hugepage 分析
首先介绍一下 hugepage 的背景。
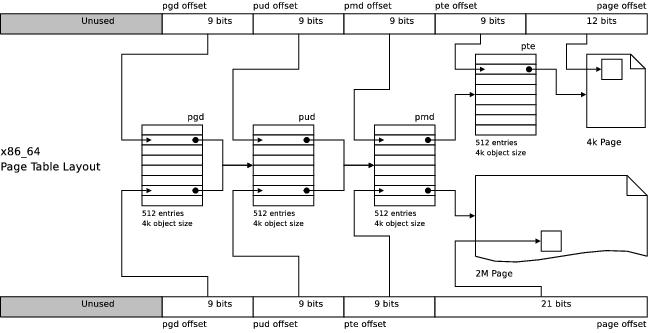
一般来说操作系统分配内存的最小单元是页,一般是 4KB 大小,但是这个页放到现在来说可能有点“不够用”,因为很多程序内存消耗很大,分配内存很频繁,所以选择更大的页可以提升性能,大页带来的好处很多,首先是页表的层次可以减少,增加访存的速度,其次是减少 TLB miss 的概率,同时 page fault 也会减少,减少到 hugepage size / 4KB (x86_64 一般有 2MB 的 hugepage 和 1GB 的 hugepage)。例如下面这张图就说明了 hugepage 带来的改变。文章中的代码使用的是 4.x 的内核版本。
hugepage 有两种类型,一种是 THP(Transparent Huge Page) ,顾名思义,就是对用户来说对这种大页是无感知的,它本身可以被分成 4KB 的小页,并且可以被 swap out,有一个 Khugepaged 周期性扫描 4KB 的页合并成大页。
另一种大页是 persistent hugepage,这种 page 是预先分配的并且不能拆分成 4KB 小页,而且不能 swap out。这种的隐患是可能在内存 fragmentation 太多分不出大页的时候压缩小页,这在内存分配有压力的时候会造成很大的性能影响。
使用 persistent hugepage 可以通过 echo 512 | sudo tee /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages,这会预先分配 512 个 2MB 的大页。具体使用是通过 fs/hugetlbfs 下实现的hugetlbfs来实现的。应用程序需要通过mmap进行文件映射来使用这些大页。具体的使用方式内核附带的一个测试可以作为参考。
这个 echo 触发的是 sysfs 的 nr_hugepages_store_common, 它会设置最大的 hugepage 个数(存在 hstate 中,一个保存 hugepage 状态的结构体),h->max_huge_pages = set_max_huge_pages(h, count, nodes_allowed);,set_max_huge_pages 有一个副作用就是调用 alloc_fresh_huge_page 来(分配或者减少)大页以达到 count 个。比如说分配会调用 ret = alloc_fresh_huge_page(h, nodes_allowed);,然后加入到 hstate 的 freelist 当中, 减少则是相反的,如果 freelist 上没有就会触发 buddysystem 的 __alloc_buddy_huge_page_no_mpol。
我们来看一下具体的实现,首先关键的结构体是 hugetlbfs_file_operations , 其中规定了 mmap 函数,也就是当我打开 hugetlbfs 文件系统下的文件对对应的 fd 调用 mmap 的时候触发的对应的函数。
1 | const struct file_operations hugetlbfs_file_operations = { |
在解释 mmap 之前,先复习一下进程空间内存的相关的内容。进程的内存空间是通过mm_struct这个结构体管理的。进程的地址空间,基本上是一些松散的区间,每个区间有相同的功能和保护属性(只读等属性),这个区间用 vm_area_struct 表示。再来看 hugetlbfs_file_mmap 中的一段代码。把申请的虚拟空间的地址长度按照大页对齐以后,保留对应个数的大页。
1 | if (hugetlb_reserve_pages(inode, |
hugetlb_reserve_pages 要处理两种逻辑,如果是 VM_MAYSHARE 就从 inode 中取出 resv_map 并且获取分配长度,不然就使用vma的长度,然后用 hugepage_subpool_get_pages 从 hugepage_subpool 中减掉对应的spool->rsv_hpages, 这个个人感觉也不是池子,只是一个统计数据。
1 | struct hstate *h = hstate_inode(inode); // 获取 hugepage state,里面保存了 hugepage 的相关信息 |
在 do_page_fault 一直调用到 __handle_mm_fault 的时候,如果对应的 vma 是大页分配的,会直接进到hugetlb_fault,最后在缺页的时候会调用hugetlb_no_page,然后调用 alloc_huge_page_node,就会看到 __alloc_buddy_huge_page,开始走 buddy system, buddy system ,这里的 buddy system 没有细说,可以参考我之前的一篇文章。
补充:
你可以理解mm_struct管理着一个vm_area_struct的链表,而 vm_area_struct 对应的主要操作函数如下(还有很多,这里只列了和本文相关的函数指针)。
1 | struct vm_operations_struct { |
对应到 hugetlbfs 就是如下的 hugetlb_vm_ops 它会在对文件 mmap 的时候,进行初始化vma->vm_ops = &hugetlb_vm_ops;。
1 | const struct vm_operations_struct hugetlb_vm_ops = { |
但是注意,hugetlb_vm_op_fault 如果被触发说明有 BUG,因为 hugepage 的 page fault 是在do_page_fault里面独立处理的,不会调用到vm_operations_struct的fault接口。mmap 走的流程是 mmap -> mmap_region -> make_pages_presetn -> get_user_pages -> handle_page_fault -> handle_mm_fault -> hugetlb_fault。
以上是大页的分配和使用的流程,希望对大家有帮助。
参考: