),是MemTable刷入的一层,允许这一层的SSTable的key有交集。对于每一层都有一个阈值(young level 是 4,其他层是按大小算的,10^L MB),如果超过阈值自动向下一层合并,从level1开始的每一次key不允许有交集。具体的做法是从 young level 中把有交集的SSTable一起和下一层key有交集的SSTable合并成一个新的SSTable,然后其他层则是从自身层取出一个和下一层有交集的SSTable合并即可。这个属性可以用归纳法证明,从0层向1层合并的时候,1层只有一个的情况下肯定不会相交,然后假设n个的时候也不相交,在n+1的时候有交集,那么n+1合并时有0层的 key 和 n 当中的有交集,但是有交集的部分会被归并掉所以矛盾,所以n+1个的时候也是没有交集的。那1层能保证没有交集的话取出一个向下合并也是类似的不会有交集。所以再重复一遍分层存储的两个属性。
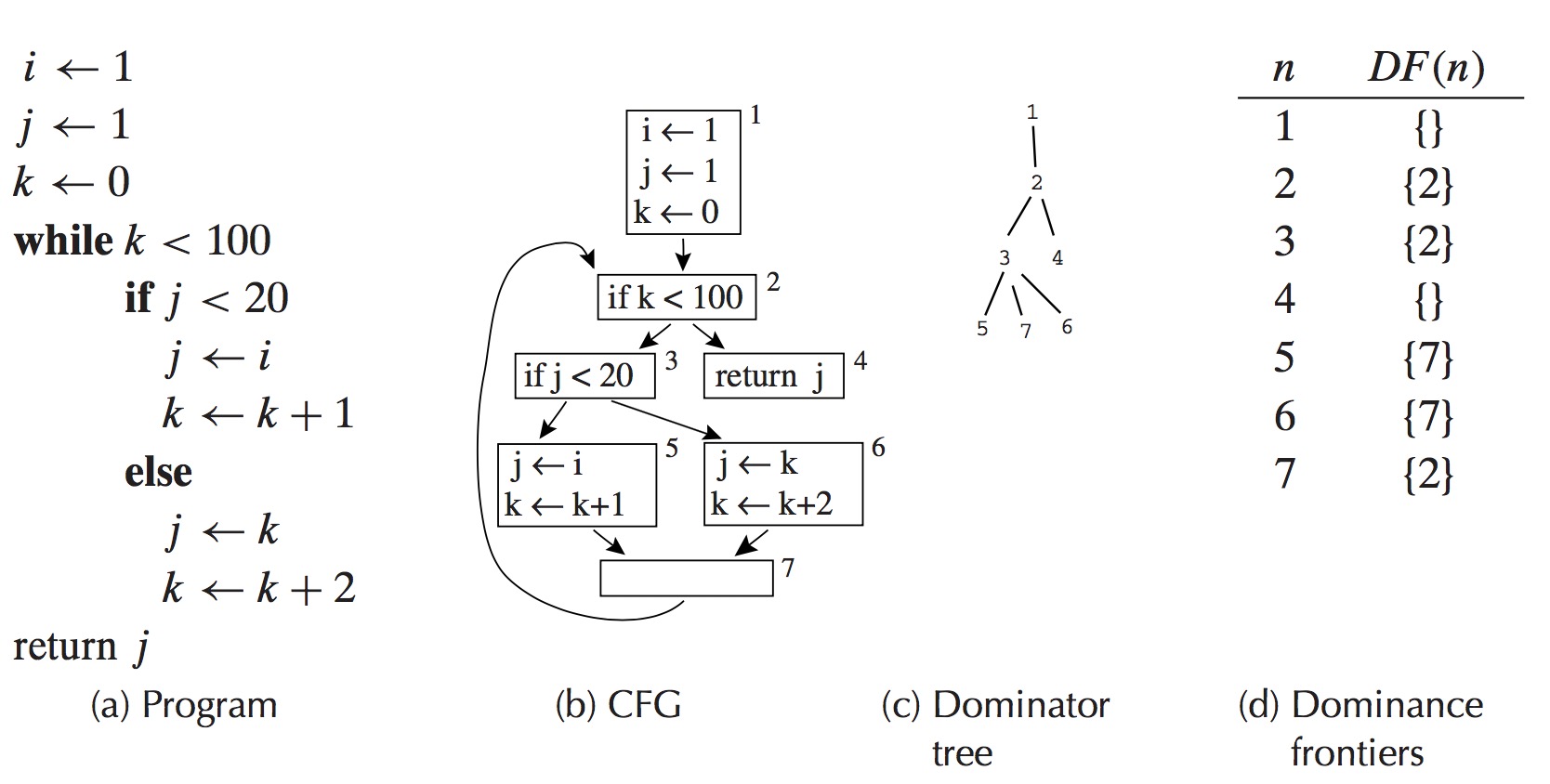
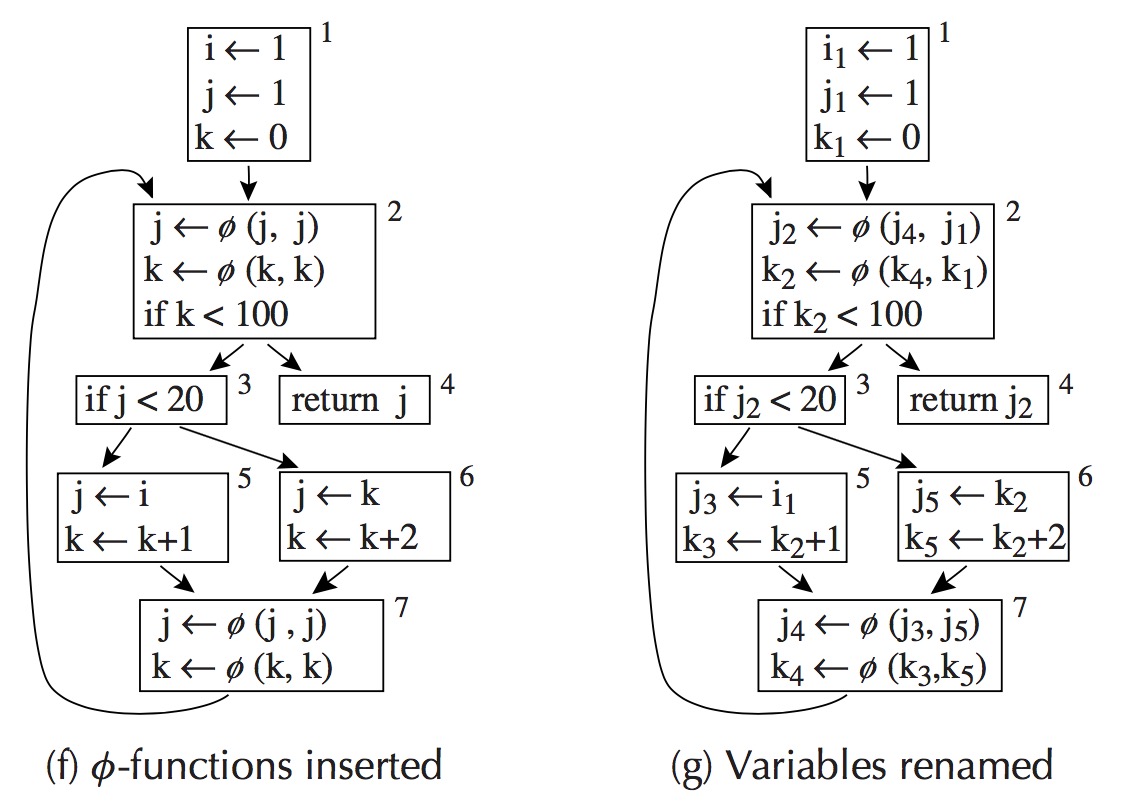
A 的 dominance frontier 含有B,如果A没有strictly dominate B,但是 dominate 了B的一个前驱节点。
用遍历的方式确定 dominance frontier 的伪代码。
1 2 3 4 5 6 7
for each node b if the number of immediate predecessors of b ≥ 2 for each p in immediate predecessors of b runner := p while runner ≠ idom(b) add b to runner’s dominance frontier set runner := idom(runner)
/* * This is the ISR for the vortex series chips. * full_bus_master_tx == 0 && full_bus_master_rx == 0 */
static irqreturn_t vortex_interrupt(int irq, void *dev_id) { struct net_device *dev = dev_id; struct vortex_private *vp = netdev_priv(dev); void __iomem *ioaddr; int status; int work_done = max_interrupt_work; int handled = 0; unsigned int bytes_compl = 0, pkts_compl = 0;
ioaddr = vp->ioaddr; spin_lock(&vp->lock);
status = ioread16(ioaddr + EL3_STATUS); // 从ioremap的地址当中读取网卡的状态,这个是设备规定的地址
if (vortex_debug > 6) pr_debug("vortex_interrupt(). status=0x%4x\n", status);
// 在中断处理的时候,设备是关中断的,这个时候可以通过观察这个status来检查设备是否有中断到来. if ((status & IntLatch) == 0) // 有中断需要处理,但是可能已经被其他中断处理函数处理了 goto handler_exit; /* No interrupt: shared IRQs cause this */ handled = 1;
if (status & IntReq) { // 中断请求 status |= vp->deferred; vp->deferred = 0; }
if (status == 0xffff) /* h/w no longer present (hotplug)? */ goto handler_exit;
if (vortex_debug > 4) pr_debug("%s: interrupt, status %4.4x, latency %d ticks.\n", dev->name, status, ioread8(ioaddr + Timer));
spin_lock(&vp->window_lock); window_set(vp, 7);
do { if (vortex_debug > 5) pr_debug("%s: In interrupt loop, status %4.4x.\n", dev->name, status); if (status & RxComplete) // 中断表示接收完成的时候调用 vortex_rx vortex_rx(dev);
if (status & TxAvailable) { // 中断表示可以传输的时候 if (vortex_debug > 5) pr_debug(" TX room bit was handled.\n"); /* There's room in the FIFO for a full-sized packet. */ iowrite16(AckIntr | TxAvailable, ioaddr + EL3_CMD); netif_wake_queue (dev); }
if (status & DMADone) {// 表示发送完成可以清除sk_buff了 if (ioread16(ioaddr + Wn7_MasterStatus) & 0x1000) { iowrite16(0x1000, ioaddr + Wn7_MasterStatus); /* Ack the event. */ pci_unmap_single(VORTEX_PCI(vp), vp->tx_skb_dma, (vp->tx_skb->len + 3) & ~3, PCI_DMA_TODEVICE); pkts_compl++; bytes_compl += vp->tx_skb->len; dev_kfree_skb_irq(vp->tx_skb); /* Release the transferred buffer */ if (ioread16(ioaddr + TxFree) > 1536) { /* * AKPM: FIXME: I don't think we need this. If the queue was stopped due to * insufficient FIFO room, the TxAvailable test will succeed and call * netif_wake_queue() */ netif_wake_queue(dev); } else { /* Interrupt when FIFO has room for max-sized packet. */ iowrite16(SetTxThreshold + (1536>>2), ioaddr + EL3_CMD); netif_stop_queue(dev); } } } /* Check for all uncommon interrupts at once. */ if (status & (HostError | RxEarly | StatsFull | TxComplete | IntReq)) { if (status == 0xffff) break; if (status & RxEarly) vortex_rx(dev); spin_unlock(&vp->window_lock); vortex_error(dev, status); spin_lock(&vp->window_lock); window_set(vp, 7); }
if (--work_done < 0) { // 最多处理work_done个frame pr_warn("%s: Too much work in interrupt, status %4.4x\n", dev->name, status); /* Disable all pending interrupts. */ do { vp->deferred |= status; // 把当前状态保存起来等下次中断的时候处理 iowrite16(SetStatusEnb | (~vp->deferred & vp->status_enable), ioaddr + EL3_CMD); iowrite16(AckIntr | (vp->deferred & 0x7ff), ioaddr + EL3_CMD); } while ((status = ioread16(ioaddr + EL3_CMD)) & IntLatch); // 把中断清掉? /* The timer will reenable interrupts. */ mod_timer(&vp->timer, jiffies + 1*HZ); break; } /* Acknowledge the IRQ. */ iowrite16(AckIntr | IntReq | IntLatch, ioaddr + EL3_CMD); } while ((status = ioread16(ioaddr + EL3_STATUS)) & (IntLatch | RxComplete));// 当有pending的中断并且是接收完成的状态
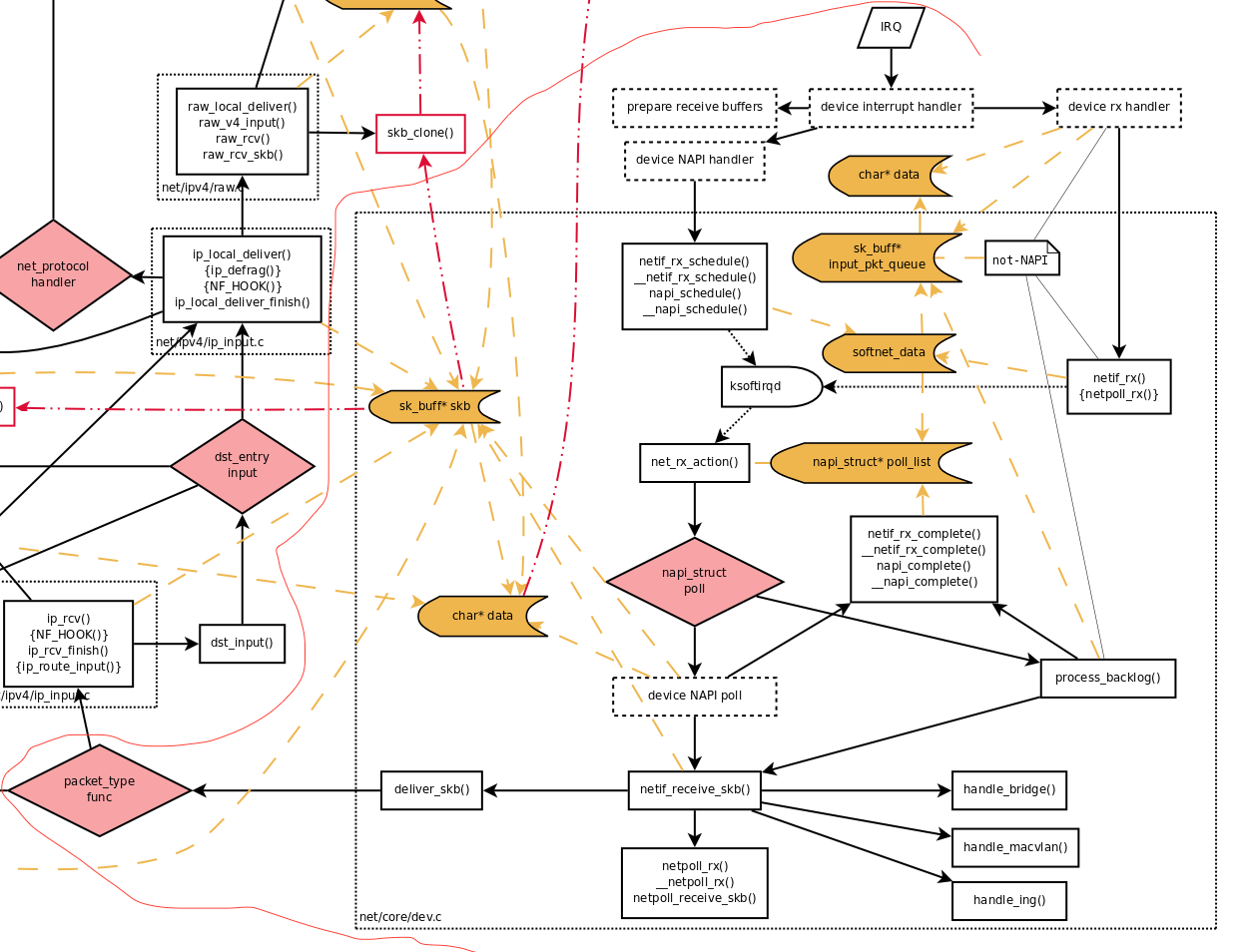
/* * enqueue_to_backlog is called to queue an skb to a per CPU backlog * queue (may be a remote CPU queue). */ static int enqueue_to_backlog(struct sk_buff *skb, int cpu, unsigned int *qtail) { struct softnet_data *sd; unsigned long flags; unsigned int qlen;
rps_lock(sd); if (!netif_running(skb->dev)) // 如果设备已经没有运行的直接丢frame goto drop; qlen = skb_queue_len(&sd->input_pkt_queue); // 获取softnet_data的&sk_buff的队列长度 if (qlen <= netdev_max_backlog && !skb_flow_limit(skb, qlen)) { // 如果没有超过最大长度并且没有被限制 if (qlen) { enqueue: __skb_queue_tail(&sd->input_pkt_queue, skb); input_queue_tail_incr_save(sd, qtail); rps_unlock(sd); local_irq_restore(flags); // 加入队列并且开中断 return NET_RX_SUCCESS; } // 如果队列为空可以尝试调度 backlog device, // 再把frame加入到队列当中。 /* Schedule NAPI for backlog device * We can use non atomic operation since we own the queue lock */ if (!__test_and_set_bit(NAPI_STATE_SCHED, &sd->backlog.state)) { if (!rps_ipi_queued(sd)) ____napi_schedule(sd, &sd->backlog); } goto enqueue; }
/* If softirq window is exhausted then punt. * Allow this to run for 2 jiffies since which will allow * an average latency of 1.5/HZ. */ if (unlikely(budget <= 0 || // 如果budge耗尽或者超过了两个jiffies就会停止 time_after_eq(jiffies, time_limit))) { sd->time_squeeze++; break; } }
static int process_backlog(struct napi_struct *napi, int quota) { int work = 0; struct softnet_data *sd = container_of(napi, struct softnet_data, backlog);
/* Check if we have pending ipi, its better to send them now, * not waiting net_rx_action() end. */ if (sd_has_rps_ipi_waiting(sd)) { local_irq_disable(); net_rps_action_and_irq_enable(sd); }
rps_lock(sd); if (skb_queue_empty(&sd->input_pkt_queue)) { /* * Inline a custom version of __napi_complete(). * only current cpu owns and manipulates this napi, * and NAPI_STATE_SCHED is the only possible flag set * on backlog. * We can use a plain write instead of clear_bit(), * and we dont need an smp_mb() memory barrier. */ napi->state = 0; rps_unlock(sd);
if (status & TxAvailable) { // 中断表示可以传输的时候 if (vortex_debug > 5) pr_debug(" TX room bit was handled.\n"); /* There's room in the FIFO for a full-sized packet. */ iowrite16(AckIntr | TxAvailable, ioaddr + EL3_CMD); netif_wake_queue (dev); }
就是说当状态可用的时候,尝试调用netif_wake_queue来触发frame的发送。
首先来看一下如何选择发送的设备。
1 2 3 4 5 6 7 8 9 10 11
/** * netif_wake_queue - restart transmit * @dev: network device * * Allow upper layers to call the device hard_start_xmit routine. * Used for flow control when transmit resources are available. */ static inline void netif_wake_queue(struct net_device *dev) { netif_tx_wake_queue(netdev_get_tx_queue(dev, 0)); }
/* * Transmit possibly several skbs, and handle the return status as * required. Holding the __QDISC___STATE_RUNNING bit guarantees that * only one CPU can execute this function. * * Returns to the caller: * 0 - queue is empty or throttled. * >0 - queue is not empty. */ int sch_direct_xmit(struct sk_buff *skb, struct Qdisc *q, struct net_device *dev, struct netdev_queue *txq, spinlock_t *root_lock, bool validate) { int ret = NETDEV_TX_BUSY;
/* And release qdisc */ spin_unlock(root_lock);
/* Note that we validate skb (GSO, checksum, ...) outside of locks */ if (validate) skb = validate_xmit_skb_list(skb, dev);
if (likely(skb)) { HARD_TX_LOCK(dev, txq, smp_processor_id()); if (!netif_xmit_frozen_or_stopped(txq)) skb = dev_hard_start_xmit(skb, dev, txq, &ret);
/* * Allocate a region of KVA of the specified size and alignment, within the * vstart and vend. */ static struct vmap_area *alloc_vmap_area(unsigned long size, unsigned long align, unsigned long vstart, unsigned long vend, int node, gfp_t gfp_mask) { struct vmap_area *va; struct rb_node *n; unsigned long addr; int purged = 0; struct vmap_area *first;
va = kmalloc_node(sizeof(struct vmap_area), gfp_mask & GFP_RECLAIM_MASK, node); if (unlikely(!va)) return ERR_PTR(-ENOMEM);
