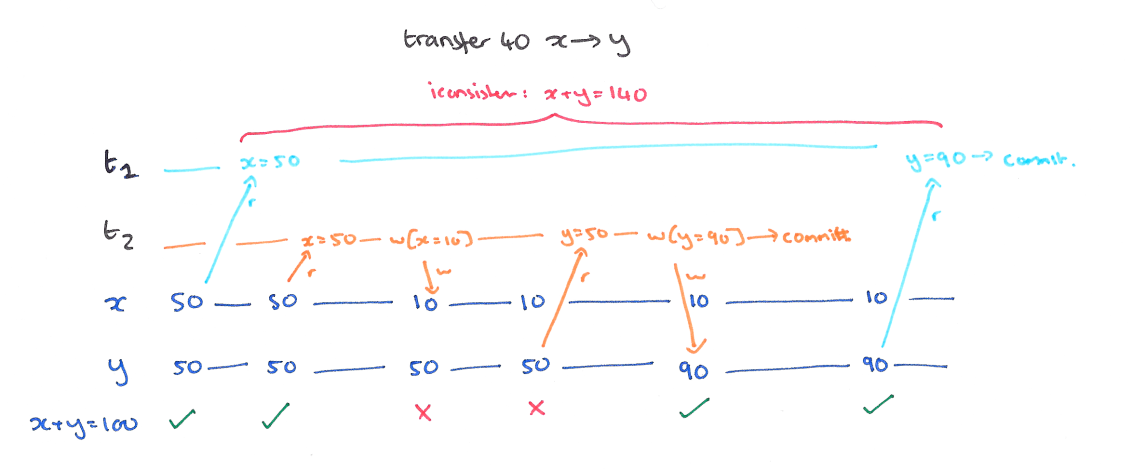
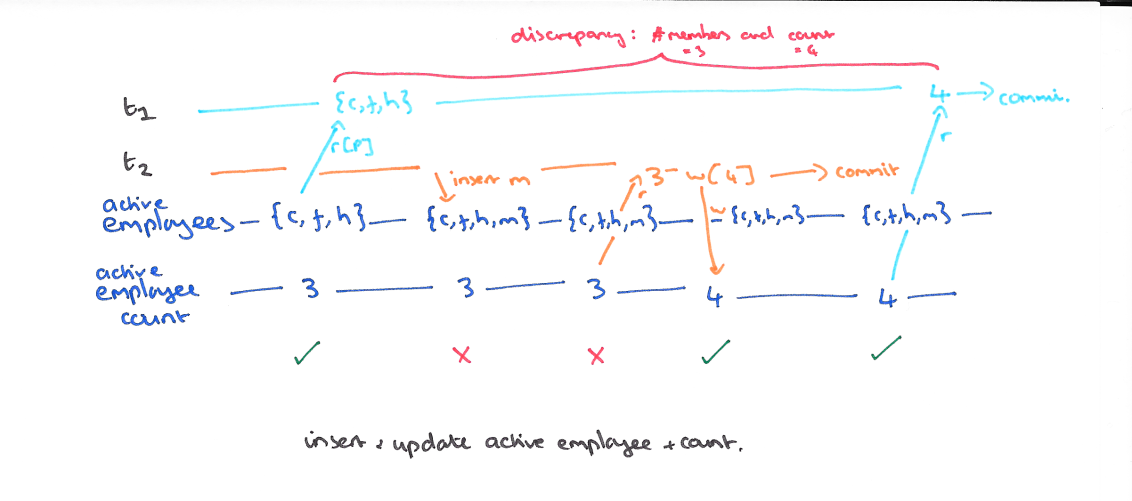
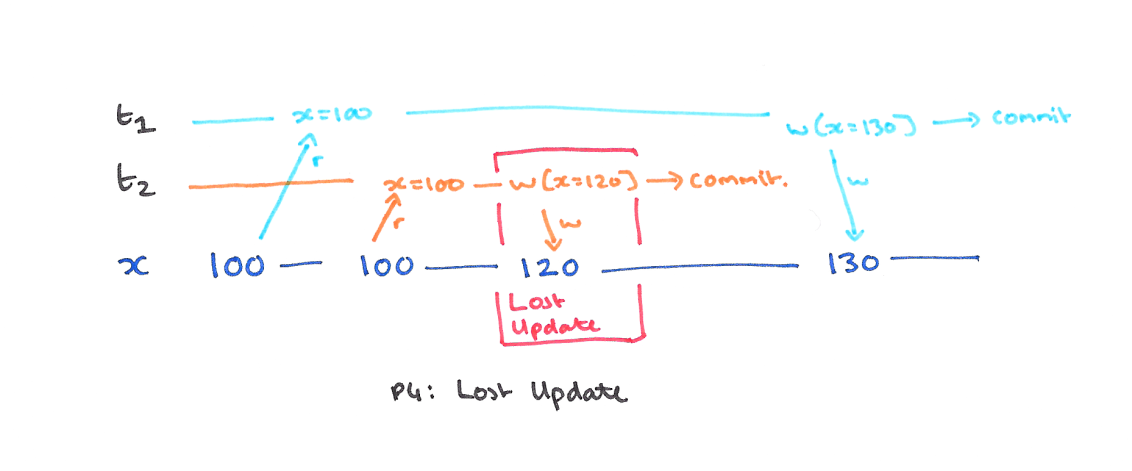
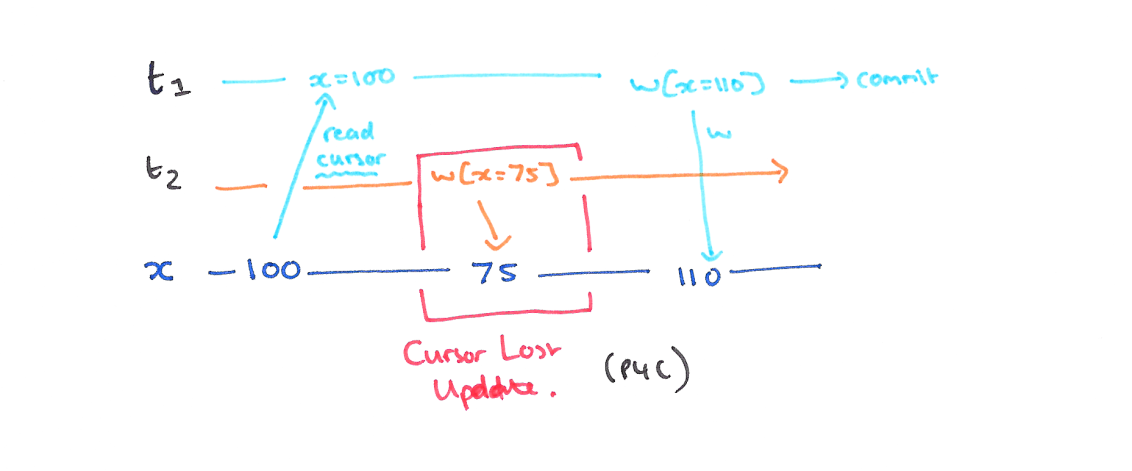
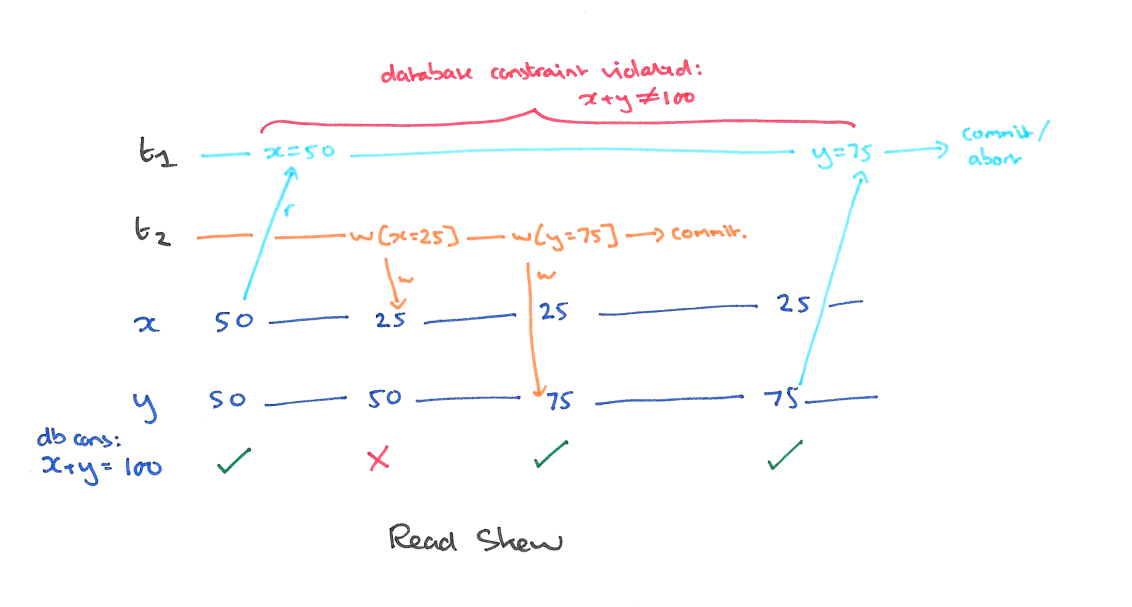
使用快照隔离 (Snapshot Isolation),快照隔离是基于 MVCC 的。当一个 T 事务开始的时候,T 会获得一个抽象的时间戳(版本),当对数据 X 进行读取的时候,并不是直接看到最新写入的数据而是在 T 开始前的所有执行中的事务中最后一个对 X 标记的版本(如果 T 修改过 X,那么看到的是自己的版本)。也就是说 T 是基于当前的数据库的一个镜像进行操作的,有点类似于 Copy And Swap,而 T 开始执行是获得的版本就是这个快照的凭证。这样能保证所有的读都是基于一个一致的状态获取的。
