SQL 隔离级别
不同的隔离级别有不同的约束,而且不一定是子集和超集的关系,约束可能是交集的。这里尝试循序渐进的加强锁的级别和实现方式来阐述各个隔离级别的区别,由此可以选择在实际开发中适合业务的隔离策略。我自己最近也在调研 cockroachdb 比较关心事务这方面的性能,cockroachdb 的事务主要是两个级别,SI 和 SSI,会在下面提到。
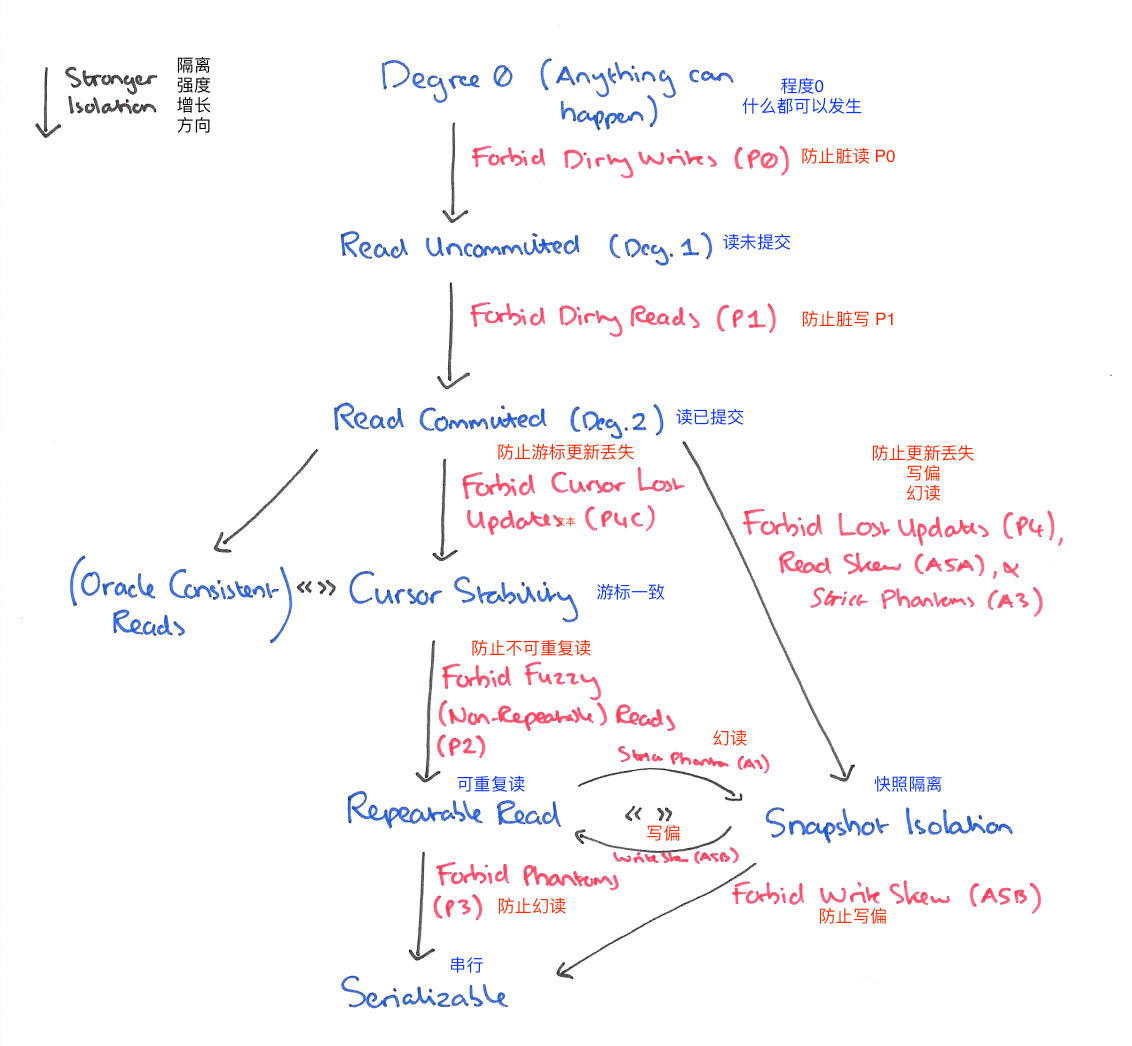
总视图
这是各个隔离级别的一个关系,可以看出不一定是包含与被包含的关系(因为完整的隔离级别不只 4 种)。
定义
长期锁:到事务结束就释放的锁
短期锁:对相关数据操作完成就释放的锁
这里提到的写锁和排他锁可以互换,读锁和共享锁可以互换,长期锁也被称为二阶段锁,就是事务某个时候锁上了算一个阶段,最后一起释放算一个阶段。
断言型:基于先判的锁的修饰词,比如 WHERE 语句指定的范围就是预测型,如果没有 WHERE 可能就是整张表。
如果没有断言修饰的话,锁就是有指定数据的锁,也就是有明确索引的锁。
缩写 P(Phenomena) A(Anomalies)
