// InitFunc is used to launch a particular controller. It may run additional "should I activate checks". // Any error returned will cause the controller process to `Fatal` // The bool indicates whether the controller was enabled. type InitFunc func(ctx ControllerContext) (bool, error)
// Run starts an asynchronous loop that monitors the status of cluster nodes. func(nc *Controller) Run(stopCh <-chanstruct{}) { defer utilruntime.HandleCrash()
glog.Infof("Starting node controller") defer glog.Infof("Shutting down node controller")
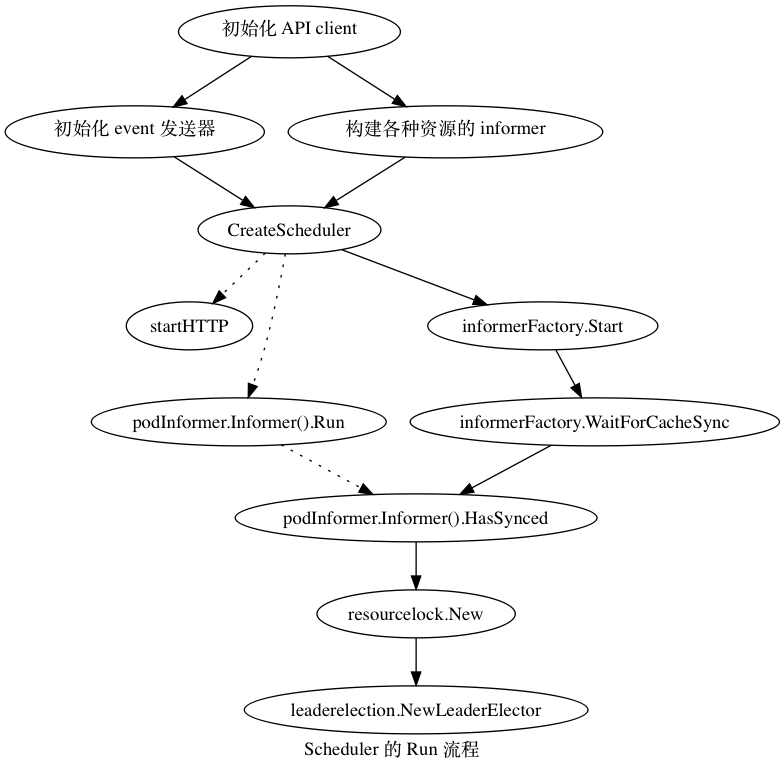
if !controller.WaitForCacheSync("node", stopCh, nc.nodeInformerSynced, nc.podInformerSynced, nc.daemonSetInformerSynced) { return }
// Incorporate the results of node status pushed from kubelet to master. go wait.Until(func() { if err := nc.monitorNodeStatus(); err != nil { glog.Errorf("Error monitoring node status: %v", err) } }, nc.nodeMonitorPeriod, wait.NeverStop)
if nc.runTaintManager { go nc.taintManager.Run(wait.NeverStop) }
if nc.useTaintBasedEvictions { // Handling taint based evictions. Because we don't want a dedicated logic in TaintManager for NC-originated // taints and we normally don't rate limit evictions caused by taints, we need to rate limit adding taints. go wait.Until(nc.doNoExecuteTaintingPass, scheduler.NodeEvictionPeriod, wait.NeverStop) } else { // Managing eviction of nodes: // When we delete pods off a node, if the node was not empty at the time we then // queue an eviction watcher. If we hit an error, retry deletion. go wait.Until(nc.doEvictionPass, scheduler.NodeEvictionPeriod, wait.NeverStop) }
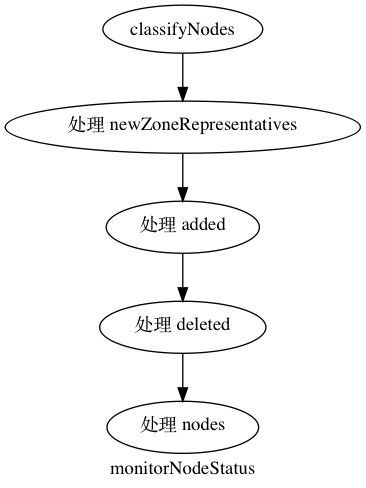
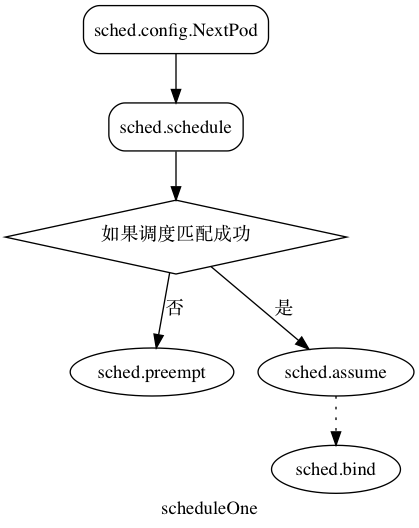
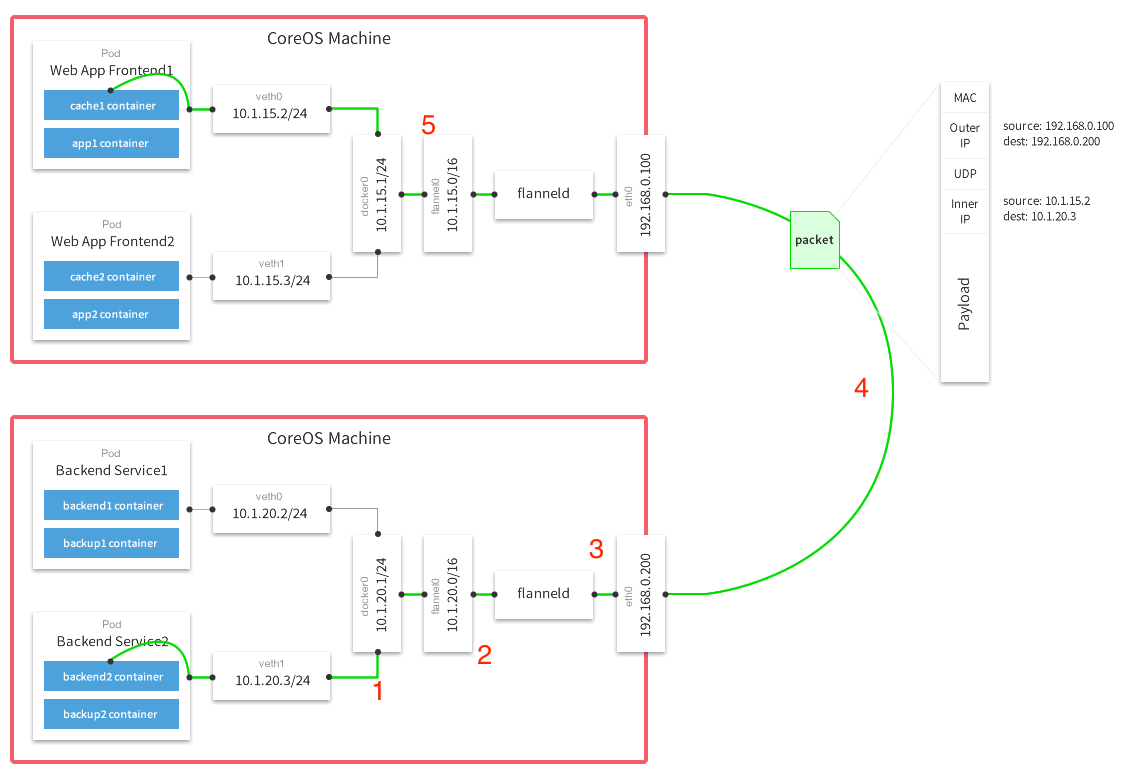
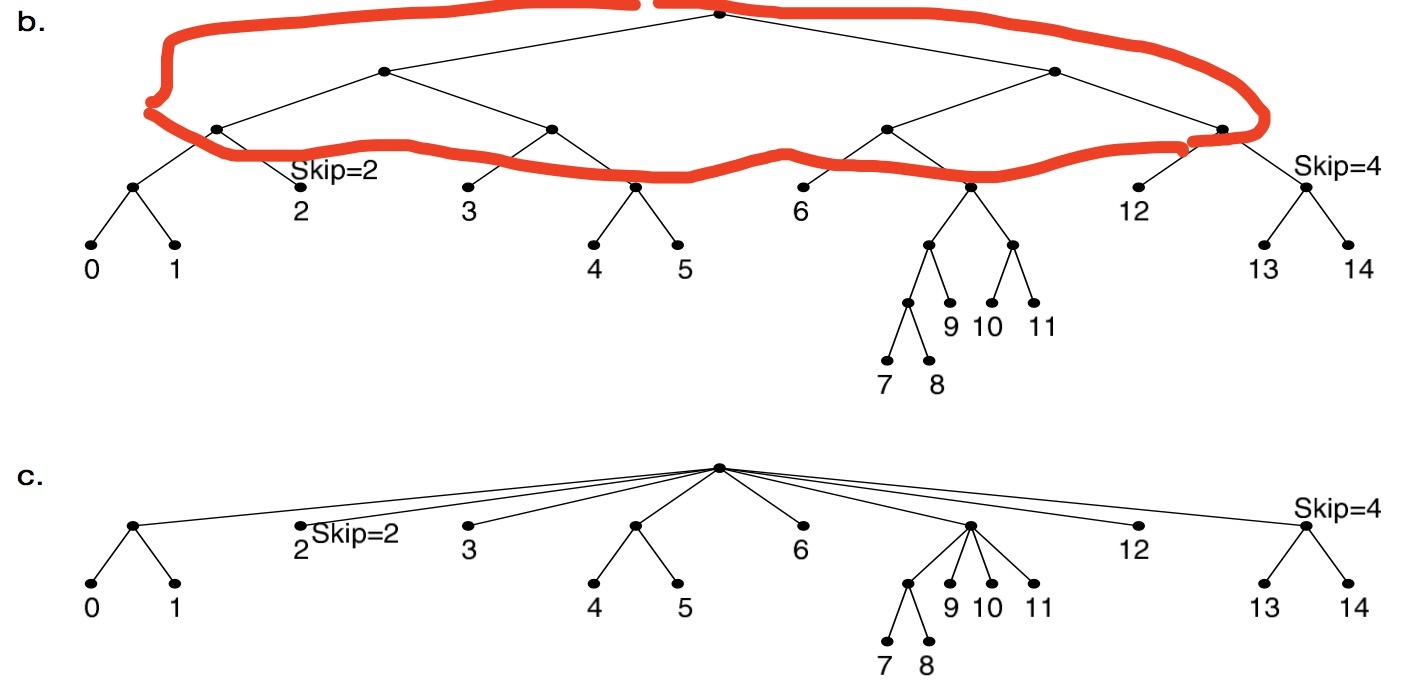
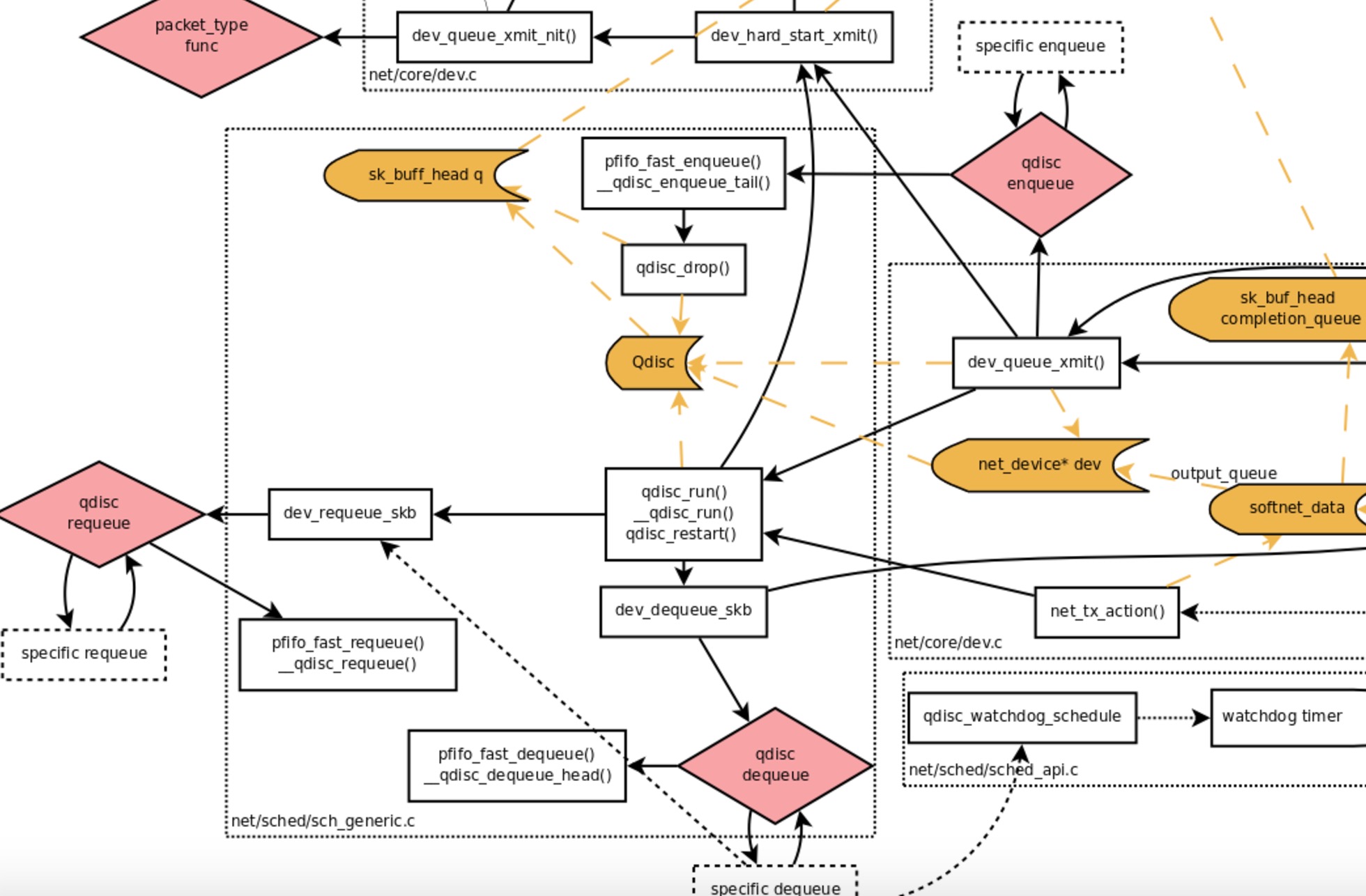
nodeController 主要分成两部分,一部分是 monitorNodeStatus , 它首先从 informer 的 cache 当中 list 新添加的节点和删除的节点,和 newZoneRepresentations。node 是分 zone 的,这在单可用区的 cluster 当中是个空字符串,但是如果 labels 中有 failure-domain.beta.kubernetes.io/zone 和 failure-domain.beta.kubernetes.io/region 就会构成不同的可用区的划分, 这个适用于仅仅在一家云厂商分不同可用区的时候可以用到。这篇文档 描述了多 zone 的 cluster 的内容,没有 zone 有相应的可用状态,如果某个 zone 变成不可用需要把 pod 从这个 zone 当中剔除,所以 pod 的 failover 是以 zone 为单位的。
for { select { case <-stopCh: break case nodeUpdate := <-tc.nodeUpdateChannel: tc.handleNodeUpdate(nodeUpdate) case podUpdate := <-tc.podUpdateChannel: // If we found a Pod update we need to empty Node queue first. priority: for { select { case nodeUpdate := <-tc.nodeUpdateChannel: tc.handleNodeUpdate(nodeUpdate) default: break priority } } // After Node queue is emptied we process podUpdate. tc.handlePodUpdate(podUpdate) } }
最后是 eviction 的部分,基于 eviction 的会把 pod 直接删除,基于 taint 只是打上标记,然后通过上面的 tiantManager 剔除。和 pod eviction 不同,taint eviction 是通过限制加 taint 的速率控制 raltelimit 的。
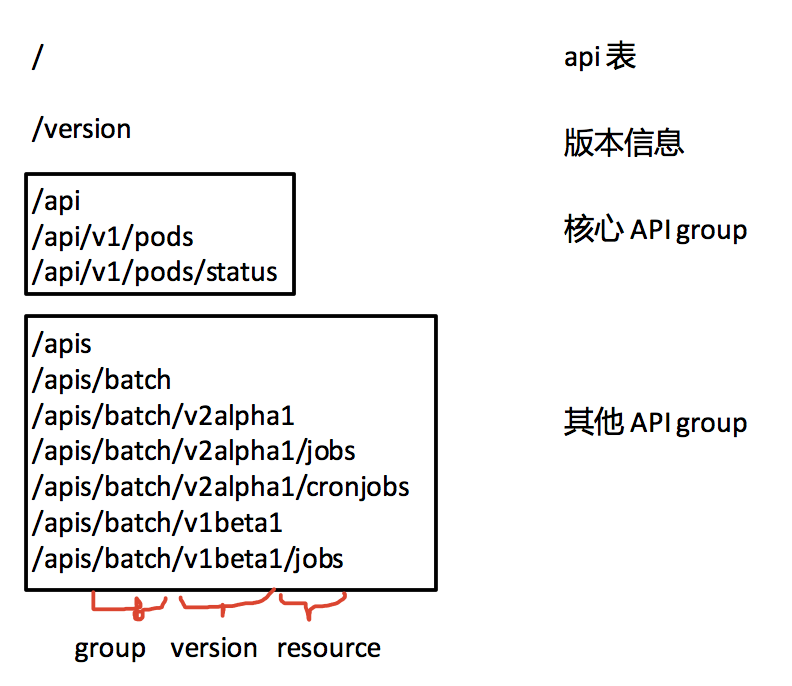
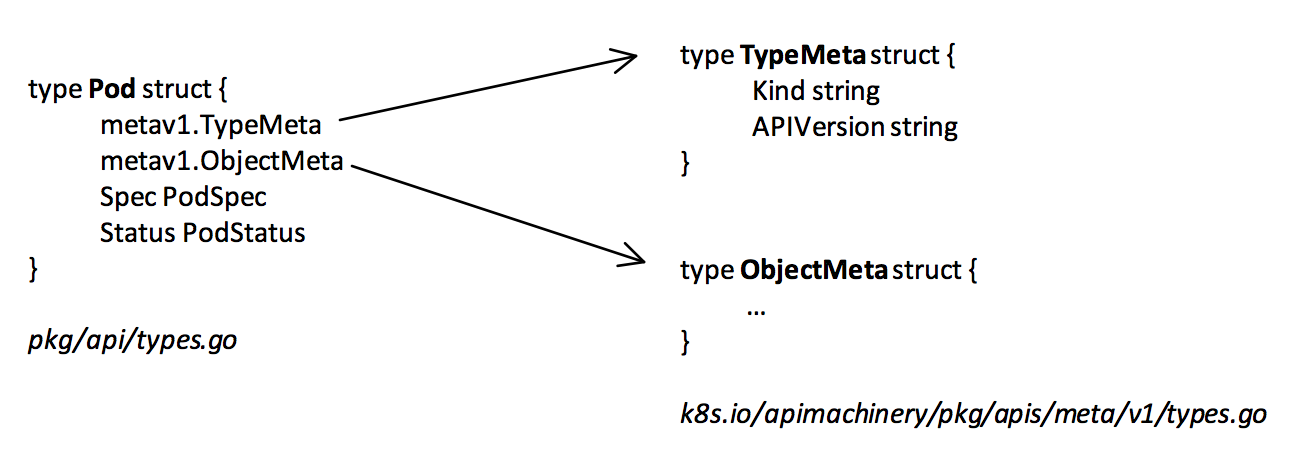
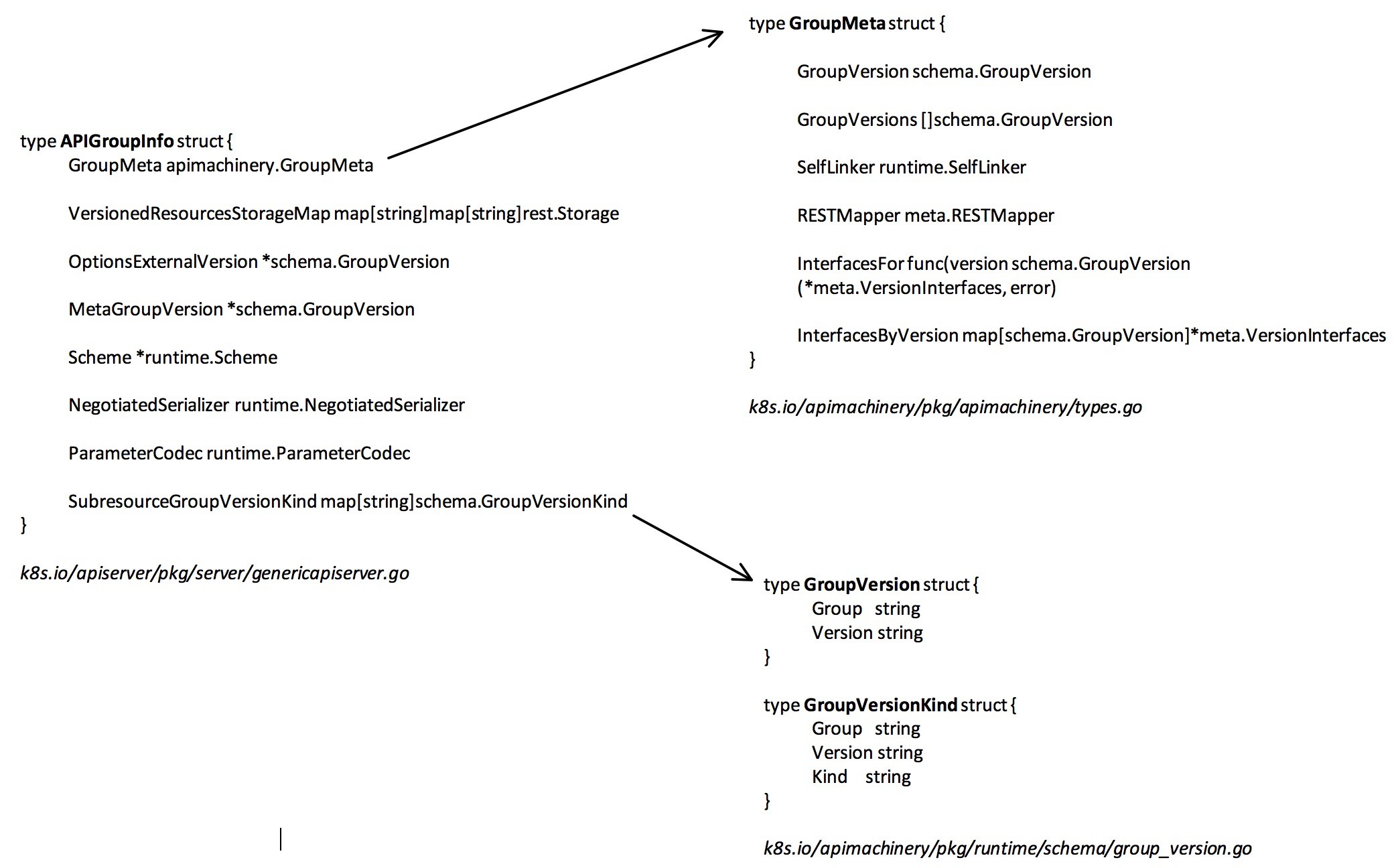
路径上整体分成 group, version, resource, 作为核心 API group 的 core(包括 pod, node 之类的 resource),不带 group,直接接在 /api/ 后面,其他的 api group 则接在 /apis 后面。以 pod 为例,pod 对应的数据类型如下,这个数据结构和 POST 请求中的结构的参数是一致的。
如果是 job 的话则是在,pkg/apis/batch/v2alpha1/types.go,和 API 路径是对应的。例子当中 kubectl 加上 level 大于 8 的 log 就会打印请求和相应的 body,可以看到 request body 和上面的数据结构是一致的。这个请求会发送到 apiserver 进行处理并且返回存储之后的 pod。
重要结构体
Config
父结构,主要的配置内容,其中有一个结构 RESTOptionsGetter genericregistry.RESTOptionsGetter 是和 API 初始化相关的,这个接口的实现是在 k8s.io/apiserver/pkg/server/options/etcd.go 中的 storageFactoryRestOptionsFactory 实现的,对应的实现函数是
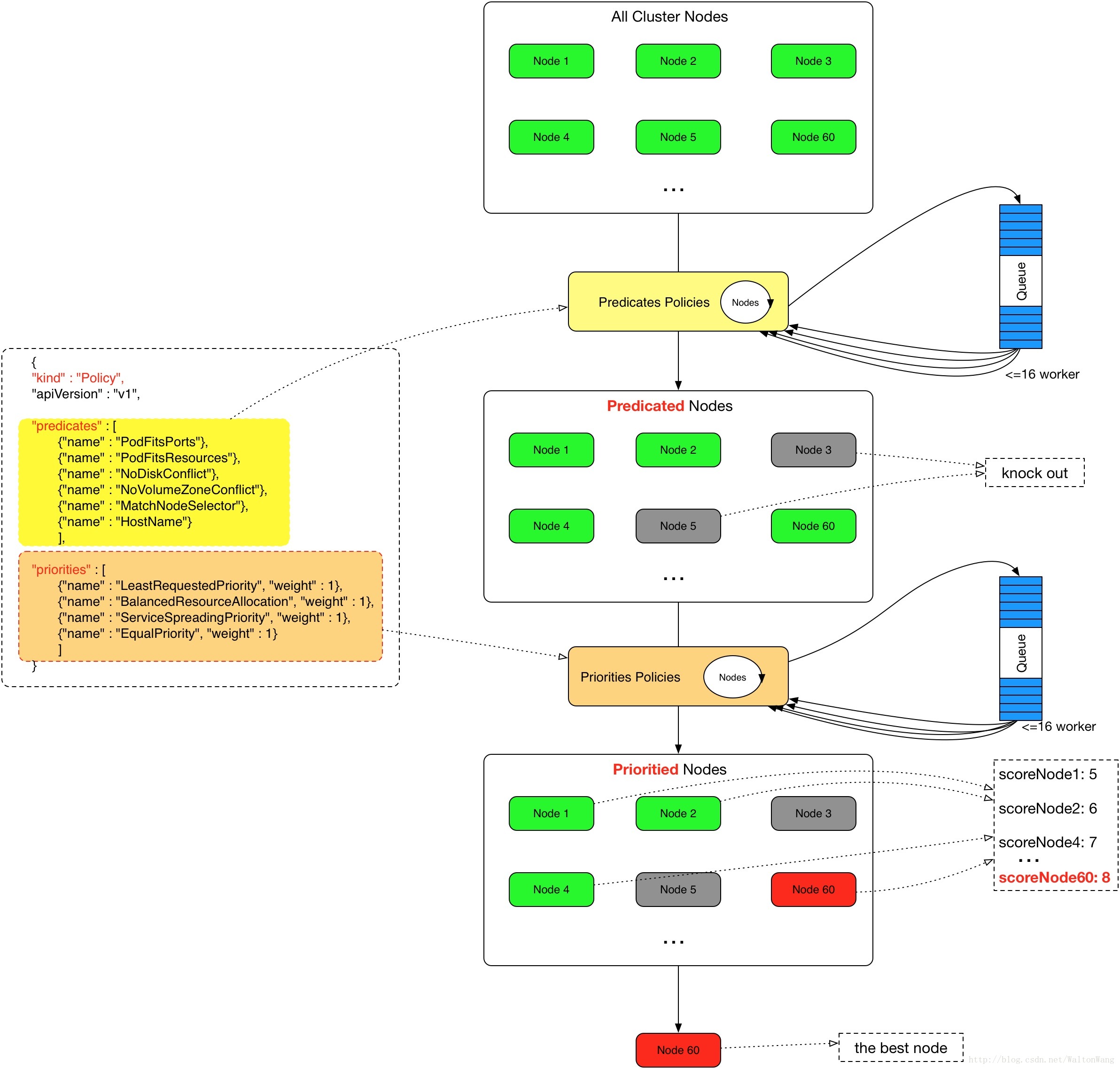
// Registers algorithm providers. By default we use 'DefaultProvider', but user can specify one to be used // by specifying flag. factory.RegisterAlgorithmProvider(factory.DefaultProvider, defaultPredicates(), defaultPriorities()) // Cluster autoscaler friendly scheduling algorithm. factory.RegisterAlgorithmProvider(ClusterAutoscalerProvider, defaultPredicates(), copyAndReplace(defaultPriorities(), "LeastRequestedPriority", "MostRequestedPriority"))
// ScheduleAlgorithm is an interface implemented by things that know how to schedule pods // onto machines. type ScheduleAlgorithm interface { Schedule(*v1.Pod, NodeLister) (selectedMachine string, err error) // Preempt receives scheduling errors for a pod and tries to create room for // the pod by preempting lower priority pods if possible. // It returns the node where preemption happened, a list of preempted pods, and error if any. Preempt(*v1.Pod, NodeLister, error) (selectedNode *v1.Node, preemptedPods []*v1.Pod, err error) // Predicates() returns a pointer to a map of predicate functions. This is // exposed for testing. Predicates() map[string]FitPredicate // Prioritizers returns a slice of priority config. This is exposed for // testing. Prioritizers() []PriorityConfig }
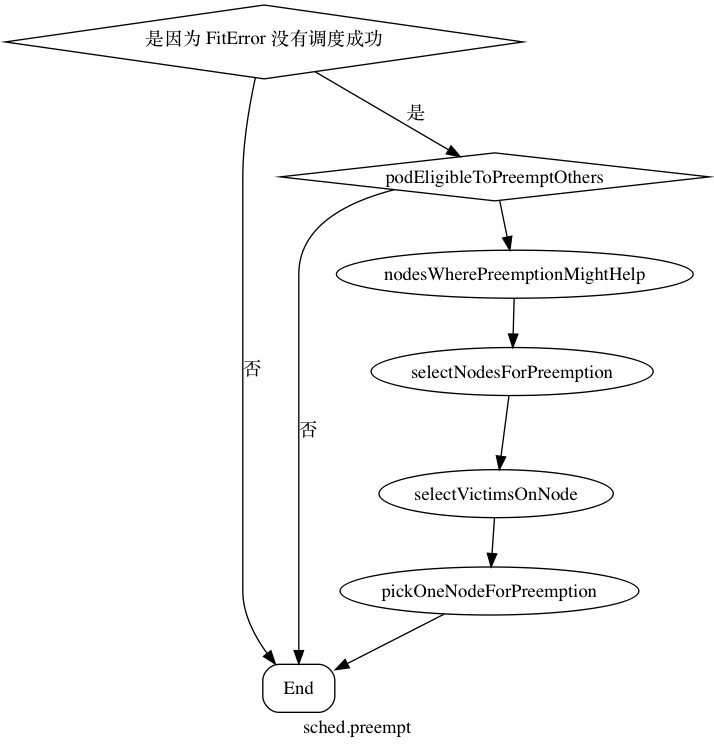
抢占过程是在 pod 没有找到合适的节点情况下,如果能在踢出一个 pod 获得调度机会的情况下进行抢占。抢占算是一个比较新的特性,在 1.8 里面都是默认关掉的,要打开的话需要指定kube-scheduler 的 --feature-gates=PodPriority=true 还有 apiserver 的 --runtime-config=scheduling.k8s.io/v1alpha1=true。可以通过添加 PriorityClass 把 pod 分权重,现在这个特性算是给 pod 也加上的权重。
1 2 3 4 5 6 7 8
apiVersion:v1 kind:PriorityClass metadata: name:high-priority value:1000000 globalDefault:false description:"This priority class should be used for XYZ service pods only."
