Tensorflow 的 Tensor 和 OpKernel 分析
Tensor 的用户 API 可以参考这里,这里做一下简单介绍。Tensor 是各种维度的向量和矩阵的统称,分 Tensor 和 SparseTensor。和 Tensor 不同,SparseTensor 存的是值以及值对应的 index,而 Tensor 存的是完整的矩阵。
举个例子。
1 | import tensorflow as tf |
输出对应如下。
1 | a[0]=1, a[1]=1 |
Tensor 只有 eval 以后才能获得结果,是懒计算的。
Tensor 的实现
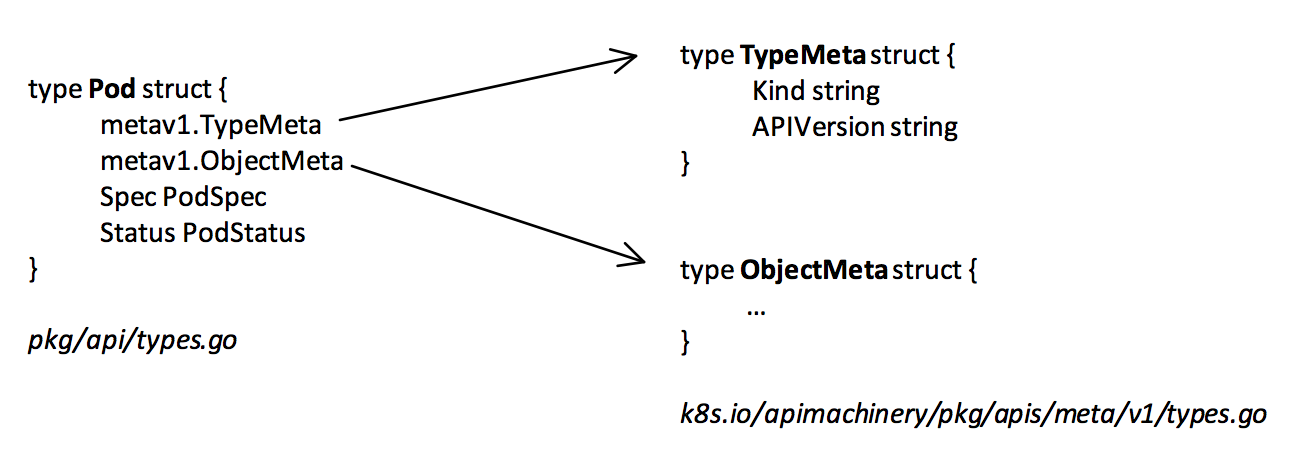
Tensor (tensorflow/tensorflow/core/framework/tensor.h) 依赖 TensorShape(tensorflow/tensorflow/tensorflow/core/framework/tensor_shape.h) 和 TensorBuffer (tensorflow/tensorflow/core/framework/tensor.h) 两个成员。
TensorShape 主要负责记录张量的形状。
而 TensorBuffer 主要负责管理 Tensor 的内存,TensorBuffer 继承自 RefCounted (tensorflow/tensorflow/core/lib/core/refcount.h),具有引用计数的功能,用于对内存进行管理。
1 | // Interface to access the raw ref-counted data buffer. |
他们的对应的关系如下。

Tensor 从下往上看,其实就是一个带”形状“的内存,和 NumPy 的数组是差不多的。
OpKernel
对于一个线性回归来说,是最简单也最好理解的模型,方便分析底层的代码实现。
$$ Y=XW+b $$
损失函数用平方差定义的,优化器是提督下降,这样一个模型可以用一下的 Python 代码实现,这个代码片段是截取的,如果要完整运行这个例子可以在这里复现。
1 | import tensorflow as tf |
对应的训练结果。
1 | Epoch: 3000, Error: 0.25882452726364136 |
可以看到,线性回归的模型主要依赖的两个 Operation 分别是 tf.add 和 tf.matmul,其他的复杂模型也是类似的逻辑,对应的 OpKernel 分别是 AddOp 和 MatMulOp,这里可以看一下具体的实现。
如果有源代码,可以连着源代码用 bazel 编译,可以参照这里自己编写一个 Op。
MatMulOp 的实现在 /tensorflow/core/kernels/matmul_op.cc 下面,定义在tensorflow/tensorflow/core/ops/math_ops.cc 下面。AddOp 在 /tensorflow/core/kernels/matmul_op.cc,实现在 /tensorflow/core/kernels/cwise_op_add_1.cc 下面,依赖 /tensorflow/tensorflow/core/kernels/cwise_ops_common.h 的 common 的定义。
Add 用的是 Eigen 的 add /tensorflow/tensorflow/core/kernels/cwise_ops.h,依赖third_party/Eigen/src/Core/functors/BinaryFunctors.h。
举个例子,看一下 MatMulOp, MatMulOp 的构造函数里面有一个 OpKernelConstruction 可以初始化 OpKernel,通过 OpKernel 可以获得这个 Op 的参数比如transpose_a 等等。
1 | template <typename Device, typename T, bool USE_CUBLAS> |
每个 OpKernel 都要实现一个 Compute 函数,可以看到这个 Compute 函数首先检查了两个 Tensor 是否是矩阵,然后检查两个矩阵的形状是否符合矩阵相乘的条件,然后根据形状分配 TensorShape 并且根据 TensorShape 分配新的 Tensor (其实顺便分配的 TensorBuffer 的内存空间)。然后通过 LaunchMatMul 真正执行相乘操作,因为这个计算过程,可能是用了 GPU,所以模版是带 Device 的(GPUDevice/CPUDevice)。
1 | void Compute(OpKernelContext* ctx) override { |
LaunchMatMul 继承自 LaunchMatMulBase,在 LaunchMatMulBase 当中调用了 functor::MatMulFunctor,这个 functor 主要就会执行乘法操作,在这之前会检查一下是否其中一个元素是 vector,这样可以直接优化算出来,而不用 Eigen 库来算,这样更快,这个目前看到的是 CPU 的路径。
1 | template <typename Device, typename T> |
MatMulFunctor 在设备 d 上计算矩阵相乘的结果,其中调用的是 MatMul<CPUDevice>。
1 | template <typename Device, typename In0, typename In1, typename Out, |
这里的 contract 调用的是 TensorContractionOp (third_party/unsupported/Eigen/CXX11/src/Tensor/TensorContraction.h),跟之前说的一样,这个 Op 是计算图的一部分,要通过 eval 来做计算,计算结果是 eval 驱动的。TensorContractionOp 的构造函数就是,这负责构建左表达式和右表达式。
1 | EIGEN_DEVICE_FUNC EIGEN_STRONG_INLINE TensorContractionOp( |
真正的计算过程在 TensorContractionEvaluatorBase 里面,真正执行计算过程,计算细节就省略了主要是矩阵相乘。
CUDA
如果条件编译 GOOGLE_CUDA 的话,会使用 GPU 的代码,对应会调用到 steam executor,这个以后具体分析。
总结
Tensorflow 基于图模型的,并且是懒计算的,通过扩展可以自己用 C++ 实现新的 Op,并且也可以观察默认自带的 OpKernel 是如何实现的,对于理解 Tensorflow 的工作流程会有很大的帮助。Tensorflow 本身依赖了 Eigen,CUDA 等线性代数库或者 GPU 计算库,要看懂代码还是要多学一点线代的知识,比如 Contraction 这个概念我也是第一次晓得。