/* * Only scan the relevant parts containing pointers to other objects * to avoid false negatives. */ kmemleak_scan_area(&va->rb_node, SIZE_MAX, gfp_mask & GFP_RECLAIM_MASK);
retry: spin_lock(&vmap_area_lock); /* * Invalidate cache if we have more permissive parameters. * cached_hole_size notes the largest hole noticed _below_ * the vmap_area cached in free_vmap_cache: if size fits * into that hole, we want to scan from vstart to reuse * the hole instead of allocating above free_vmap_cache. * Note that __free_vmap_area may update free_vmap_cache * without updating cached_hole_size or cached_align. */ if (!free_vmap_cache || /* 缓存为空, 并且在下面条件满足的时候不使用缓存 */ size < cached_hole_size || /* 至少有一个空洞可以复用, 直接从头开始搜索 */ vstart < cached_vstart || /* 别缓存的起点小 */ align < cached_align) { /* 对齐大小比缓存的小 */ nocache: cached_hole_size = 0; free_vmap_cache = NULL; } /* record if we encounter less permissive parameters */ cached_vstart = vstart; cached_align = align;
/* find starting point for our search */ if (free_vmap_cache) { /* 这个地方是用缓存上次搜索的结果, 每次找到以后会存到这里 */ first = rb_entry(free_vmap_cache, struct vmap_area, rb_node); addr = ALIGN(first->va_end, align); if (addr < vstart) /* 缓存的末尾对齐之后超出了范围从头开始搜索 */ goto nocache; if (addr + size < addr) /* 整数溢出 */ goto overflow;
while (n) { /* 用对齐之后的vstart正好<=va_ned&&>=va_start的节点 */ struct vmap_area *tmp; tmp = rb_entry(n, struct vmap_area, rb_node); if (tmp->va_end >= addr) { first = tmp; if (tmp->va_start <= addr) break; n = n->rb_left; } else n = n->rb_right; }
if (!first) goto found; } /* from the starting point, walk areas until a suitable hole is found */ while (addr + size > first->va_start && addr + size <= vend) { if (addr + cached_hole_size < first->va_start) /* cached_hole_size */ cached_hole_size = first->va_start - addr; /* 缓存最大的空洞大小 */ addr = ALIGN(first->va_end, align); if (addr + size < addr) goto overflow;
if (list_is_last(&first->list, &vmap_area_list)) goto found;
if (gfpflags_allow_blocking(gfp_mask)) { unsigned long freed = 0; blocking_notifier_call_chain(&vmap_notify_list, 0, &freed); if (freed > 0) { purged = 0; goto retry; } }
if (printk_ratelimit()) pr_warn("vmap allocation for size %lu failed: use vmalloc=<size> to increase size\n", size); kfree(va); return ERR_PTR(-EBUSY); }
/* * * Set up page tables in kva (addr, end). The ptes shall have prot "prot", and * will have pfns corresponding to the "pages" array. * 这里的kva指的是kernel virtual address. * Ie. pte at addr+N*PAGE_SIZE shall point to pfn corresponding to pages[N] */ static int vmap_page_range_noflush(unsigned long start, unsigned long end, pgprot_t prot, struct page **pages) { pgd_t *pgd; unsigned long next; unsigned long addr = start; int err = 0; int nr = 0;