然后可以在spec当中指定 priorityClassName: high-priority,这样这么大的权重,这个 pod 就很难被抢占了,具体流程如下图。
podEligibleToPreemptOthers 主要判断如果 目标 pod 被标记为(通过 pod 的 annotation 标记)已经要抢占其他 pod,并且有一个优先级小于 目标 pod 的 pod 即将被删除 (p.DeletionTimestamp != nil ),就直接退出,因为这个时候这个被删除的 pod 其实在为目标 pod 腾出空间了,在下次调度的时候就会获得调度机会。nodesWherePreemptionMightHelp,类似于 schedule 的时候的 predicate 阶段,只不过多了一步是通过尝试移除 pod 跑一遍 predicates 看看这个节点能不能被通过。 selectNodesForPreemption 则和 priority 的阶段类似,把删除 pod 之后的可以通过的节点进行排序选出一个排名最高的节点。再通过 selectVictimsOnNode 把节点上的 pod 按照节点的 priority 排序选出“受害者”,越高越难被抢占。可以在 spec 里面设置这个值,选出了节点上的受害者以后,通过pickOneNodeForPreemption,主要的依据是拥有最低的最高 pod 权重的节点先被选出来,比如 node1 上 pod 的最高权重是 10,node2 上 pod 的最高权重是 8,那么 node2 被选中,如果有平局的话,最少的“受害者”先选,如果还平局,随机选一个。最后得到一个要被抢占的节点。
/* rcu_read_lock needs to be hold by caller from readside */ staticstruct key_vector *fib_find_node(struct trie *t, struct key_vector **tp, u32 key) { structkey_vector *pn, *n = t->kv; unsignedlong index = 0;
do { pn = n; n = get_child_rcu(n, index);
if (!n) break;
index = get_cindex(key, n);
/* This bit of code is a bit tricky but it combines multiple * checks into a single check. The prefix consists of the * prefix plus zeros for the bits in the cindex. The index * is the difference between the key and this value. From * this we can actually derive several pieces of data. * if (index >= (1ul << bits)) * we have a mismatch in skip bits and failed * else * we know the value is cindex * * This check is safe even if bits == KEYLENGTH due to the * fact that we can only allocate a node with 32 bits if a * long is greater than 32 bits. */ if (index >= (1ul << n->bits)) { n = NULL; break; }
/* keep searching until we find a perfect match leaf or NULL */ } while (IS_TNODE(n));
/* retrieve child from parent node */ n = get_child(tp, get_index(key, tp));
如果有子节点,就要创建一个新的 tnode,再把这个 key 给插入。
1 2 3 4 5 6 7 8
/* Case 2: n is a LEAF or a TNODE and the key doesn't match. * * Add a new tnode here * first tnode need some special handling * leaves us in position for handling as case 3 */ if (n) { structkey_vector *tn;
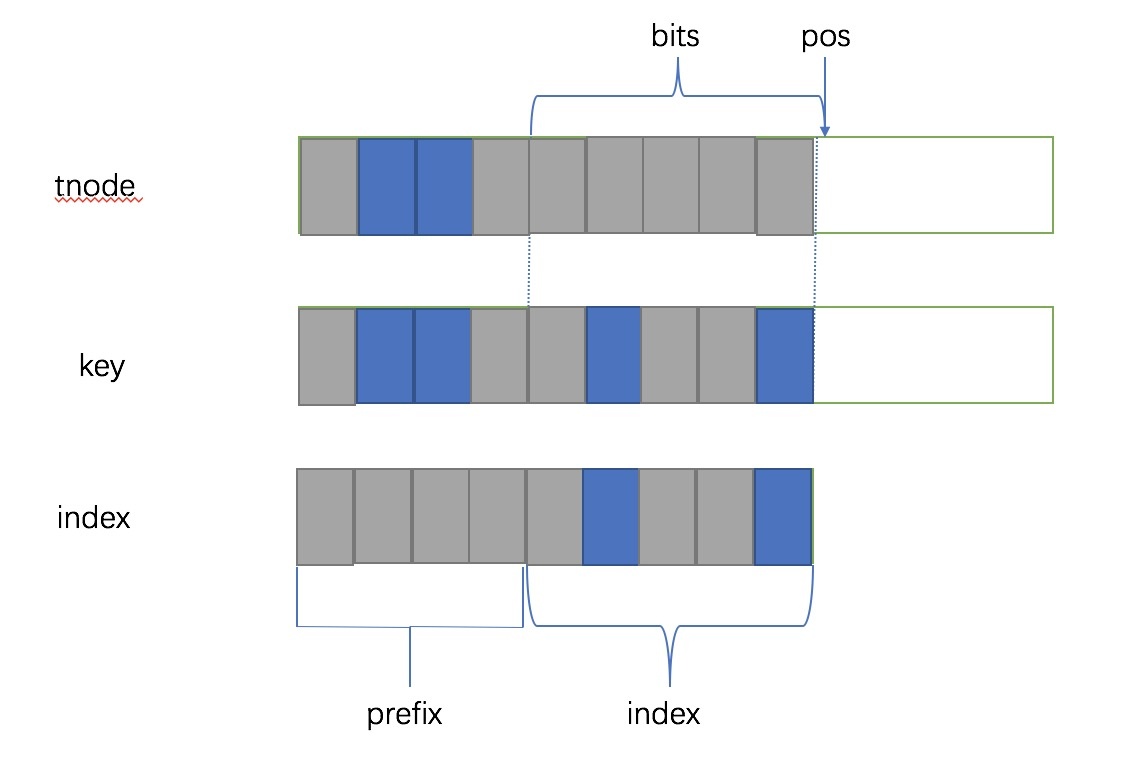
__fls find last set bit,就是找到 pos,然后扩展出有两个选择(2 的 1 次方)的 tnode。
/* track the tnode via the pointer from the parent instead of * doing it ourselves. This way we can let RCU fully do its * thing without us interfering */ BUG_ON(tn != get_child(tp, cindex));
/* Double as long as the resulting node has a number of * nonempty nodes that are above the threshold. */
should_inflate 决定要不要压缩的依据是根据动态压缩算法来的(引用4),直观的来说就是高度超过了一个动态计算的阈值,并且还没压缩超过十次就会继续压缩。这个动态阈值的算法是用非空子节点的数目如果超过压缩之后子节点数目的一半就值得压缩。而 inflate 做的事情就把层级压缩一层,也就是把 children 的 children 按照 bits 的匹配放到 parent 的 new_children 当中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
while (should_inflate(tp, tn) && max_work) { tp = inflate(t, tn); if (!tp) { #ifdef CONFIG_IP_FIB_TRIE_STATS this_cpu_inc(stats->resize_node_skipped); #endif break; }
max_work--; tn = get_child(tp, cindex); }
/* update parent in case inflate failed */ tp = node_parent(tn);
/* Return if at least one inflate is run */ if (max_work != MAX_WORK) return tp;
到这里说明一次调整都没有发生,说明节点很稀疏,也就是把节点分开。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
/* Halve as long as the number of empty children in this * node is above threshold. */ while (should_halve(tp, tn) && max_work) { tp = halve(t, tn); if (!tp) { #ifdef CONFIG_IP_FIB_TRIE_STATS this_cpu_inc(stats->resize_node_skipped); #endif break; }
max_work--; tn = get_child(tp, cindex); }
只有一个孩子,可以进行 path compress,没必要再多一个中间节点。
1 2 3 4 5 6 7
/* Only one child remains */ if (should_collapse(tn)) return collapse(t, tn);
/* update parent in case halve failed */ return node_parent(tn); }
/* Compare new lladdr with cached one */ if (!dev->addr_len) { /* First case: device needs no address. */ lladdr = neigh->ha; } elseif (lladdr) { /* The second case: if something is already cached and a new address is proposed: - compare new & old - if they are different, check override flag */ if ((old & NUD_VALID) && !memcmp(lladdr, neigh->ha, dev->addr_len)) lladdr = neigh->ha; } else { /* No address is supplied; if we know something, use it, otherwise discard the request. */ err = -EINVAL; if (!(old & NUD_VALID)) goto out; lladdr = neigh->ha; }