P0 dirty write (脏写)
现象:
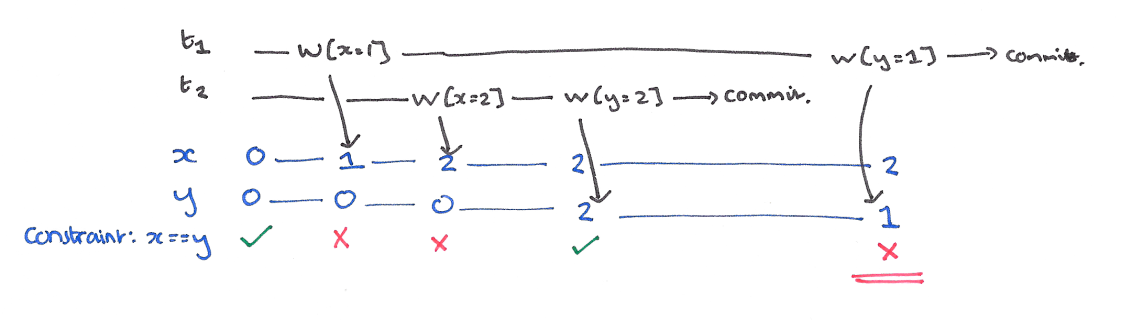
我们最开始的阶段是一切皆有可能发生,没有任何锁,所以碰到的第一个问题是脏写。
脏写导致的问题是,破坏数据的一致性,一个事务 (T1) 如果覆盖了另一个正在执行事务 (T2) 之前写入的值的时候就会导致脏写。比如 T1 写入 x=y=1 并且 T2 写入 x=y=2,但是整个数据的一致性就被破坏了。
解决:
对 x 和 y 持有长期写锁。基本上没有事务不拿长期写锁的,不然数据库连回退的可能都没有。防止脏写以后会出现新的现象,脏读。
P1 dirty read (脏读 read uncommited)
现象
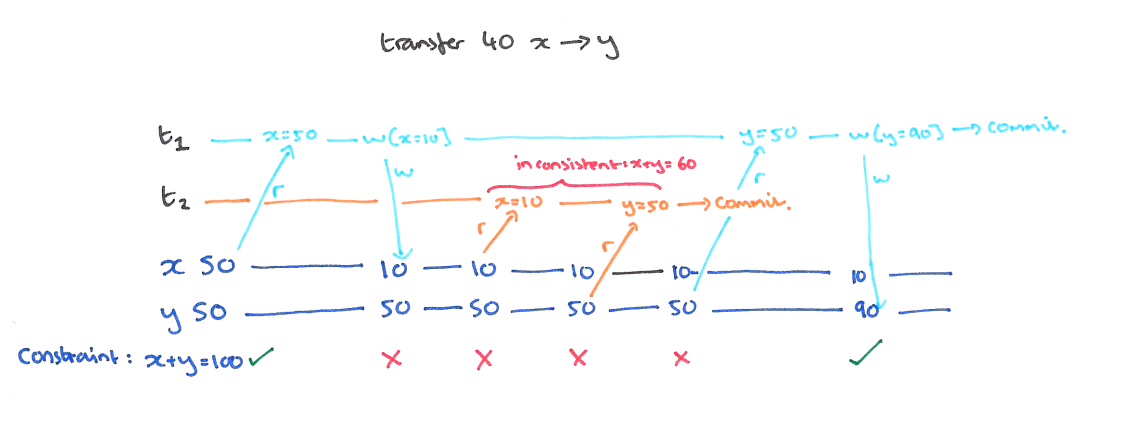
事务 (T1) 写入的值被正在执行的事务 (T2) 读取。比如 x 向 y 转 40,在 x 写入以后,T2 看到的总和只有 60。
网上很多人把这个级别算作了脏写其实不是很严格,最开始那个 P0 级别才算是脏写。
解决
使用短期读锁和长期写锁,长期写锁可以防止 T2 的 X 读数据,短期读锁可以防止 T1 的 y 写不了(如果使用长期读锁就被阻塞到 T1 结束了)。解决脏读问题,我们又面临的问题是不可重复读
P2 non-repeatable read (不可重复读)
现象
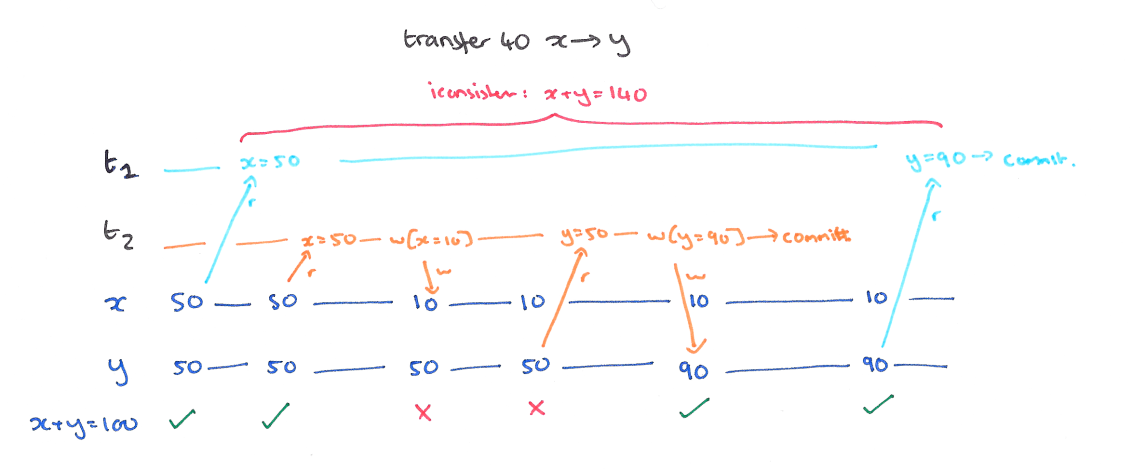
当正在执行的事务 (T1) 读取的值被事务 (T2) 写入的时候,对 T1 来说就出现了不一致。例如下图,X 在被读取之后又被 T2 写入,这个时候总的钱数出现了不一致。
解决
使用长期读锁和长期写锁,也就是 T2 的 X 要等 T1 提交之后才能写入。对于不可重复读的问题。不过短期的断言型读锁也是足够的,因为 X 和 Y 如果都提前读取出来还是能保持一致的。我们解决了不可重复读以后,还会碰到幻读的情况。
P3 phantom (幻读)
现象
幻读发生在正在执行的事务 T1 有断言的读 (select where) 时,另外一个事务 T2 执行了和断言集合有交集的插入操作。
比如 T1 在 T2 之前读到了员工总数是 3,但是 T2 执行的时候有交集,插入了新的数据,这个时候员工总数是 4,但是 T1 如果再读取的话,就会发现员工总数变成了 4,而不是最初的 3,这就是幻读。
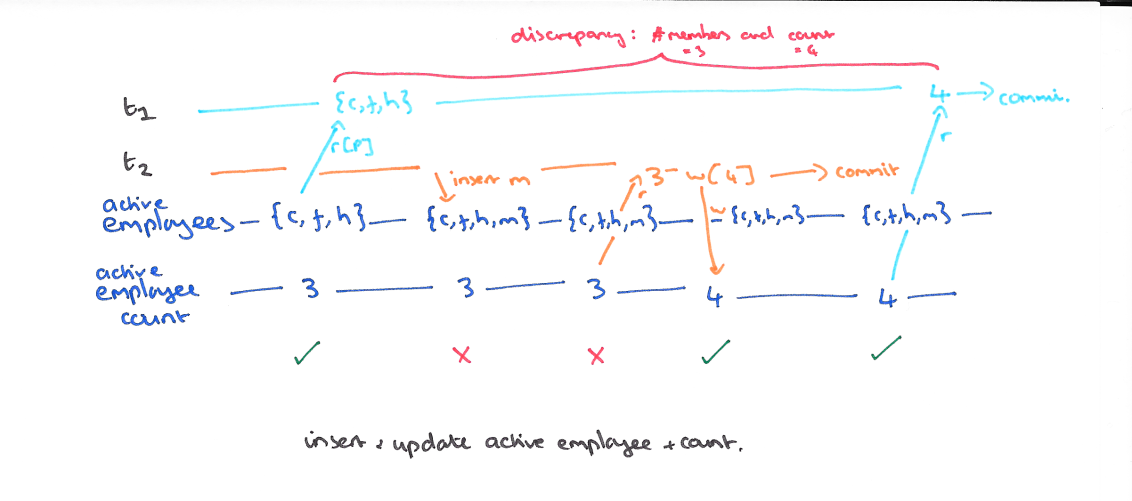
解决
解决幻读的方式是使用长期(断言型)读锁和写锁。也就是不允许在这个范围内进行插入操作。解决了幻读以后我们的事务就完全串行化了,这样的事务并发度是最弱的。
P4 update lost (更新丢失)
常见的 4 个隔离级别说完了以后我们看一下剩下的部分,注意更新丢失这个现象不是比幻读更约束的现象,这个是在基于防止脏读以后可能会出现的现象,会被可重复读防止。
现象
事务 T2 提交的写被其他事务覆盖,首先,没有脏写,因为 T2 已经提交,其次没有脏读,因为在写之后没有读操作,这样的现象称为更新丢失。
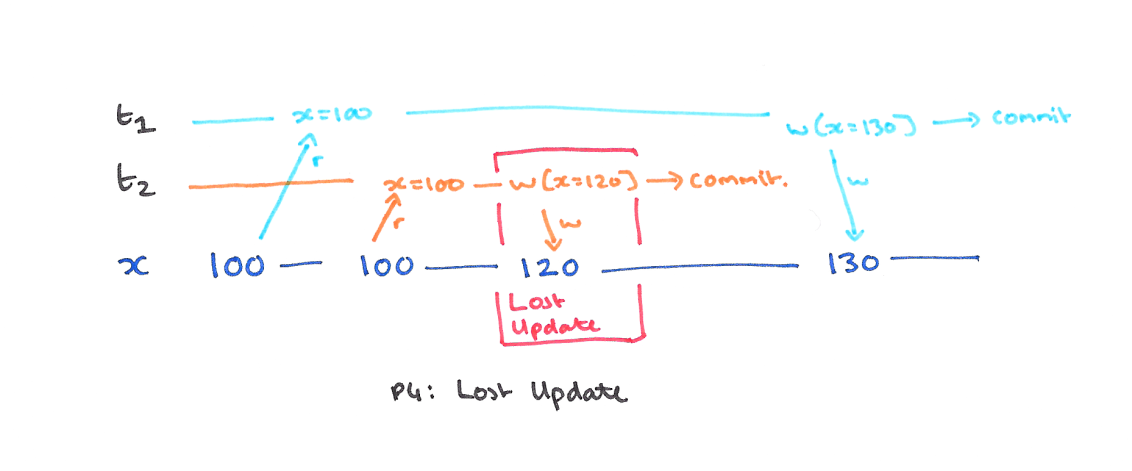
解决
升级到可重复读就可以了。
P4C cursor update lost (游标更新丢失)
现象
和更新丢失是一样的,这个只是约束在了游标操作的时候,事务 (T1) 对游标下的数据进行读之后被另一个事务 (T2) 提交了,在游标下的数据写之后让,T1 的写导致 T2 的更新丢失。