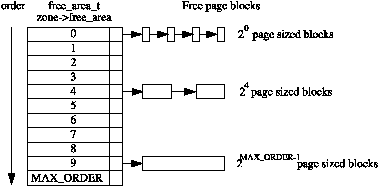
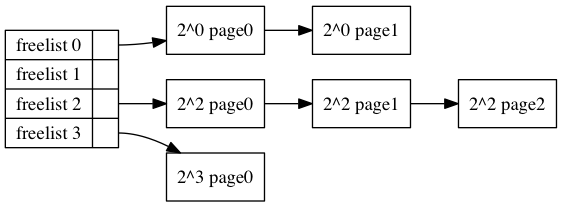
/* * PAGE_ALLOC_COSTLY_ORDER is the order at which allocations are deemed * costly to service. That is between allocation orders which should * coalesce naturally under reasonable reclaim pressure and those which * will not. */ /* 内核认为超过8个页算是大的内存分配 */ #define PAGE_ALLOC_COSTLY_ORDER 3
enum { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_RECLAIMABLE, MIGRATE_PCPTYPES, /* the number of types on the pcp lists */ MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES, #ifdef CONFIG_CMA /* * MIGRATE_CMA migration type is designed to mimic the way * ZONE_MOVABLE works. Only movable pages can be allocated * from MIGRATE_CMA pageblocks and page allocator never * implicitly change migration type of MIGRATE_CMA pageblock. * * The way to use it is to change migratetype of a range of * pageblocks to MIGRATE_CMA which can be done by * __free_pageblock_cma() function. What is important though * is that a range of pageblocks must be aligned to * MAX_ORDER_NR_PAGES should biggest page be bigger then * a single pageblock. */ MIGRATE_CMA, #endif #ifdef CONFIG_MEMORY_ISOLATION MIGRATE_ISOLATE, /* can't allocate from here */ #endif MIGRATE_TYPES };
/* * Do the hard work of removing an element from the buddy allocator. * Call me with the zone->lock already held. */ static struct page *__rmqueue(struct zone *zone, unsigned int order, int migratetype) { struct page *page;
page = __rmqueue_smallest(zone, order, migratetype); if (unlikely(!page)) { if (migratetype == MIGRATE_MOVABLE) page = __rmqueue_cma_fallback(zone, order); /* MOVABLE的失败优先从cma迁移 */
/* * Go through the free lists for the given migratetype and remove * the smallest available page from the freelists */ static inline struct page *__rmqueue_smallest(struct zone *zone, unsigned int order, int migratetype) { unsigned int current_order; struct free_area *area; struct page *page;
/* Find a page of the appropriate size in the preferred list */ for (current_order = order; current_order < MAX_ORDER; ++current_order) { area = &(zone->free_area[current_order]); page = list_first_entry_or_null(&area->free_list[migratetype], struct page, lru); if (!page) continue; /* 如果失败就尝试更大的块 */ list_del(&page->lru); /* 这个lru取决他的上下文,比如在这里就是free_list */ rmv_page_order(page); /* 设置flags */ area->nr_free--; /* free计数器-1 */ expand(zone, page, order, current_order, area, migratetype); set_pcppage_migratetype(page, migratetype);/* 设置page的migratetype */ return page; } return NULL; }