如果NUD_CONNECTED 更新 confirm 的时间,更新『更新』的时间。
1 2 3
if (new & NUD_CONNECTED) neigh->confirmed = jiffies; neigh->updated = jiffies;
/* If entry was valid and address is not changed, do not change entry state, if new one is STALE. */ err = 0; update_isrouter = flags & NEIGH_UPDATE_F_OVERRIDE_ISROUTER; if (old & NUD_VALID) { if (lladdr != neigh->ha && !(flags & NEIGH_UPDATE_F_OVERRIDE)) { update_isrouter = 0; if ((flags & NEIGH_UPDATE_F_WEAK_OVERRIDE) && (old & NUD_CONNECTED)) { lladdr = neigh->ha; new = NUD_STALE; } else goto out; } else { if (lladdr == neigh->ha && new == NUD_STALE && !(flags & NEIGH_UPDATE_F_ADMIN)) new = old; } }
如果是更新操作,删除老的 timer,如果需要 timer,更新新的 timer,并且设置新状态。
1 2 3 4 5 6 7 8 9 10 11 12
if (new != old) { neigh_del_timer(neigh); if (new & NUD_PROBE) atomic_set(&neigh->probes, 0); if (new & NUD_IN_TIMER) neigh_add_timer(neigh, (jiffies + ((new & NUD_REACHABLE) ? neigh->parms->reachable_time : 0))); neigh->nud_state = new; notify = 1; }
更新 neigh->ha,如果 lladdr 和 neigh->ha 不同的话。
1 2 3 4 5 6 7 8 9 10 11 12
if (lladdr != neigh->ha) { write_seqlock(&neigh->ha_lock); memcpy(&neigh->ha, lladdr, dev->addr_len); write_sequnlock(&neigh->ha_lock); neigh_update_hhs(neigh); if (!(new & NUD_CONNECTED)) neigh->confirmed = jiffies - (NEIGH_VAR(neigh->parms, BASE_REACHABLE_TIME) << 1); notify = 1; } if (new == old) goto out;
根据状态调用 connect 和 suspect
1 2 3 4
if (new & NUD_CONNECTED) neigh_connect(neigh); else neigh_suspect(neigh);
/* Why not just use 'neigh' as-is? The problem is that * things such as shaper, eql, and sch_teql can end up * using alternative, different, neigh objects to output * the packet in the output path. So what we need to do * here is re-lookup the top-level neigh in the path so * we can reinject the packet there. */ n2 = NULL; if (dst) { n2 = dst_neigh_lookup_skb(dst, skb); if (n2) n1 = n2; } n1->output(n1, skb); if (n2) neigh_release(n2); rcu_read_unlock();
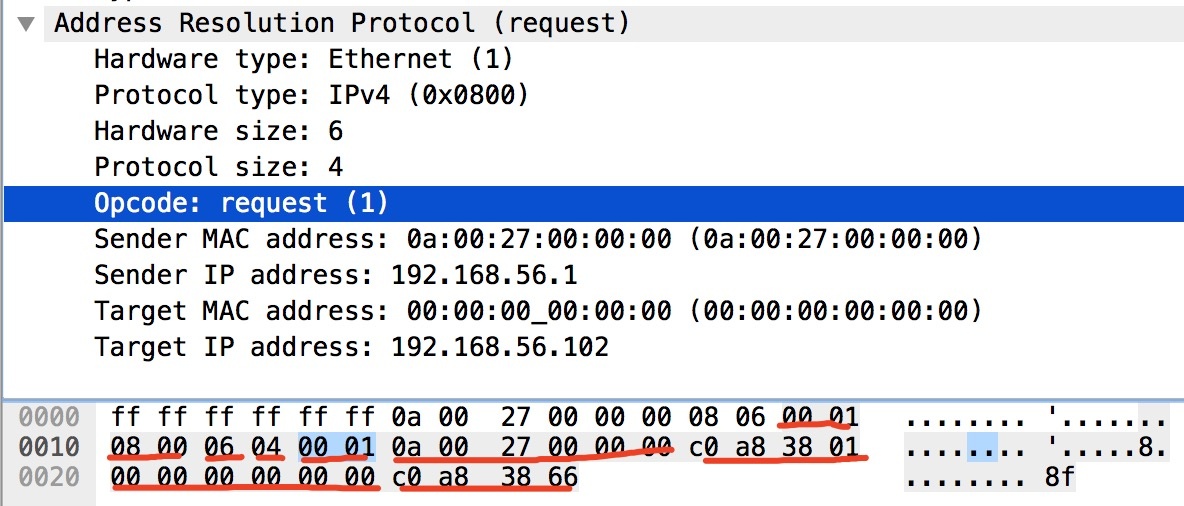
还有就是 VIP,一般的作用是在本地网路中有两台机器,一台作为备机,一台作为主机,当主机 failover 的时候,备机可以继续『冒充』主机的 IP 地址,具体的做法就是主动发送请求,解析的 MAC 和 IP 都和 source 一样,老的 server 肯定不会回答这个 ARP,交换机上已经没有这个端口的缓存,会进行广播,让所有的接收者都会更新自己的缓存。也就是发送了一个一去不复返的请求,让所有的邻居更新了自己的 ARP 缓存,从而替代了老 server 的 IP,这就是 VIP 通过 ARP 实现的 failover。
while (left > 0) { len = left; /* IF: it doesn't fit, use 'mtu' - the data space left */ if (len > mtu) len = mtu; /* IF: we are not sending up to and including the packet end then align the next start on an eight byte boundary */ if (len < left) { len &= ~7; }
/* * Copy a block of the IP datagram. */ if (skb_copy_bits(skb, ptr, skb_transport_header(skb2), len)) BUG(); left -= len;
设置 IP 头的偏移和分片标志。
1 2 3 4 5 6 7 8
/* * Fill in the new header fields. */ iph = ip_hdr(skb2); iph->frag_off = htons((offset >> 3));
if (IPCB(skb)->flags & IPSKB_FRAG_PMTU) iph->frag_off |= htons(IP_DF);
如果是第一个分片就尝试更新 IP options。
1 2 3 4 5 6 7 8
/* ANK: dirty, but effective trick. Upgrade options only if * the segment to be fragmented was THE FIRST (otherwise, * options are already fixed) and make it ONCE * on the initial skb, so that all the following fragments * will inherit fixed options. */ if (offset == 0) ip_options_fragment(skb);
/* * Added AC : If we are fragmenting a fragment that's not the * last fragment then keep MF on each bit */ if (left > 0 || not_last_frag) iph->frag_off |= htons(IP_MF); ptr += len; offset += len;
/* * Put this fragment into the sending queue. */ iph->tot_len = htons(len + hlen);
/* Determine the position of this fragment. */ end = offset + skb->len - skb_network_offset(skb) - ihl; err = -EINVAL;
如果是最后一个 fragment,那么不应该超过 q.len,或者已经有了最后一个了,但是 end 和 q.len 不一致,所以有一些 corruption。如果检查没问题,就更新q.flasg 标记为最后一个和把 end 赋值给q.len。
1 2 3 4 5 6 7 8 9 10 11
/* Is this the final fragment? */ if ((flags & IP_MF) == 0) { /* If we already have some bits beyond end * or have different end, the segment is corrupted. */ if (end < qp->q.len || ((qp->q.flags & INET_FRAG_LAST_IN) && end != qp->q.len)) goto err; qp->q.flags |= INET_FRAG_LAST_IN; qp->q.len = end;
如果不是最后一个,长度要与 8 对齐,然后更新 q.len。
1 2 3 4 5 6 7 8 9 10 11 12 13
