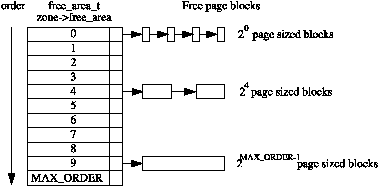
/* * PAGE_ALLOC_COSTLY_ORDER is the order at which allocations are deemed * costly to service. That is between allocation orders which should * coalesce naturally under reasonable reclaim pressure and those which * will not. */ /* 内核认为超过8个页算是大的内存分配 */ #define PAGE_ALLOC_COSTLY_ORDER 3
enum { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_RECLAIMABLE, MIGRATE_PCPTYPES, /* the number of types on the pcp lists */ MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES, #ifdef CONFIG_CMA /* * MIGRATE_CMA migration type is designed to mimic the way * ZONE_MOVABLE works. Only movable pages can be allocated * from MIGRATE_CMA pageblocks and page allocator never * implicitly change migration type of MIGRATE_CMA pageblock. * * The way to use it is to change migratetype of a range of * pageblocks to MIGRATE_CMA which can be done by * __free_pageblock_cma() function. What is important though * is that a range of pageblocks must be aligned to * MAX_ORDER_NR_PAGES should biggest page be bigger then * a single pageblock. */ MIGRATE_CMA, #endif #ifdef CONFIG_MEMORY_ISOLATION MIGRATE_ISOLATE, /* can't allocate from here */ #endif MIGRATE_TYPES };
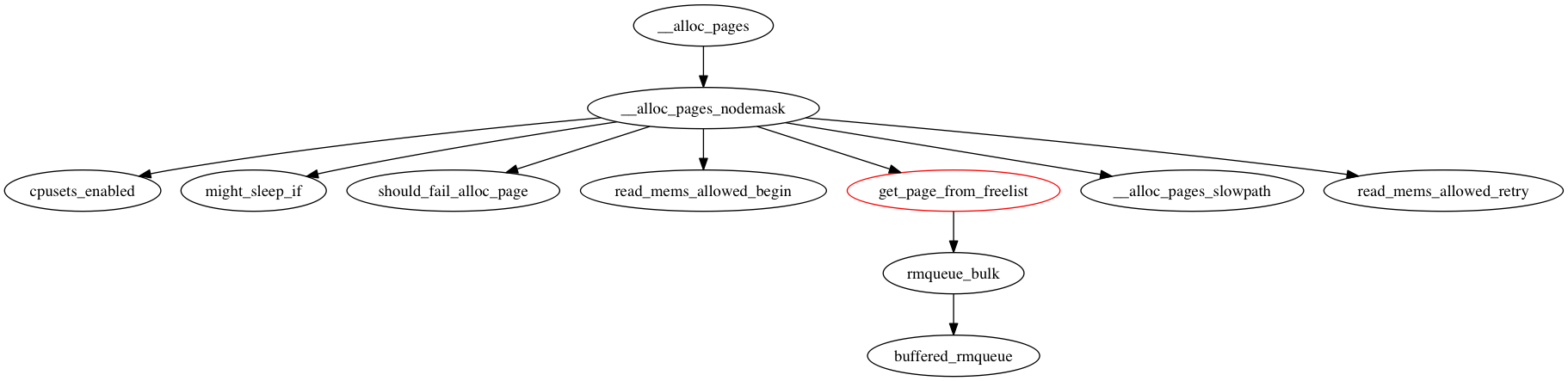
/* * Do the hard work of removing an element from the buddy allocator. * Call me with the zone->lock already held. */ static struct page *__rmqueue(struct zone *zone, unsigned int order, int migratetype) { struct page *page;
page = __rmqueue_smallest(zone, order, migratetype); if (unlikely(!page)) { if (migratetype == MIGRATE_MOVABLE) page = __rmqueue_cma_fallback(zone, order); /* MOVABLE的失败优先从cma迁移 */
/* * Go through the free lists for the given migratetype and remove * the smallest available page from the freelists */ static inline struct page *__rmqueue_smallest(struct zone *zone, unsigned int order, int migratetype) { unsigned int current_order; struct free_area *area; struct page *page;
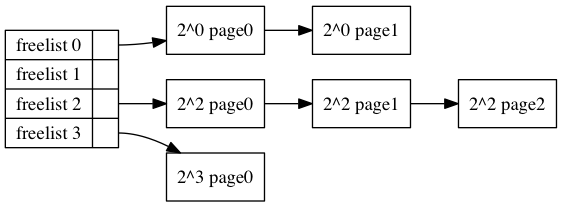
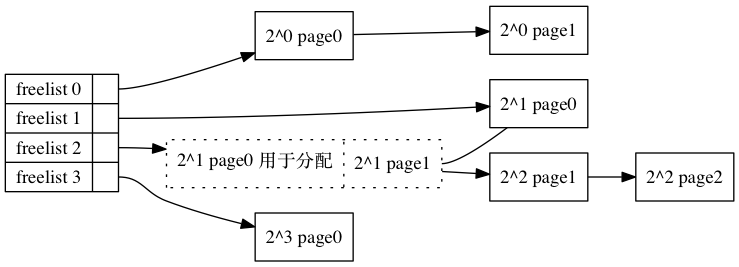
/* Find a page of the appropriate size in the preferred list */ for (current_order = order; current_order < MAX_ORDER; ++current_order) { area = &(zone->free_area[current_order]); page = list_first_entry_or_null(&area->free_list[migratetype], struct page, lru); if (!page) continue; /* 如果失败就尝试更大的块 */ list_del(&page->lru); /* 这个lru取决他的上下文,比如在这里就是free_list */ rmv_page_order(page); /* 设置flags */ area->nr_free--; /* free计数器-1 */ expand(zone, page, order, current_order, area, migratetype); set_pcppage_migratetype(page, migratetype);/* 设置page的migratetype */ return page; } return NULL; }
/* * The order of subdivision here is critical for the IO subsystem. * Please do not alter this order without good reasons and regression * testing. Specifically, as large blocks of memory are subdivided, * the order in which smaller blocks are delivered depends on the order * they're subdivided in this function. This is the primary factor * influencing the order in which pages are delivered to the IO * subsystem according to empirical testing, and this is also justified * by considering the behavior of a buddy system containing a single * large block of memory acted on by a series of small allocations. * This behavior is a critical factor in sglist merging's success. * * -- nyc */ static inline void expand(struct zone *zone, struct page *page, int low, int high, struct free_area *area, int migratetype) { unsigned long size = 1 << high;