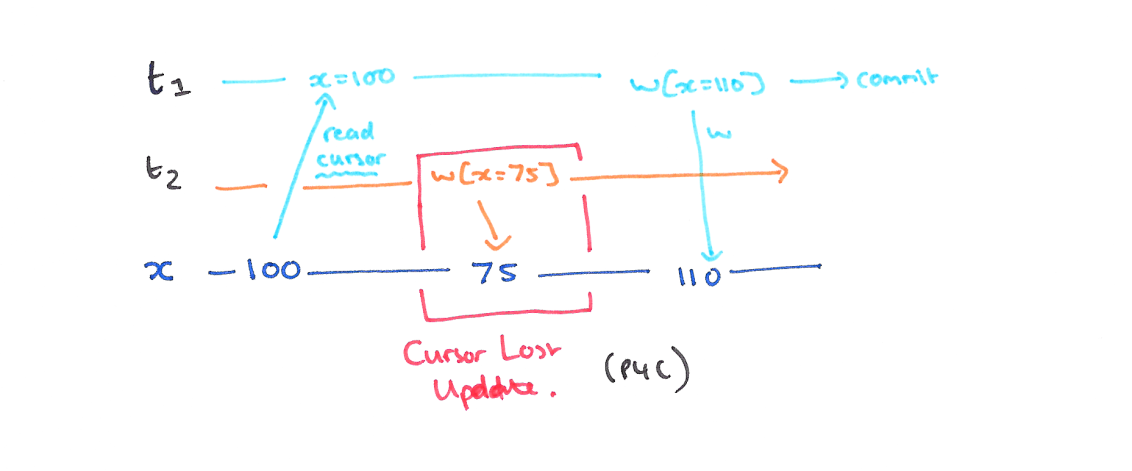
解决
在游标移动或者释放之前,都不释放锁,这个是到达可重复读之前的一个插曲。这个也是在读提交的阶段会发生的事情。
A5A read skew (读偏)
偏可以理解为不一致,这个是发生在多个数据之间有一个总的约束的时候。
现象
总的钱是 100,但是从 T1 的角度,总的钱数是 (50+75),因为只有短期读锁。
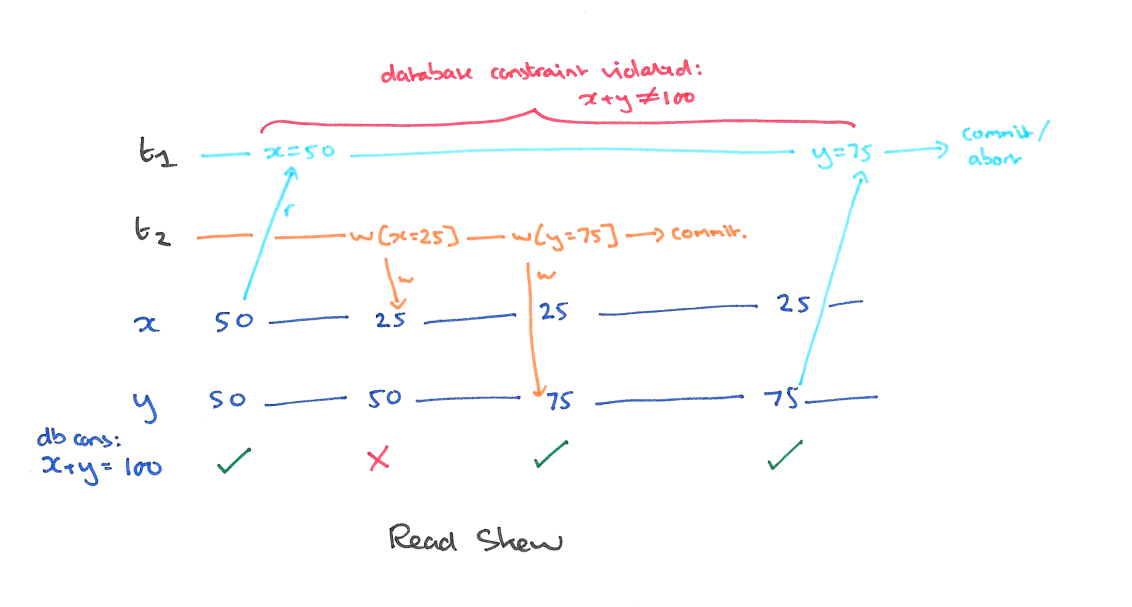
解决
使用快照隔离 (Snapshot Isolation),快照隔离是基于 MVCC 的。当一个 T 事务开始的时候,T 会获得一个抽象的时间戳(版本),当对数据 X 进行读取的时候,并不是直接看到最新写入的数据而是在 T 开始前的所有执行中的事务中最后一个对 X 标记的版本(如果 T 修改过 X,那么看到的是自己的版本)。也就是说 T 是基于当前的数据库的一个镜像进行操作的,有点类似于 Copy And Swap,而 T 开始执行是获得的版本就是这个快照的凭证。这样能保证所有的读都是基于一个一致的状态获取的。