} else { if (end&7) { end &= ~7; if (skb->ip_summed != CHECKSUM_UNNECESSARY) skb->ip_summed = CHECKSUM_NONE; } if (end > qp->q.len) { /* Some bits beyond end -> corruption. */ if (qp->q.flags & INET_FRAG_LAST_IN) goto err; qp->q.len = end; }
err = -ENOMEM; if (!pskb_pull(skb, skb_network_offset(skb) + ihl)) goto err;
err = pskb_trim_rcsum(skb, end - offset); if (err) goto err;
/* Find out which fragments are in front and at the back of us * in the chain of fragments so far. We must know where to put * this fragment, right? */ prev = qp->q.fragments_tail; if (!prev || FRAG_CB(prev)->offset < offset) { next = NULL; goto found; } prev = NULL; for (next = qp->q.fragments; next != NULL; next = next->next) { if (FRAG_CB(next)->offset >= offset) break; /* bingo! */ prev = next; }
如果和前面的分组有重叠,就把重叠的部分去掉,CHECKSUM_NONE 可以使当前的校验和失效。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
if (prev) { int i = (FRAG_CB(prev)->offset + prev->len) - offset;
if (i > 0) { offset += i; err = -EINVAL; if (end <= offset) goto err; err = -ENOMEM; if (!pskb_pull(skb, i)) goto err; if (skb->ip_summed != CHECKSUM_UNNECESSARY) skb->ip_summed = CHECKSUM_NONE; } }
然后向后检查有没有重叠,并且把重叠的部分去掉,如果重叠的部分比 next 本身还要大,直接把 next 删掉。
while (next && FRAG_CB(next)->offset < end) { int i = end - FRAG_CB(next)->offset; /* overlap is 'i' bytes */
if (i < next->len) { /* Eat head of the next overlapped fragment * and leave the loop. The next ones cannot overlap. */ if (!pskb_pull(next, i)) goto err; FRAG_CB(next)->offset += i; qp->q.meat -= i; if (next->ip_summed != CHECKSUM_UNNECESSARY) next->ip_summed = CHECKSUM_NONE; break; } else { struct sk_buff *free_it = next;
/* Old fragment is completely overridden with * new one drop it. */ next = next->next;
if (prev) prev->next = next; else qp->q.fragments = next;
/* When the interface is in promisc. mode, drop all the crap * that it receives, do not try to analyse it. */ // 如果 L2 地址不是本机地址 pkt_type 就会被设置成 PACKET_OHTERHOST // 然后进行丢包 if (skb->pkt_type == PACKET_OTHERHOST) goto drop;
/* * RFC1122: 3.2.1.2 MUST silently discard any IP frame that fails the checksum. * * Is the datagram acceptable? * * 1. Length at least the size of an ip header * 2. Version of 4 * 3. Checksums correctly. [Speed optimisation for later, skip loopback checksums] * 4. Doesn't have a bogus length */ // ip 头部长度至少 20 个字节 if (iph->ihl < 5 || iph->version != 4) goto inhdr_error;
/* Our transport medium may have padded the buffer out. Now we know it * is IP we can trim to the true length of the frame. * Note this now means skb->len holds ntohs(iph->tot_len). */ if (pskb_trim_rcsum(skb, len)) { __IP_INC_STATS(net, IPSTATS_MIB_INDISCARDS); goto drop; }
/* if ingress device is enslaved to an L3 master device pass the * skb to its handler for processing */ skb = l3mdev_ip_rcv(skb); if (!skb) return NET_RX_SUCCESS;
如果设置了 ip_early_demux 并且不是分片的 IP 包,就会提前调用 TCP 的 early_demux 提前解复用这个包。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
if (net->ipv4.sysctl_ip_early_demux && !skb_dst(skb) && !skb->sk && !ip_is_fragment(iph)) { conststructnet_protocol *ipprot; int protocol = iph->protocol;
ipprot = rcu_dereference(inet_protos[protocol]); if (ipprot && (edemux = READ_ONCE(ipprot->early_demux))) { edemux(skb); /* must reload iph, skb->head might have changed */ iph = ip_hdr(skb); } }
/* * Initialise the virtual path cache for the packet. It describes * how the packet travels inside Linux networking. */ if (!skb_valid_dst(skb)) { int err = ip_route_input_noref(skb, iph->daddr, iph->saddr, iph->tos, dev); if (unlikely(err)) { if (err == -EXDEV) __NET_INC_STATS(net, LINUX_MIB_IPRPFILTER); goto drop; } }
if (ip_options_compile(dev_net(dev), opt, skb)) { __IP_INC_STATS(dev_net(dev), IPSTATS_MIB_INHDRERRORS); goto drop; }
in_device 是和 IP 有关的设备信息,如果没有 source route 选项就直接跳过,不然处理 source route 选项。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
if (unlikely(opt->srr)) { structin_device *in_dev = __in_dev_get_rcu(dev);
if (in_dev) { if (!IN_DEV_SOURCE_ROUTE(in_dev)) { if (IN_DEV_LOG_MARTIANS(in_dev)) net_info_ratelimited("source route option %pI4 -> %pI4\n", &iph->saddr, &iph->daddr); goto drop; } }
if (ip_options_rcv_srr(skb)) goto drop; }