/* * The order of subdivision here is critical for the IO subsystem. * Please do not alter this order without good reasons and regression * testing. Specifically, as large blocks of memory are subdivided, * the order in which smaller blocks are delivered depends on the order * they're subdivided in this function. This is the primary factor * influencing the order in which pages are delivered to the IO * subsystem according to empirical testing, and this is also justified * by considering the behavior of a buddy system containing a single * large block of memory acted on by a series of small allocations. * This behavior is a critical factor in sglist merging's success. * * -- nyc */ static inline void expand(struct zone *zone, struct page *page, int low, int high, struct free_area *area, int migratetype) { unsigned long size = 1 << high;
while (high > low) { /* 从高阶向低阶迭代 */ area--; high--; size >>= 1; VM_BUG_ON_PAGE(bad_range(zone, &page[size]), &page[size]); /* guardpage TODO */ if (IS_ENABLED(CONFIG_DEBUG_PAGEALLOC) && debug_guardpage_enabled() && high < debug_guardpage_minorder()) { /* * Mark as guard pages (or page), that will allow to * merge back to allocator when buddy will be freed. * Corresponding page table entries will not be touched, * pages will stay not present in virtual address space */ set_page_guard(zone, &page[size], high, migratetype); continue; } list_add(&page[size].lru, &area->free_list[migratetype]); /* 把page放到area的free_list里面, 这个page是一个数组形式的 比如之前是8 这里变成4,那么后半部分会被留下来,前半部分会继续用于迭代 */ area->nr_free++; /* 空闲块计数器+1 */ set_page_order(&page[size], high); /* 相当于page->private = high 表示自己属于order为high的阶的block中 */ } }
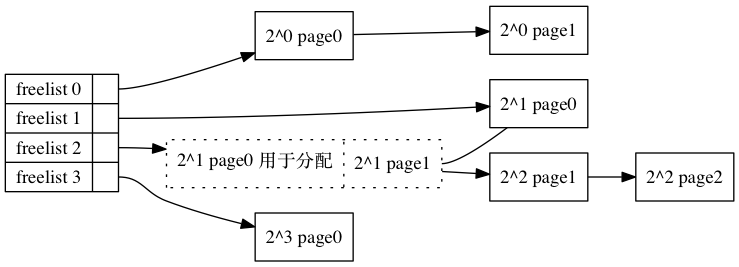
/* * This array describes the order lists are fallen back to when * the free lists for the desirable migrate type are depleted */ static int fallbacks[MIGRATE_TYPES][4] = { [MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_TYPES }, [MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_TYPES }, [MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_TYPES }, #ifdef CONFIG_CMA [MIGRATE_CMA] = { MIGRATE_TYPES }, /* Never used */ #endif #ifdef CONFIG_MEMORY_ISOLATION [MIGRATE_ISOLATE] = { MIGRATE_TYPES }, /* Never used */ #endif };
/* Remove an element from the buddy allocator from the fallback list */ static inline struct page * __rmqueue_fallback(struct zone *zone, unsigned int order, int start_migratetype) { struct free_area *area; unsigned int current_order; struct page *page; int fallback_mt; bool can_steal;
/* Find the largest possible block of pages in the other list */ for (current_order = MAX_ORDER-1; current_order >= order && current_order <= MAX_ORDER-1; --current_order) { area = &(zone->free_area[current_order]); /* 遍历fallback table 找到合适的fallback migratetype 要综合考虑: 是否有超过一定阈值的空闲页,并且是可以退化的页类型 */ fallback_mt = find_suitable_fallback(area, current_order, start_migratetype, false, &can_steal); if (fallback_mt == -1) continue;