SI 解决冲突的方法一般是 “First-Commiter-Wins” 也就是说,如果两个并发的事务修改了同一个数据,先写的事务会成功,而后写的事务会发现版本和原本的不一致而退出事务。
以我们的例子来说的话,T1 的 y 只会读到自己开始时候的版本,也就是 50,而不是 75,这样读偏就解决了。但是快照隔离还是不能解决另一个问题,就是写偏。这是我们要面临的新问题。
A5B write skew (写偏)
现象
这个和读偏类似,只不过,不一致在了整个系统上。T1 写锁有 y 的新版本,T2 写锁有 x 的新版本,他们没有写冲突,导致最后系统不一致,x+y 的钱变多了。
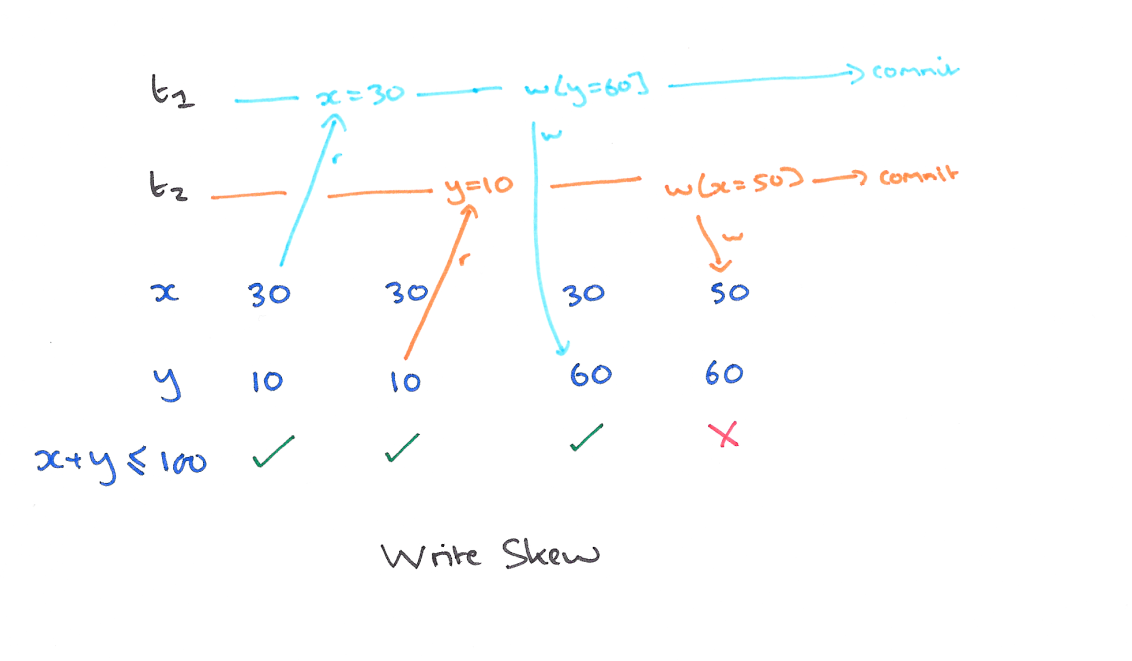
解决
目前快照隔离的算法有很多,参考 cockroachDB 使用的论文的话,可以说,通过对版本依赖构成有向图,解决成环问题,以此达到串行快照隔离的级别。
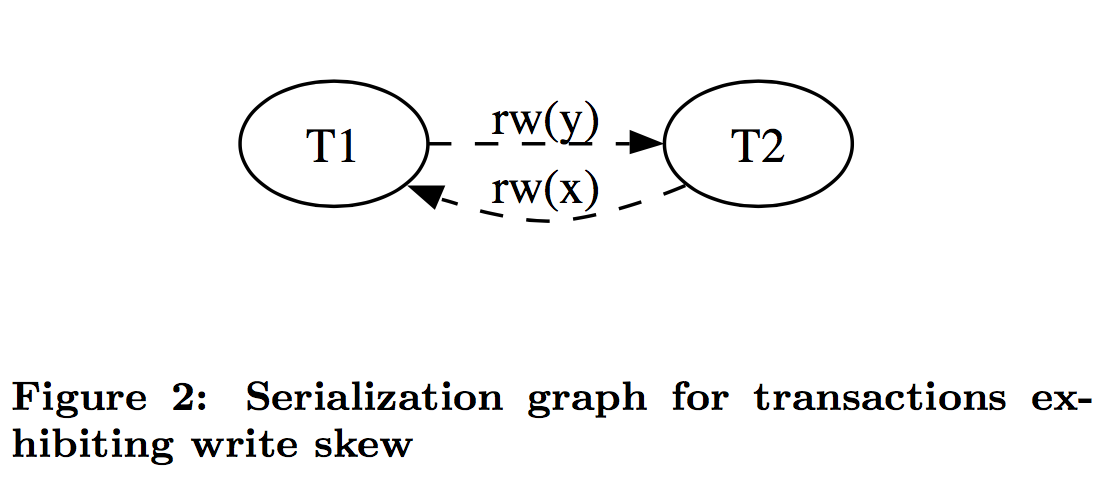