source route 是一个多字节选项。此选项中,发送节点会列出后续几跳的 IP 地址(不能超过 IP 报头的最大长度)。如果列表中有某台主机宕机了,则必须重新计算来源地路由,重新发送,而不是使用动态路由。ip_options_rcv_srr 的具体工作就是根据提取出的目的地在本地计算目的地是否可达,如果成功就反回 0, 不然就丢弃。
/* RFC 1122 3.3.6: * * When a host sends a datagram to a link-layer broadcast * address, the IP destination address MUST be a legal IP * broadcast or IP multicast address. * * A host SHOULD silently discard a datagram that is received * via a link-layer broadcast (see Section 2.4) but does not * specify an IP multicast or broadcast destination address. * * This doesn't explicitly say L2 *broadcast*, but broadcast is * in a way a form of multicast and the most common use case for * this is 802.11 protecting against cross-station spoofing (the * so-called "hole-196" attack) so do it for both. */ if (in_dev && IN_DEV_ORCONF(in_dev, DROP_UNICAST_IN_L2_MULTICAST)) goto drop; }
return dst_input(skb);
进入 dst_input 就会交给 skb>dst >input 来处理。
转发会分成两部分处理 ip_forward 和 ip_forward_finish IP 转发分成几个步骤
处理 IP options,可能会要求记录本地 IP 地址和时间戳
基于 IP 头,确保这个 pakcet 可以发出去
减 1 TTL,到达 0 就丢弃
根据 MTU 进行分组
发送至出口设备
期间如果出错了,会通过 ICMP 告知。xfrm4_xxx 是 IPsec 相关的函数。
1 2
if (IPCB(skb)->opt.router_alert && ip_call_ra_chain(skb)) return NET_RX_SUCCESS;
首先是检查 IP 选项当中有没有 Router Alert,如果有的话就交给 ip_ra_chain 中对此感兴趣的 raw socket 来处理,并且就次结束。
在这里检查 TTL 是否耗尽
1 2 3
if (ip_hdr(skb)->ttl <= 1) goto too_many_hops;
如果是严格的源路由,下一条是网关而不是直接连接的路由就丢包。
rt_uses_gateway 代表两种意思
1 的时候表示网关
0 的时候表示直接路由
1 2 3
if (opt->is_strictroute && rt->rt_uses_gateway) goto sr_failed;
如果超出 MTU 进行丢包
1 2 3 4 5 6 7 8 9
IPCB(skb)->flags |= IPSKB_FORWARDED; mtu = ip_dst_mtu_maybe_forward(&rt->dst, true); if (ip_exceeds_mtu(skb, mtu)) { IP_INC_STATS(net, IPSTATS_MIB_FRAGFAILS); icmp_send(skb, ICMP_DEST_UNREACH, ICMP_FRAG_NEEDED, htonl(mtu)); goto drop; }
declone 这个 skb 并且确保预留 L2 的空间,然后减少 TTL。
1 2 3 4 5 6 7 8
/* We are about to mangle packet. Copy it! */ if (skb_cow(skb, LL_RESERVED_SPACE(rt->dst.dev)+rt->dst.header_len)) goto drop; iph = ip_hdr(skb);
/* Decrease ttl after skb cow done */ ip_decrease_ttl(iph);
如果被标记为 IPSKB_DOREDIRECT 发送 redirect ICMP,接着设置优先级。
1 2 3 4 5 6 7 8 9 10
/* * We now generate an ICMP HOST REDIRECT giving the route * we calculated. */ if (IPCB(skb)->flags & IPSKB_DOREDIRECT && !opt->srr && !skb_sec_path(skb)) ip_rt_send_redirect(skb);
/* Use correct destination address if we have options. */ daddr = inet->inet_daddr; if (inet_opt && inet_opt->opt.srr) daddr = inet_opt->opt.faddr;
/* If this fails, retransmit mechanism of transport layer will * keep trying until route appears or the connection times * itself out. */ rt = ip_route_output_ports(net, fl4, sk, daddr, inet->inet_saddr, inet->inet_dport, inet->inet_sport, sk->sk_protocol, RT_CONN_FLAGS(sk), sk->sk_bound_dev_if); if (IS_ERR(rt)) goto no_route; sk_setup_caps(sk, &rt->dst); } skb_dst_set_noref(skb, &rt->dst);
接下来就需要构建 IP 头了,先调用空出需要的 IP 头部空间,并且重置我的大脑。
1 2
/* OK, we know where to send it, allocate and build IP header. */ skb_push(skb, sizeof(struct iphdr) + (inet_opt ? inet_opt->opt.optlen : 0));
/* * transhdrlen > 0 means that this is the first fragment and we wish * it won't be fragmented in the future. */ if (transhdrlen && length + fragheaderlen <= mtu && rt->dst.dev->features & (NETIF_F_HW_CSUM | NETIF_F_IP_CSUM) && !(flags & MSG_MORE) && !exthdrlen) csummode = CHECKSUM_PARTIAL;
下面如果满足下面条件就进入 UDP Fragment Offload 例程。是硬件网卡提供的一种特性,由内核和驱动配合完成相关功能。其目的是由网卡硬件来完成本来需要软件进行的分段(分片)操作用于提升效率和性能。如大家所知,在网络上传输的数据包不能大于 mtu,当用户发送大于 mtu 的数据报文时,通常会在传输层(或者在特殊情况下在 IP 层分片,比如 ip 转发或 ipsec 时)就会按 mtu 大小进行分段,防止发送出去的报文大于 mtu,为提升该操作的性能,新的网卡硬件基本都实现了 UFO 功能,可以使分段(或分片)操作在网卡硬件完成,此时用户态就可以发送长度大于 mtu 的包,而且不必在协议栈中进行分段(或分片)。如果硬件支持,是 UDP 协议,并且是大于 mtu 的可以直接用这个函数。
/* * If remaining data exceeds the mtu, * we know we need more fragment(s). */ datalen = length + fraggap; if (datalen > mtu - fragheaderlen) datalen = maxfraglen - fragheaderlen; fraglen = datalen + fragheaderlen;
/* The last fragment gets additional space at tail. * Note, with MSG_MORE we overallocate on fragments, * because we have no idea what fragment will be * the last. */ if (datalen == length + fraggap) alloclen += rt->dst.trailer_len;