/* Remove the page from the freelists */ area->nr_free--; list_del(&page->lru); rmv_page_order(page);
expand(zone, page, order, current_order, area, start_migratetype); /* * The pcppage_migratetype may differ from pageblock's * migratetype depending on the decisions in * find_suitable_fallback(). This is OK as long as it does not * differ for MIGRATE_CMA pageblocks. Those can be used as * fallback only via special __rmqueue_cma_fallback() function */ set_pcppage_migratetype(page, start_migratetype);
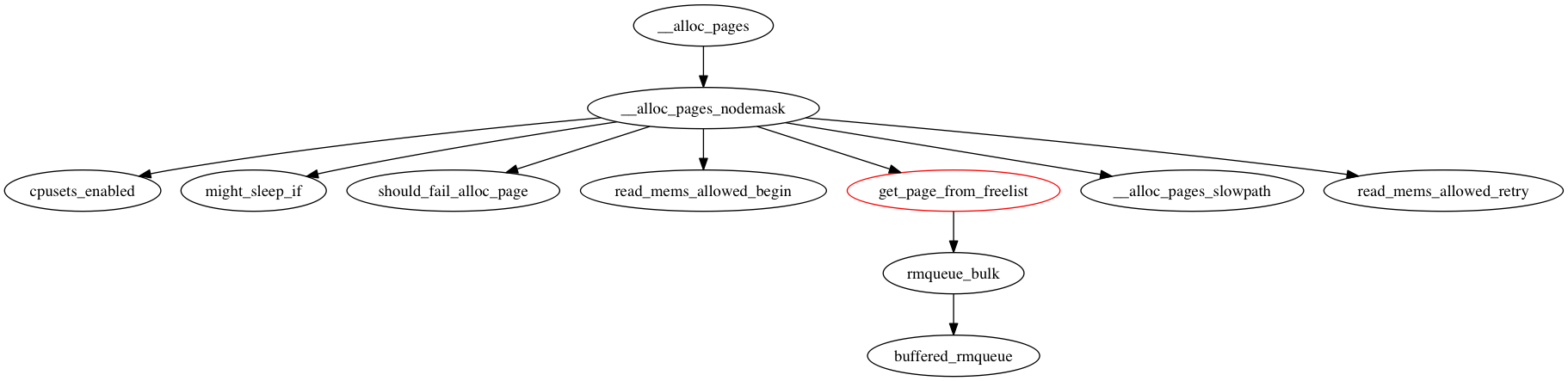
/* * Structure for holding the mostly immutable allocation parameters passed * between functions involved in allocations, including the alloc_pages* * family of functions. * * nodemask, migratetype and high_zoneidx are initialized only once in * __alloc_pages_nodemask() and then never change. * * zonelist, preferred_zone and classzone_idx are set first in * __alloc_pages_nodemask() for the fast path, and might be later changed * in __alloc_pages_slowpath(). All other functions pass the whole strucure * by a const pointer. */ struct alloc_context { struct zonelist *zonelist; nodemask_t *nodemask; struct zoneref *preferred_zoneref; int migratetype; enum zone_type high_zoneidx; bool spread_dirty_pages; };
struct per_cpu_pages { int count; /* number of pages in the list */ int high; /* high watermark, emptying needed */ int batch; /* chunk size for buddy add/remove */
/* Lists of pages, one per migrate type stored on the pcp-lists */ struct list_head lists[MIGRATE_PCPTYPES]; };
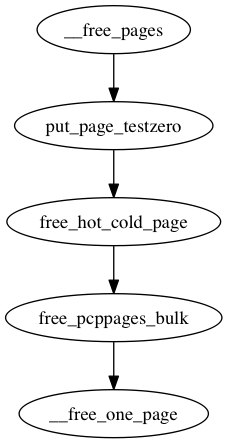
/* * Freeing function for a buddy system allocator. * * The concept of a buddy system is to maintain direct-mapped table * (containing bit values) for memory blocks of various "orders". * The bottom level table contains the map for the smallest allocatable * units of memory (here, pages), and each level above it describes * pairs of units from the levels below, hence, "buddies". * At a high level, all that happens here is marking the table entry * at the bottom level available, and propagating the changes upward * as necessary, plus some accounting needed to play nicely with other * parts of the VM system. * At each level, we keep a list of pages, which are heads of continuous * free pages of length of (1 << order) and marked with _mapcount * PAGE_BUDDY_MAPCOUNT_VALUE. Page's order is recorded in page_private(page) * field. * So when we are allocating or freeing one, we can derive the state of the * other. That is, if we allocate a small block, and both were * free, the remainder of the region must be split into blocks. * If a block is freed, and its buddy is also free, then this * triggers coalescing into a block of larger size. * * -- nyc */