比如上面的例子,如果 T1 在 y 读了之后写了一个版本的 y 就构成一个先读后写的 rw(y) 依赖,类似的 T2 对 T1 构成了一个先读后写的 rw(x) 依赖。还有两种无害的依赖是先写后读 (wr) 和先写后写 (ww)。论文中阐述了,造成写偏的条件是成环,并且环中有两个连续的 rw 依赖。也就是下面这种形式。
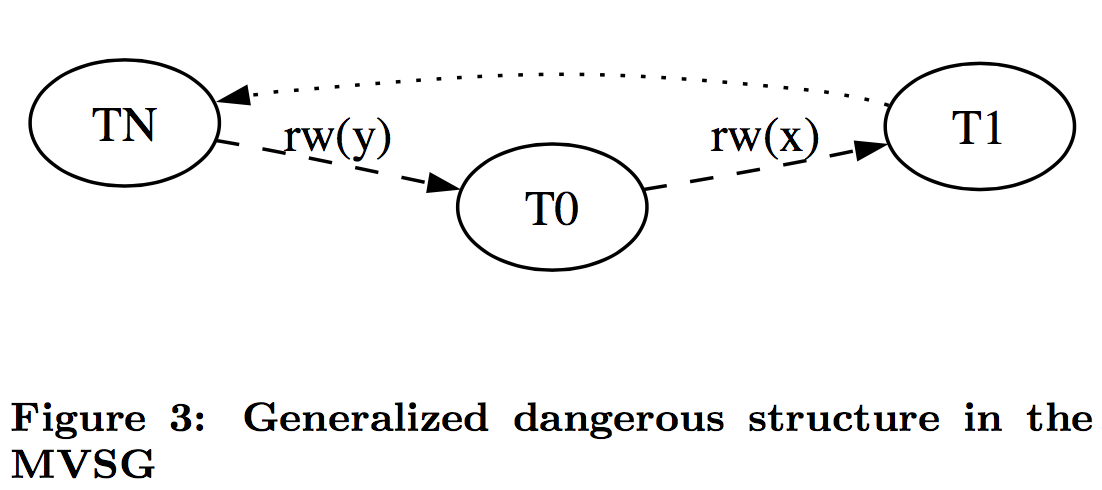
这个问题的关键是,检查成环这件事情,就跟操作系统检查死锁一样,消耗太大了,性能上不能接受,所以这个实现的妥协是,把检查放宽,让一些无害的条件也被认定为有害,通过重试来恢复执行,至少防止错误的发生。
这个条件是只要有两个连续的 rw 依赖就会放弃提交,即使没有成环。这个检查发生在读的时候如果发现读的版本和自己开始之前的版本不一致就会找到依赖的事务,构建一条入边,另一个事务构建一条出边,如果某个事务入边出边都有 rw 边,这个节点就会被作为嫌疑人。当然还有其他关于串行 snapshot 隔离的论文可以参考。
其他
Oracle Consistent Read 也算是另一种快照级别的隔离。
参考文献