/* * Fill in the control structures */ skb->ip_summed = csummode; skb->csum = 0; skb_reserve(skb, hh_len);
设置 tx_flags 和 tskey
1 2 3 4 5 6
/* only the initial fragment is time stamped */ skb_shinfo(skb)->tx_flags = cork->tx_flags; cork->tx_flags = 0; skb_shinfo(skb)->tskey = tskey; tskey = 0;
保留数据空间,并且把指针移动到头部后面,指向负载的部分。
1 2 3 4 5 6 7
* Find where to start putting bytes. */ data = skb_put(skb, fraglen + exthdrlen); skb_set_network_header(skb, exthdrlen); skb->transport_header = (skb->network_header + fragheaderlen); data += fragheaderlen + exthdrlen;
这部分就是把上个 skb 的 fraggap 移到当前这个,并且重新获取 checksum。
1 2 3 4 5 6 7 8 9 10
if (fraggap) { skb->csum = skb_copy_and_csum_bits( skb_prev, maxfraglen, data + transhdrlen, fraggap, 0); skb_prev->csum = csum_sub(skb_prev->csum, skb->csum); data += fraggap; pskb_trim_unique(skb_prev, maxfraglen); }
接下来调用 getfrag 拷贝数据,加入到队尾。
getfrag 对应的 4 个 routine 分别是
ICMP icmp_glue_bits
UDP. ip_generic_getfrag
RAW iP ip_generic_getfrag
TCP. Ip_reply_glue_bits
getfrag 的功能就是从 from 拷贝到 to ,因为可能是用户态的数据,所以包含了地址转换的功能并且在比好的时候重新计算校验和。
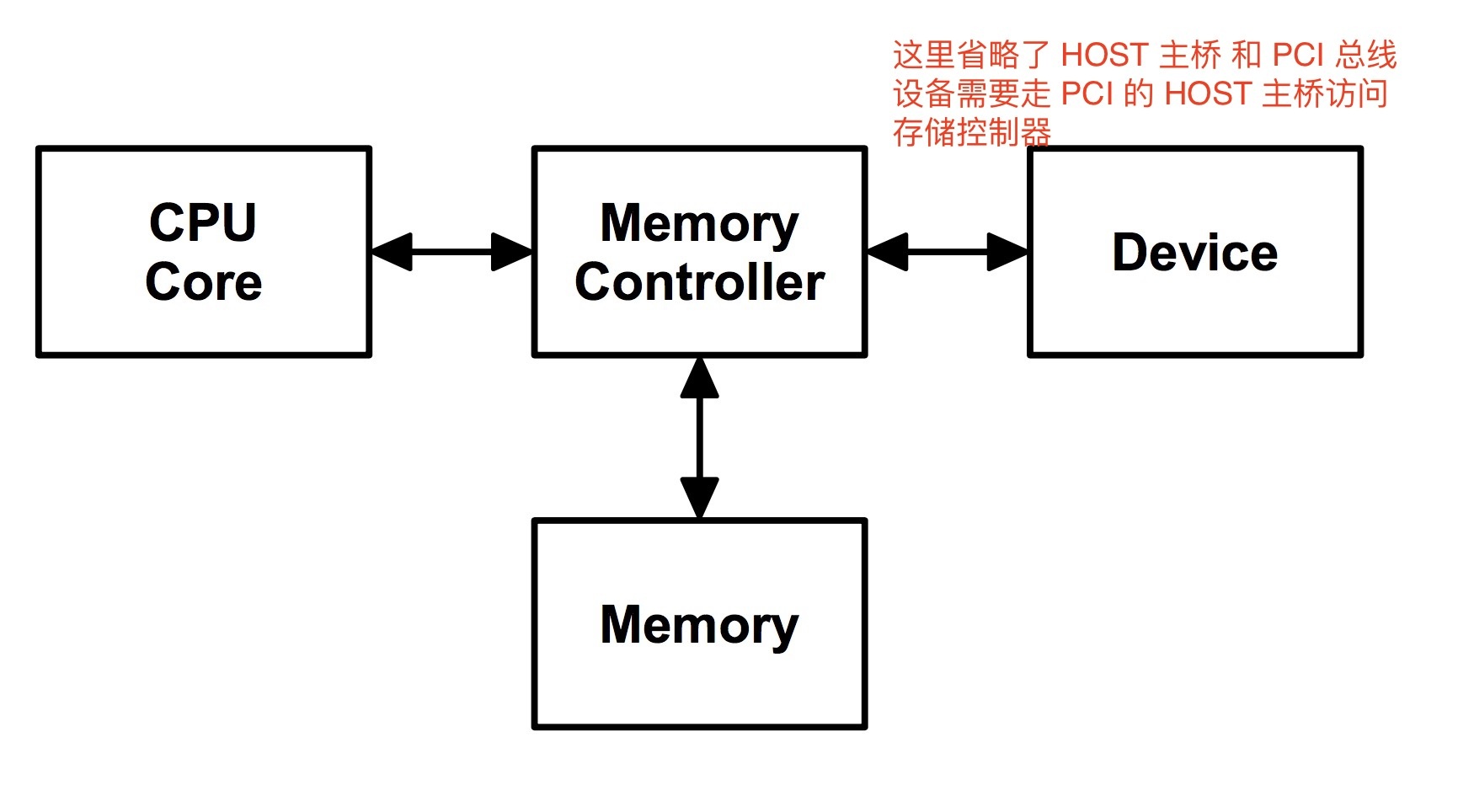
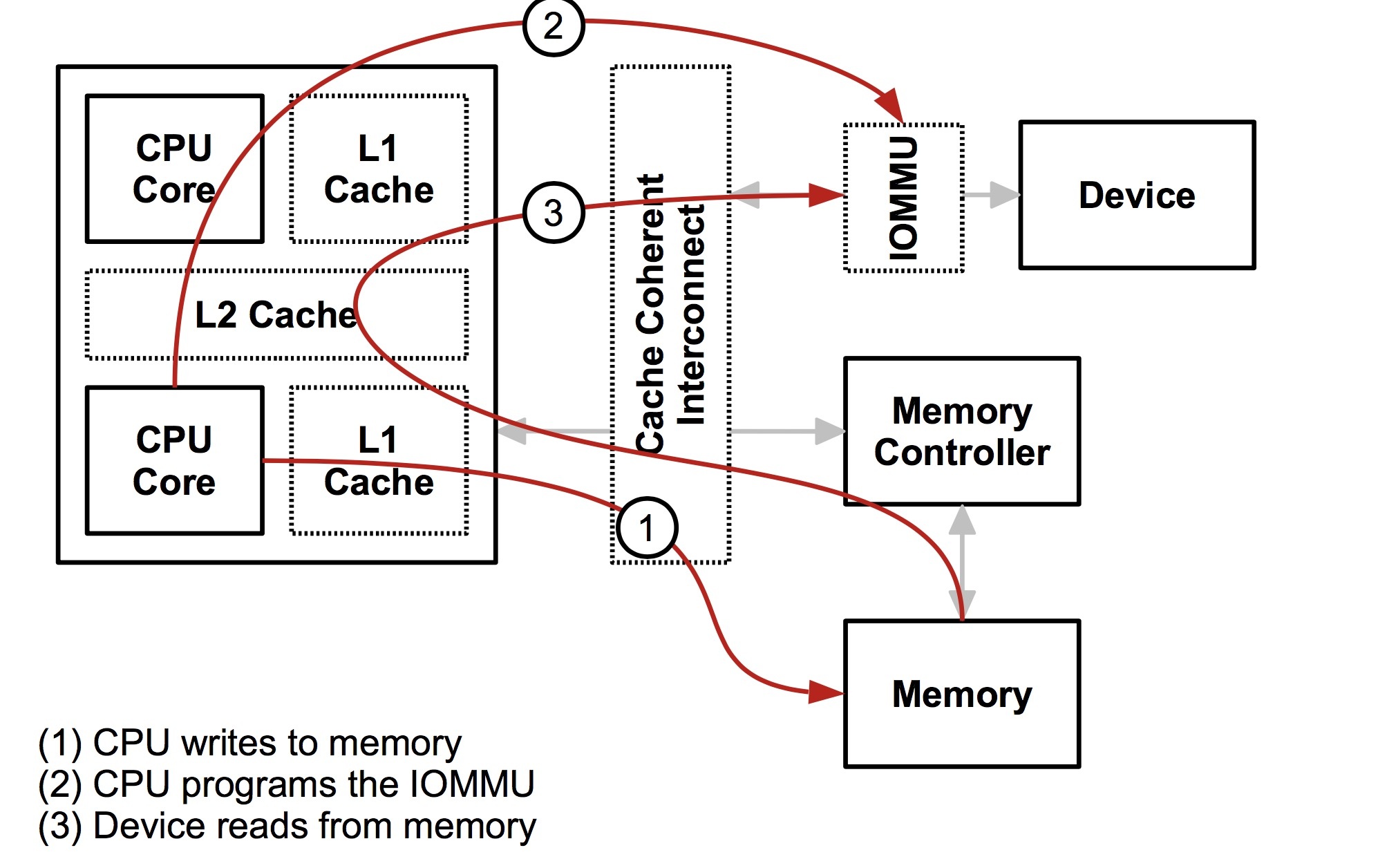
这是一个比较简单的体系结构图,设备 和 CPU 通过存储控制器访问存储器。一个简单的 case 是 CPU 向存储器写数据,然后设备从存储器读数据。这么快来一切都很正常。但是实际上 CPU 是有一层缓存的,例如下面这样的。
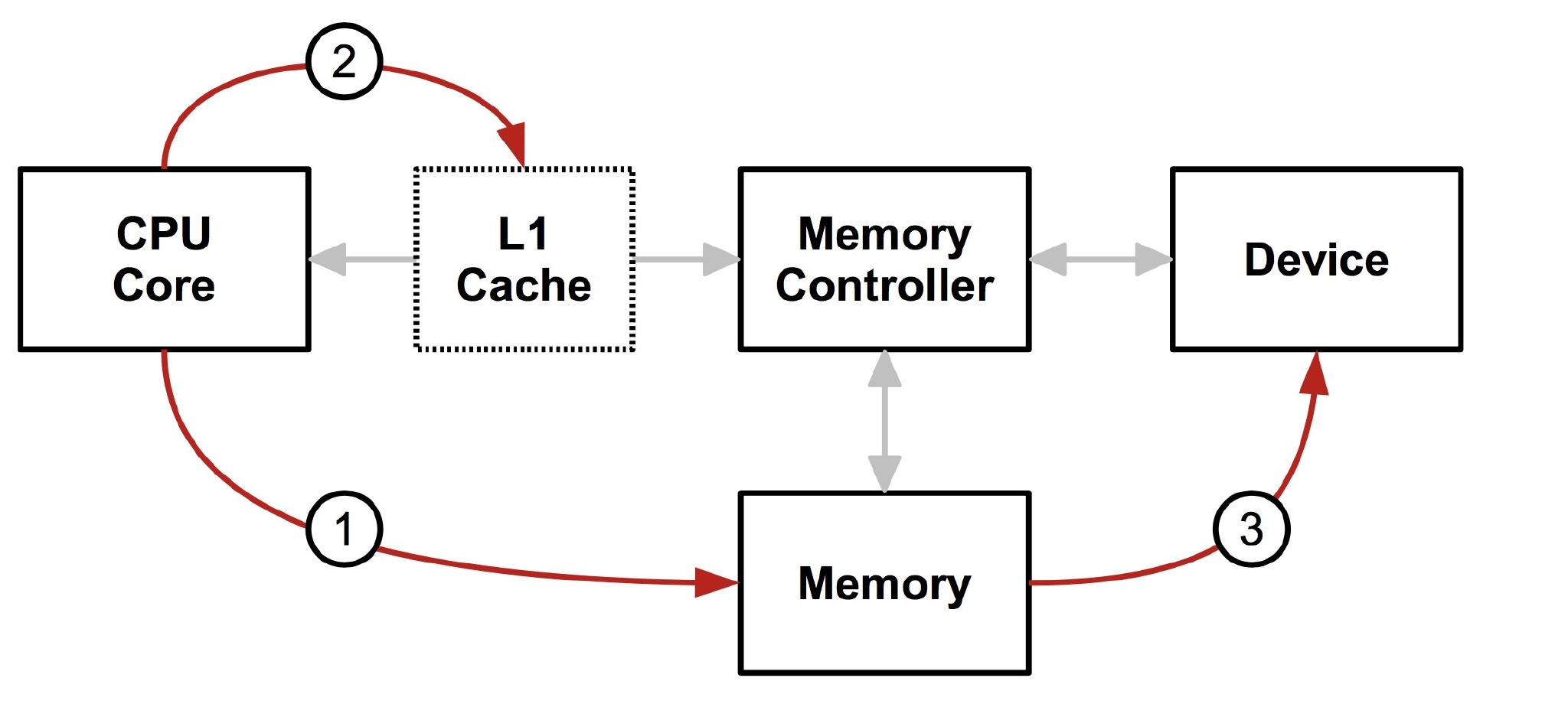
CPU 想内存写数据,但是先要清空到不一致的缓存,然后设备再去读数据,不然设备读到的数据和 CPU 实际的数据会不一致(因为缓存里的数据可能和存储器的不一致),而且实际上缓存也不只是一层,所以需要一个中间层来保证 从 CPU 的角度和从设备的角度内存都是一致的,所以就有了下面这个结构。
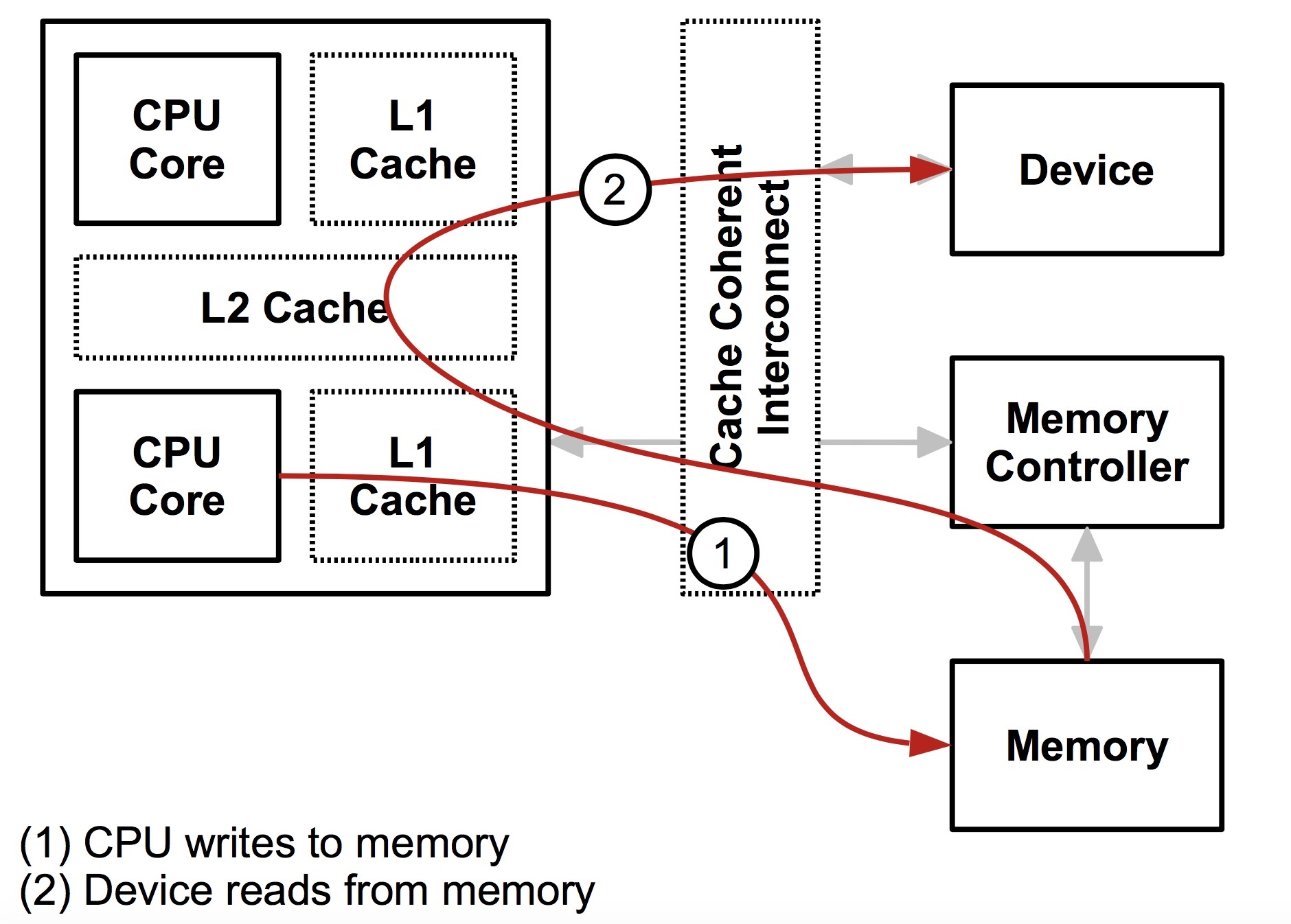
CPU 和 设备都会走缓存验证一遍以后,再落到存储器上,这样带上缓存以后大家的一致性都是一样的了。所以从设备的角度,设备也拥有了缓存,实际上这个和 IOMMU 关系不是很大,接下来设备其实也可以和 CPU 一样有一层 MMU,也就是地址到存储器物理地址的转换。注意,这里我用了地址,因为对 CPU 来说是虚拟地址,但是对设备来说是一个总线域的地址。这里要明确区分一下,一个是总线地址,是从设备的角度来看的,一个是 CPU 的虚拟地址,这是从 CPU 角度来看的,两个是不同的东西。将总线域地址转换成存储器物理地址的设备就叫 IOMMU。
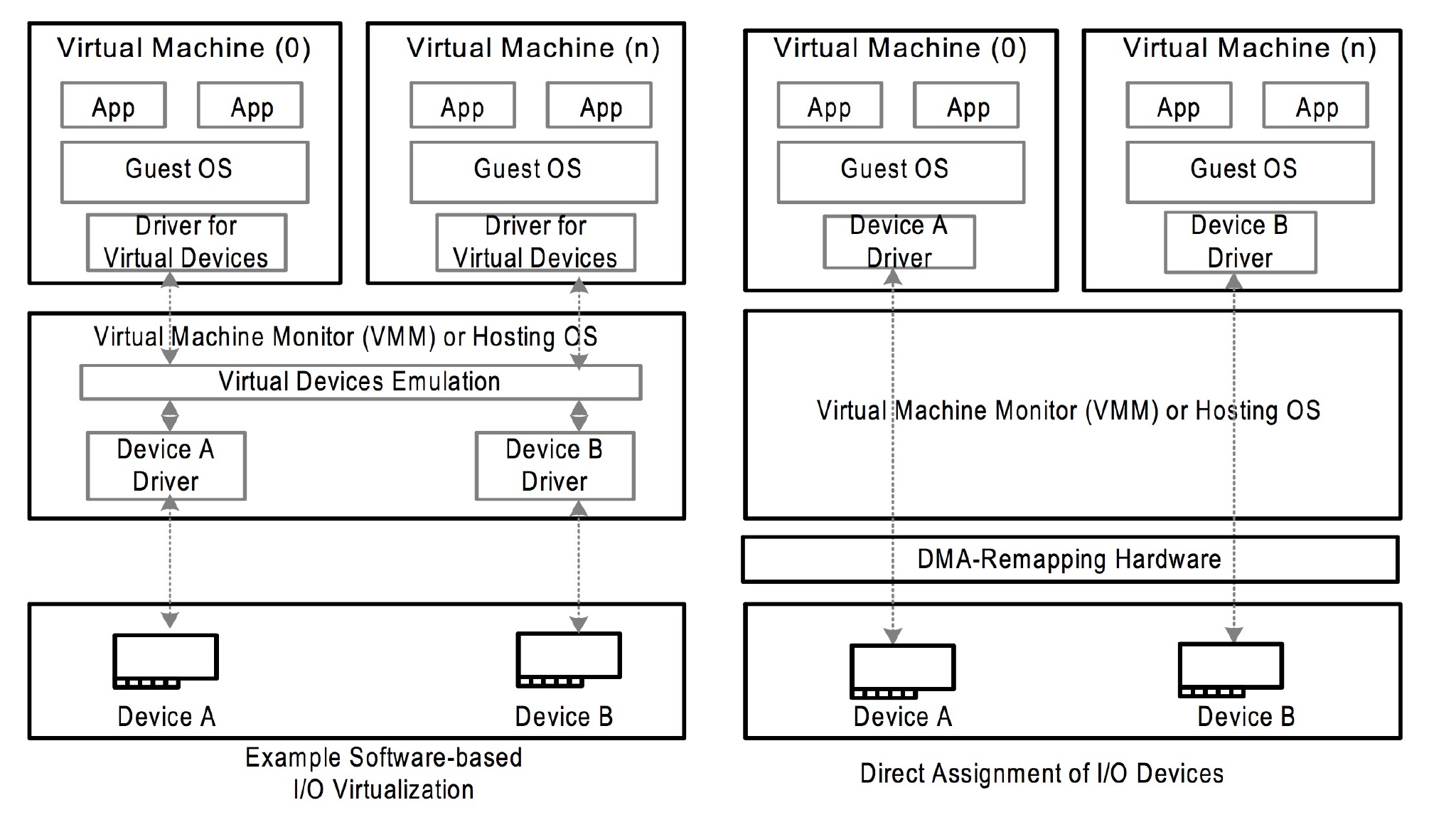
通过打开/dev/vfio/vfio就能创建一个 VFIO 的 container,然后再打开/dev/vfio/$GROUP用VFIO_GROUP_SET_CONTAINER ioctl 把文件描述传进去,就把 group 加进去了,如果支持多个 group 共享页表等结构,还可以把相应的 group 也加进去。(再强调一遍这个页表是总线地址到存储器物理地址,IOMMU 管理的那个页表)。
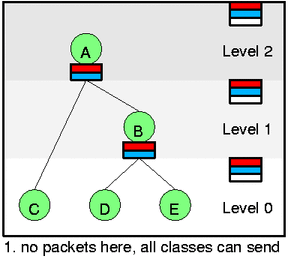
每个 class 有个 slot 包含不同的 prio 级别,指向 yellow 的子节点,然后每个层级包含一个 slot 也有不同的 prio 级别指向这一层中 green 的节点,上图展示了的是有两个 prio 的 slot,右边的 self slot 有个白色的是用于 yellow red 的 wait list。
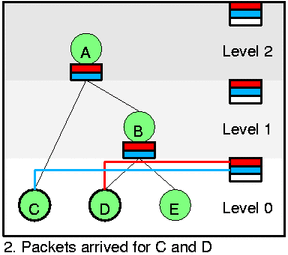
假设当前如图 1 的状态,所有节点都是绿的没有 packet 到来,现在有有两个包到达 C 和 D,然后激活它们,并且它们现在都是绿的,所以 self slot 指向他们,然后因为 D 的优先级更高,所以先把 D 出队。所以你可以发现,出队的顺序很简答,就是按照优先级从 self slot 里面把绿色的包按顺序取出来就可以。
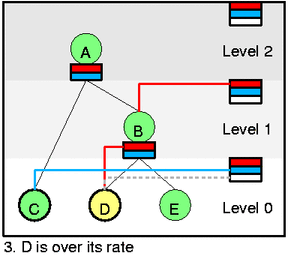
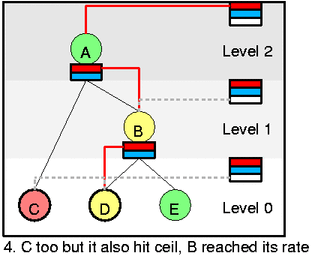
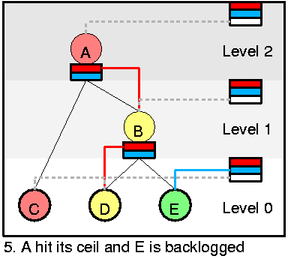
然后我们看一下更复杂的情况,在图 3 中,我们从 D 中出队一个 packet(htb_dequeue),然后htb_charge_class会增加 D 的速率,导致 D 变成 yellow,离开 self slot (通过htb_deactivate_prios和htb_remove_class_from_row),然后添加到 B 的 slot 里面 (htb_activate_prios),并且递归向上添加htb_add_class_to_row,D 会在一段时间后进入 self slot 的白色等待区,然后 D 又会变回绿色。现在如果选择的话,就会从 C 出队,因为虽然 C 的优先级低但是 C 不需要借别人的速率。
在图 4,假设 C 已经完全消耗了速率达到了最大限速,这个时候 D 就会开始工作然后把 B 消耗完,B 被消耗了以后就会去消耗 A,从这里就可以看到一个借取的过程。
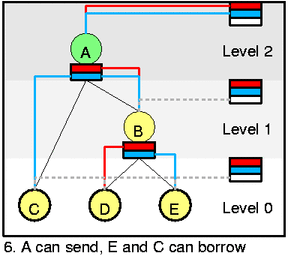
现在说一个更复杂一点的例子,在图 5 中,A 已经被消耗光了,E 开始工作,然后 C 也能开始工作,变成图 6 的样子。注意即使 D 没有被使用但是他的优先级还会被 class slot 维持,也就是红线。但是 C 和 E 都是同一个优先级,这样的话,就要使用 DRR 算法(也就是在 RR 算法上给每个变量加一个权重,也就是之前的那个量子 quantom)。然后也可以发现一个 class 可以对不同的优先级(红色和蓝色)保持 active。
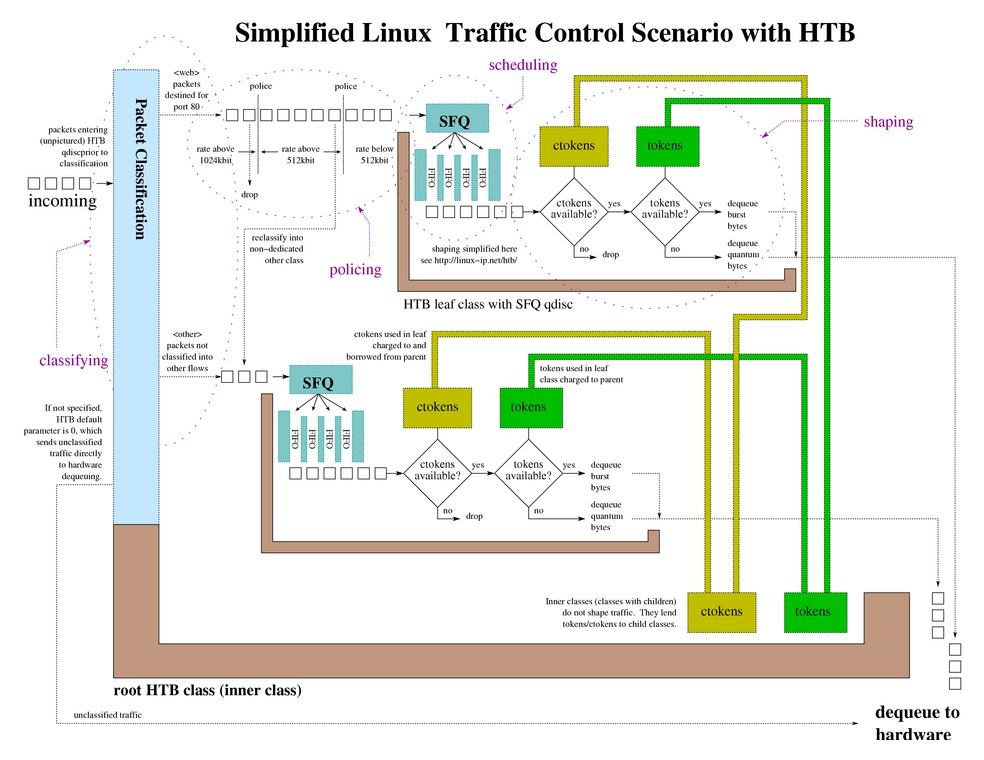
下面是一个 HTB 的全貌图,抽象的可以理解成一个从父 class 中根据优先级带权重的分享令牌的一个算法。
下面三个值对应的就是三种颜色。
1 2 3 4 5 6
/* used internaly to keep status of single class */ enum htb_cmode { HTB_CANT_SEND, /* class can't send and can't borrow */ HTB_MAY_BORROW, /* class can't send but may borrow */ HTB_CAN_SEND /* class can send */ };
struct htb_sched { struct Qdisc_class_hash clhash; int defcls; /* class where unclassified flows go to */ int rate2quantum; /* quant = rate / rate2quantum */
/* filters for qdisc itself */ struct tcf_proto __rcu *filter_list;
#define HTB_WARN_TOOMANYEVENTS 0x1 unsigned int warned; /* only one warning */ int direct_qlen; struct work_struct work;
/* non shaped skbs; let them go directly thru */ struct qdisc_skb_head direct_queue; long direct_pkts;
struct qdisc_watchdog watchdog;
s64 now; /* cached dequeue time */ struct list_head drops[TC_HTB_NUMPRIO];/* active leaves (for drops) */
/* time of nearest event per level (row) */ s64 near_ev_cache[TC_HTB_MAXDEPTH];