/* * This is the ISR for the vortex series chips. * full_bus_master_tx == 0 && full_bus_master_rx == 0 */
static irqreturn_t vortex_interrupt(int irq, void *dev_id) { struct net_device *dev = dev_id; struct vortex_private *vp = netdev_priv(dev); void __iomem *ioaddr; int status; int work_done = max_interrupt_work; int handled = 0; unsigned int bytes_compl = 0, pkts_compl = 0;
ioaddr = vp->ioaddr; spin_lock(&vp->lock);
status = ioread16(ioaddr + EL3_STATUS); // 从ioremap的地址当中读取网卡的状态,这个是设备规定的地址
if (vortex_debug > 6) pr_debug("vortex_interrupt(). status=0x%4x\n", status);
// 在中断处理的时候,设备是关中断的,这个时候可以通过观察这个status来检查设备是否有中断到来. if ((status & IntLatch) == 0) // 有中断需要处理,但是可能已经被其他中断处理函数处理了 goto handler_exit; /* No interrupt: shared IRQs cause this */ handled = 1;
if (status & IntReq) { // 中断请求 status |= vp->deferred; vp->deferred = 0; }
if (status == 0xffff) /* h/w no longer present (hotplug)? */ goto handler_exit;
if (vortex_debug > 4) pr_debug("%s: interrupt, status %4.4x, latency %d ticks.\n", dev->name, status, ioread8(ioaddr + Timer));
spin_lock(&vp->window_lock); window_set(vp, 7);
do { if (vortex_debug > 5) pr_debug("%s: In interrupt loop, status %4.4x.\n", dev->name, status); if (status & RxComplete) // 中断表示接收完成的时候调用 vortex_rx vortex_rx(dev);
if (status & TxAvailable) { // 中断表示可以传输的时候 if (vortex_debug > 5) pr_debug(" TX room bit was handled.\n"); /* There's room in the FIFO for a full-sized packet. */ iowrite16(AckIntr | TxAvailable, ioaddr + EL3_CMD); netif_wake_queue (dev); }
if (status & DMADone) {// 表示发送完成可以清除sk_buff了 if (ioread16(ioaddr + Wn7_MasterStatus) & 0x1000) { iowrite16(0x1000, ioaddr + Wn7_MasterStatus); /* Ack the event. */ pci_unmap_single(VORTEX_PCI(vp), vp->tx_skb_dma, (vp->tx_skb->len + 3) & ~3, PCI_DMA_TODEVICE); pkts_compl++; bytes_compl += vp->tx_skb->len; dev_kfree_skb_irq(vp->tx_skb); /* Release the transferred buffer */ if (ioread16(ioaddr + TxFree) > 1536) { /* * AKPM: FIXME: I don't think we need this. If the queue was stopped due to * insufficient FIFO room, the TxAvailable test will succeed and call * netif_wake_queue() */ netif_wake_queue(dev); } else { /* Interrupt when FIFO has room for max-sized packet. */ iowrite16(SetTxThreshold + (1536>>2), ioaddr + EL3_CMD); netif_stop_queue(dev); } } } /* Check for all uncommon interrupts at once. */ if (status & (HostError | RxEarly | StatsFull | TxComplete | IntReq)) { if (status == 0xffff) break; if (status & RxEarly) vortex_rx(dev); spin_unlock(&vp->window_lock); vortex_error(dev, status); spin_lock(&vp->window_lock); window_set(vp, 7); }
if (--work_done < 0) { // 最多处理work_done个frame pr_warn("%s: Too much work in interrupt, status %4.4x\n", dev->name, status); /* Disable all pending interrupts. */ do { vp->deferred |= status; // 把当前状态保存起来等下次中断的时候处理 iowrite16(SetStatusEnb | (~vp->deferred & vp->status_enable), ioaddr + EL3_CMD); iowrite16(AckIntr | (vp->deferred & 0x7ff), ioaddr + EL3_CMD); } while ((status = ioread16(ioaddr + EL3_CMD)) & IntLatch); // 把中断清掉? /* The timer will reenable interrupts. */ mod_timer(&vp->timer, jiffies + 1*HZ); break; } /* Acknowledge the IRQ. */ iowrite16(AckIntr | IntReq | IntLatch, ioaddr + EL3_CMD); } while ((status = ioread16(ioaddr + EL3_STATUS)) & (IntLatch | RxComplete));// 当有pending的中断并且是接收完成的状态
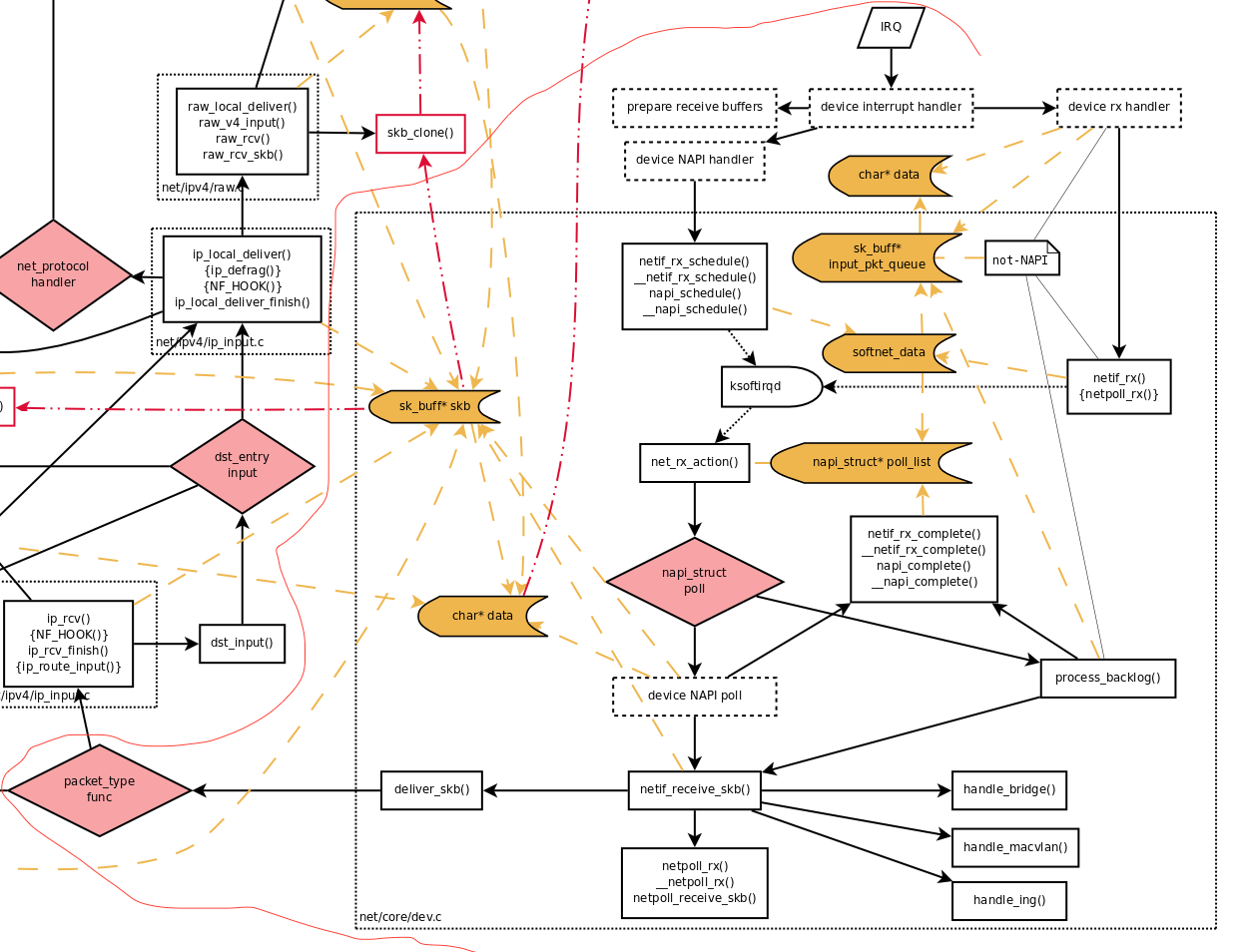
/* * enqueue_to_backlog is called to queue an skb to a per CPU backlog * queue (may be a remote CPU queue). */ static int enqueue_to_backlog(struct sk_buff *skb, int cpu, unsigned int *qtail) { struct softnet_data *sd; unsigned long flags; unsigned int qlen;
rps_lock(sd); if (!netif_running(skb->dev)) // 如果设备已经没有运行的直接丢frame goto drop; qlen = skb_queue_len(&sd->input_pkt_queue); // 获取softnet_data的&sk_buff的队列长度 if (qlen <= netdev_max_backlog && !skb_flow_limit(skb, qlen)) { // 如果没有超过最大长度并且没有被限制 if (qlen) { enqueue: __skb_queue_tail(&sd->input_pkt_queue, skb); input_queue_tail_incr_save(sd, qtail); rps_unlock(sd); local_irq_restore(flags); // 加入队列并且开中断 return NET_RX_SUCCESS; } // 如果队列为空可以尝试调度 backlog device, // 再把frame加入到队列当中。 /* Schedule NAPI for backlog device * We can use non atomic operation since we own the queue lock */ if (!__test_and_set_bit(NAPI_STATE_SCHED, &sd->backlog.state)) { if (!rps_ipi_queued(sd)) ____napi_schedule(sd, &sd->backlog); } goto enqueue; }
/* If softirq window is exhausted then punt. * Allow this to run for 2 jiffies since which will allow * an average latency of 1.5/HZ. */ if (unlikely(budget <= 0 || // 如果budge耗尽或者超过了两个jiffies就会停止 time_after_eq(jiffies, time_limit))) { sd->time_squeeze++; break; } }
static int process_backlog(struct napi_struct *napi, int quota) { int work = 0; struct softnet_data *sd = container_of(napi, struct softnet_data, backlog);
/* Check if we have pending ipi, its better to send them now, * not waiting net_rx_action() end. */ if (sd_has_rps_ipi_waiting(sd)) { local_irq_disable(); net_rps_action_and_irq_enable(sd); }
rps_lock(sd); if (skb_queue_empty(&sd->input_pkt_queue)) { /* * Inline a custom version of __napi_complete(). * only current cpu owns and manipulates this napi, * and NAPI_STATE_SCHED is the only possible flag set * on backlog. * We can use a plain write instead of clear_bit(), * and we dont need an smp_mb() memory barrier. */ napi->state = 0; rps_unlock(sd);
if (status & TxAvailable) { // 中断表示可以传输的时候 if (vortex_debug > 5) pr_debug(" TX room bit was handled.\n"); /* There's room in the FIFO for a full-sized packet. */ iowrite16(AckIntr | TxAvailable, ioaddr + EL3_CMD); netif_wake_queue (dev); }
就是说当状态可用的时候,尝试调用netif_wake_queue来触发frame的发送。
首先来看一下如何选择发送的设备。
1 2 3 4 5 6 7 8 9 10 11
/** * netif_wake_queue - restart transmit * @dev: network device * * Allow upper layers to call the device hard_start_xmit routine. * Used for flow control when transmit resources are available. */ static inline void netif_wake_queue(struct net_device *dev) { netif_tx_wake_queue(netdev_get_tx_queue(dev, 0)); }
/* * Transmit possibly several skbs, and handle the return status as * required. Holding the __QDISC___STATE_RUNNING bit guarantees that * only one CPU can execute this function. * * Returns to the caller: * 0 - queue is empty or throttled. * >0 - queue is not empty. */ int sch_direct_xmit(struct sk_buff *skb, struct Qdisc *q, struct net_device *dev, struct netdev_queue *txq, spinlock_t *root_lock, bool validate) { int ret = NETDEV_TX_BUSY;
/* And release qdisc */ spin_unlock(root_lock);
/* Note that we validate skb (GSO, checksum, ...) outside of locks */ if (validate) skb = validate_xmit_skb_list(skb, dev);
if (likely(skb)) { HARD_TX_LOCK(dev, txq, smp_processor_id()); if (!netif_xmit_frozen_or_stopped(txq)) skb = dev_hard_start_xmit(skb, dev, txq, &ret);