while (high > low) { /* 从高阶向低阶迭代 */ area--; high--; size >>= 1; VM_BUG_ON_PAGE(bad_range(zone, &page[size]), &page[size]); /* guardpage TODO */ if (IS_ENABLED(CONFIG_DEBUG_PAGEALLOC) && debug_guardpage_enabled() && high < debug_guardpage_minorder()) { /* * Mark as guard pages (or page), that will allow to * merge back to allocator when buddy will be freed. * Corresponding page table entries will not be touched, * pages will stay not present in virtual address space */ set_page_guard(zone, &page[size], high, migratetype); continue; } list_add(&page[size].lru, &area->free_list[migratetype]); /* 把page放到area的free_list里面, 这个page是一个数组形式的 比如之前是8 这里变成4,那么后半部分会被留下来,前半部分会继续用于迭代 */ area->nr_free++; /* 空闲块计数器+1 */ set_page_order(&page[size], high); /* 相当于page->private = high 表示自己属于order为high的阶的block中 */ } }
/* * This array describes the order lists are fallen back to when * the free lists for the desirable migrate type are depleted */ static int fallbacks[MIGRATE_TYPES][4] = { [MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_TYPES }, [MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_TYPES }, [MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_TYPES }, #ifdef CONFIG_CMA [MIGRATE_CMA] = { MIGRATE_TYPES }, /* Never used */ #endif #ifdef CONFIG_MEMORY_ISOLATION [MIGRATE_ISOLATE] = { MIGRATE_TYPES }, /* Never used */ #endif };
/* Remove an element from the buddy allocator from the fallback list */ static inline struct page * __rmqueue_fallback(struct zone *zone, unsigned int order, int start_migratetype) { struct free_area *area; unsigned int current_order; struct page *page; int fallback_mt; bool can_steal;
/* Find the largest possible block of pages in the other list */ for (current_order = MAX_ORDER-1; current_order >= order && current_order <= MAX_ORDER-1; --current_order) { area = &(zone->free_area[current_order]); /* 遍历fallback table 找到合适的fallback migratetype 要综合考虑: 是否有超过一定阈值的空闲页,并且是可以退化的页类型 */ fallback_mt = find_suitable_fallback(area, current_order, start_migratetype, false, &can_steal); if (fallback_mt == -1) continue;
/* Remove the page from the freelists */ area->nr_free--; list_del(&page->lru); rmv_page_order(page);
expand(zone, page, order, current_order, area, start_migratetype); /* * The pcppage_migratetype may differ from pageblock's * migratetype depending on the decisions in * find_suitable_fallback(). This is OK as long as it does not * differ for MIGRATE_CMA pageblocks. Those can be used as * fallback only via special __rmqueue_cma_fallback() function */ set_pcppage_migratetype(page, start_migratetype);
/* * Structure for holding the mostly immutable allocation parameters passed * between functions involved in allocations, including the alloc_pages* * family of functions. * * nodemask, migratetype and high_zoneidx are initialized only once in * __alloc_pages_nodemask() and then never change. * * zonelist, preferred_zone and classzone_idx are set first in * __alloc_pages_nodemask() for the fast path, and might be later changed * in __alloc_pages_slowpath(). All other functions pass the whole strucure * by a const pointer. */ struct alloc_context { struct zonelist *zonelist; nodemask_t *nodemask; struct zoneref *preferred_zoneref; int migratetype; enum zone_type high_zoneidx; bool spread_dirty_pages; };
struct per_cpu_pages { int count; /* number of pages in the list */ int high; /* high watermark, emptying needed */ int batch; /* chunk size for buddy add/remove */
/* Lists of pages, one per migrate type stored on the pcp-lists */ struct list_head lists[MIGRATE_PCPTYPES]; };