static inline void __free_one_page(struct page *page, /* 把page加回到free_list里面 */ unsigned long pfn, struct zone *zone, unsigned int order, int migratetype) { unsigned long page_idx; unsigned long combined_idx; unsigned long uninitialized_var(buddy_idx); struct page *buddy; unsigned int max_order;
continue_merging: while (order < max_order - 1) { buddy_idx = __find_buddy_index(page_idx, order);/* 获取buddy的下标 */ buddy = page + (buddy_idx - page_idx); /* 根据相对距离得到buddy page */ if (!page_is_buddy(page, buddy, order)) /* 如果不是buddy就结束合并 */ goto done_merging; /* * Our buddy is free or it is CONFIG_DEBUG_PAGEALLOC guard page, * merge with it and move up one order. */ if (page_is_guard(buddy)) { clear_page_guard(zone, buddy, order, migratetype); } else { /* 把buddy从free_area当中移除 */ list_del(&buddy->lru); zone->free_area[order].nr_free--; rmv_page_order(buddy); } combined_idx = buddy_idx & page_idx; page = page + (combined_idx - page_idx); page_idx = combined_idx; order++; /* 向上合并 */ } if (max_order < MAX_ORDER) { /* If we are here, it means order is >= pageblock_order. * We want to prevent merge between freepages on isolate * pageblock and normal pageblock. Without this, pageblock * isolation could cause incorrect freepage or CMA accounting. * * We don't want to hit this code for the more frequent * low-order merging. */ /* 在这里说明已经超出了pageblock的order, 可能在不同的migratetype的block边界了,这里再检查一次是不是isolate, 不允许节点间迁移的page, 如果是的话就要结束合并的迭代,不然继续向上合并 */ if (unlikely(has_isolate_pageblock(zone))) { int buddy_mt;
/* * If this is not the largest possible page, check if the buddy * of the next-highest order is free. If it is, it's possible * that pages are being freed that will coalesce soon. In case, * that is happening, add the free page to the tail of the list * so it's less likely to be used soon and more likely to be merged * as a higher order page */ if ((order < MAX_ORDER-2) && pfn_valid_within(page_to_pfn(buddy))) { /* 这个条件判断没有合并到最大块, 内核认为很有可能接下来这个块和其他free的块合并, 从减少碎片的角度来说会更倾向于放到链表的末尾, 让这个块的free状态保持久一点, 更有机会被合并成更大的块 */ struct page *higher_page, *higher_buddy; combined_idx = buddy_idx & page_idx; /* 合并后的idx */ higher_page = page + (combined_idx - page_idx); /* 合并后的page */ buddy_idx = __find_buddy_index(combined_idx, order + 1); /* 向上寻找buddy */ higher_buddy = higher_page + (buddy_idx - combined_idx); if (page_is_buddy(higher_page, higher_buddy, order + 1)) { list_add_tail(&page->lru, &zone->free_area[order].free_list[migratetype]); goto out; } }