MultiRaft 解析
援引自 cockroach 博客 的解释
cockroach 的底层 scaling 存储本身可以认为是一张无限大的有序 KV map,上层封装了一层 SQL。他 sharding 的方式是通过 range 实现的。对一组 64M 大小数据的范围内的 key 做冗余,用二级 metadata range 可以理论上存储 4EB 的数据。
举个例子,五节点打散三副本的一个 range 做冗余,是成本性能和效率上比较典型的一个折衷。像你说的 leader 集中的情况是比较少的,因为三副本是打散分布到不同节点上的,所以三副本的交集不会太集中,单点的压力还是很少的。
另外租约的存在(不知道算不算在 multi raft 算法内),也可以缓解集中化的压力,通过获得授权的租约旁路一些“可以本地化”的请求(比如只对一个 replica 的操作以及一些能保证数据不变的一段时间的读请求),来缓解主的压力,这个最早我记得在 GFS 里面看到过是这么设计的。
另外 gossip 的协议有点像交换机的生成树协议,是通过互相传播自己的负载和位置信心来传播信息的,没有中心化的决策节点,这样的好处就是无中心化,不会依靠一个中心的节点来做负载均衡,而且整个系统就需要一个二进制文件不依赖任何的其他服务。
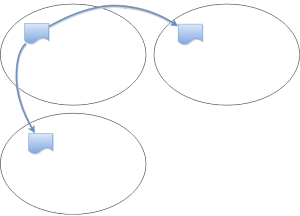
如图是一个 range 在三节点上的三副本的一个 raft group 之间有网路通信。
但是如果 range 变多的话,就会很复杂,如下图,是四个节点之间大概 8 个 (如果我没看错颜色的话) range 的 raft group 之间通信。
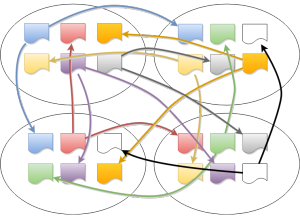
很明显网络 RoundTrip 太多了。针对这个的优化就是 MultiRaft 了,说白了就是把网络请求 batch up,变成下面的形式。
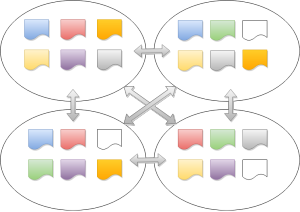
这样网络压力就会小很多。针对这个的优化和应用本身的实现是耦合的,作者也尝试把这个优化加到 etcd/raft 当中,但是最后的决定是增加 RawNode 这样的无线程安全的接口给应用层实用,方便对心跳等请求的合并,所以你会看到有个非线程安全的 RawNode 的实现。
具体到 cockroach 的实现是可以找到相应的代码的,省略无关代码就如下。
在发送消息的时候检查是否有可以整合的请求。
1 | func (r *Replica) sendRaftMessage(ctx context.Context, msg raftpb.Message) { |
循环取出缓存的消息,注意因为是整合了消息,所以对消息来说有延迟,这里稍微加快了频率,弥补这个延迟。
1 | // Since coalesced heartbeats adds latency to heartbeat messages, it is |
在 Store 这个层面是对每个 Replica (一个 raft group 的成员) 是有感知的,但是每个 raft group 是独立的,只是在发送是会检查对方节点是否和现在的 raft group 有交集,
从而尝试合并消息的发送,你可以理解为在节点之间的消息通道上对不同 raft group 之间多路复用。
这就是 MultiRaft 对多个 raft group 的网络吞吐做的一个优化,代价是可能造成消息的延迟,因为毕竟是被缓存到队列里了。