/* * Freeing function for a buddy system allocator. * * The concept of a buddy system is to maintain direct-mapped table * (containing bit values) for memory blocks of various "orders". * The bottom level table contains the map for the smallest allocatable * units of memory (here, pages), and each level above it describes * pairs of units from the levels below, hence, "buddies". * At a high level, all that happens here is marking the table entry * at the bottom level available, and propagating the changes upward * as necessary, plus some accounting needed to play nicely with other * parts of the VM system. * At each level, we keep a list of pages, which are heads of continuous * free pages of length of (1 << order) and marked with _mapcount * PAGE_BUDDY_MAPCOUNT_VALUE. Page's order is recorded in page_private(page) * field. * So when we are allocating or freeing one, we can derive the state of the * other. That is, if we allocate a small block, and both were * free, the remainder of the region must be split into blocks. * If a block is freed, and its buddy is also free, then this * triggers coalescing into a block of larger size. * * -- nyc */
static inline void __free_one_page(struct page *page, /* 把page加回到free_list里面 */ unsigned long pfn, struct zone *zone, unsigned int order, int migratetype) { unsigned long page_idx; unsigned long combined_idx; unsigned long uninitialized_var(buddy_idx); struct page *buddy; unsigned int max_order;
continue_merging: while (order < max_order - 1) { buddy_idx = __find_buddy_index(page_idx, order);/* 获取buddy的下标 */ buddy = page + (buddy_idx - page_idx); /* 根据相对距离得到buddy page */ if (!page_is_buddy(page, buddy, order)) /* 如果不是buddy就结束合并 */ goto done_merging; /* * Our buddy is free or it is CONFIG_DEBUG_PAGEALLOC guard page, * merge with it and move up one order. */ if (page_is_guard(buddy)) { clear_page_guard(zone, buddy, order, migratetype); } else { /* 把buddy从free_area当中移除 */ list_del(&buddy->lru); zone->free_area[order].nr_free--; rmv_page_order(buddy); } combined_idx = buddy_idx & page_idx; page = page + (combined_idx - page_idx); page_idx = combined_idx; order++; /* 向上合并 */ } if (max_order < MAX_ORDER) { /* If we are here, it means order is >= pageblock_order. * We want to prevent merge between freepages on isolate * pageblock and normal pageblock. Without this, pageblock * isolation could cause incorrect freepage or CMA accounting. * * We don't want to hit this code for the more frequent * low-order merging. */ /* 在这里说明已经超出了pageblock的order, 可能在不同的migratetype的block边界了,这里再检查一次是不是isolate, 不允许节点间迁移的page, 如果是的话就要结束合并的迭代,不然继续向上合并 */ if (unlikely(has_isolate_pageblock(zone))) { int buddy_mt;
/* * If this is not the largest possible page, check if the buddy * of the next-highest order is free. If it is, it's possible * that pages are being freed that will coalesce soon. In case, * that is happening, add the free page to the tail of the list * so it's less likely to be used soon and more likely to be merged * as a higher order page */ if ((order < MAX_ORDER-2) && pfn_valid_within(page_to_pfn(buddy))) { /* 这个条件判断没有合并到最大块, 内核认为很有可能接下来这个块和其他free的块合并, 从减少碎片的角度来说会更倾向于放到链表的末尾, 让这个块的free状态保持久一点, 更有机会被合并成更大的块 */ struct page *higher_page, *higher_buddy; combined_idx = buddy_idx & page_idx; /* 合并后的idx */ higher_page = page + (combined_idx - page_idx); /* 合并后的page */ buddy_idx = __find_buddy_index(combined_idx, order + 1); /* 向上寻找buddy */ higher_buddy = higher_page + (buddy_idx - combined_idx); if (page_is_buddy(higher_page, higher_buddy, order + 1)) { list_add_tail(&page->lru, &zone->free_area[order].free_list[migratetype]); goto out; } }