SI 解决冲突的方法一般是 “First-Commiter-Wins” 也就是说,如果两个并发的事务修改了同一个数据,先写的事务会成功,而后写的事务会发现版本和原本的不一致而退出事务。
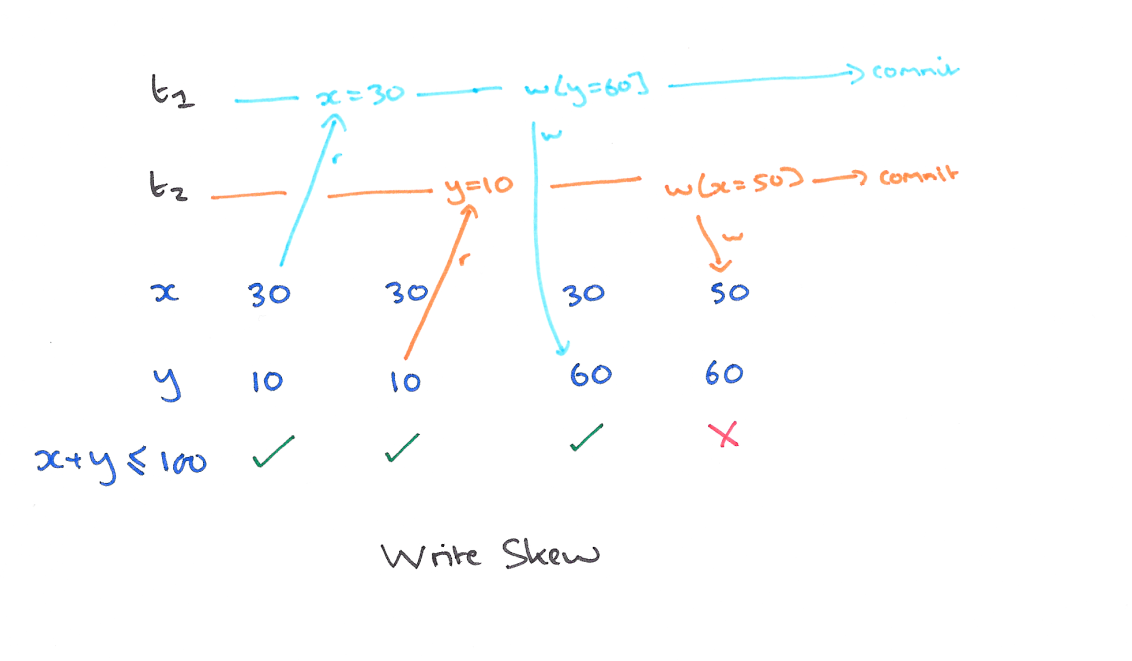
以我们的例子来说的话,T1 的 y 只会读到自己开始时候的版本,也就是 50,而不是 75,这样读偏就解决了。但是快照隔离还是不能解决另一个问题,就是写偏。这是我们要面临的新问题。
A5B write skew (写偏)
现象
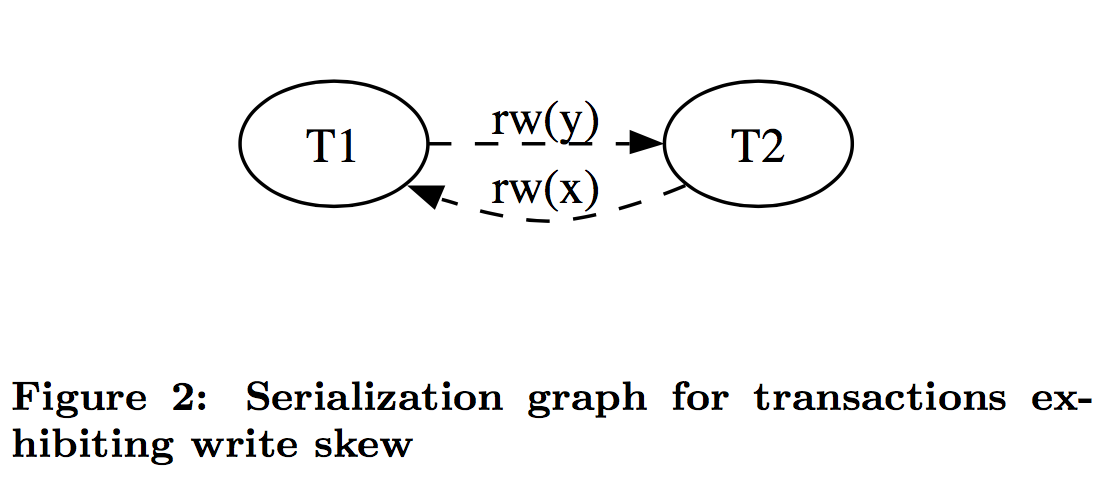
这个和读偏类似,只不过,不一致在了整个系统上。T1 写锁有 y 的新版本,T2 写锁有 x 的新版本,他们没有写冲突,导致最后系统不一致,x+y 的钱变多了。
// Since coalesced heartbeats adds latency to heartbeat messages, it is // beneficial to have it run on a faster cycle than once per tick, so that // the delay does not impact latency-sensitive features such as quiescence. func (s *Store) startCoalescedHeartbeatsLoop() { s.stopper.RunWorker(func() { ticker := time.NewTicker(s.cfg.CoalescedHeartbeatsInterval) defer func() { ticker.Stop() }()
for { select { case <-ticker.C: s.sendQueuedHeartbeats() case <-s.stopper.ShouldStop(): return } } }) }
在 Store 这个层面是对每个 Replica (一个 raft group 的成员) 是有感知的,但是每个 raft group 是独立的,只是在发送是会检查对方节点是否和现在的 raft group 有交集, 从而尝试合并消息的发送,你可以理解为在节点之间的消息通道上对不同 raft group 之间多路复用。 这就是 MultiRaft 对多个 raft group 的网络吞吐做的一个优化,代价是可能造成消息的延迟,因为毕竟是被缓存到队列里了。
其次是对SSTable的合并,SSTable是分层存储的,第一层也就是Level0(被称作 young level),是MemTable刷入的一层,允许这一层的SSTable的key有交集。对于每一层都有一个阈值(young level 是 4,其他层是按大小算的,10^L MB),如果超过阈值自动向下一层合并,从level1开始的每一次key不允许有交集。具体的做法是从 young level 中把有交集的SSTable一起和下一层key有交集的SSTable合并成一个新的SSTable,然后其他层则是从自身层取出一个和下一层有交集的SSTable合并即可。这个属性可以用归纳法证明,从0层向1层合并的时候,1层只有一个的情况下肯定不会相交,然后假设n个的时候也不相交,在n+1的时候有交集,那么n+1合并时有0层的 key 和 n 当中的有交集,但是有交集的部分会被归并掉所以矛盾,所以n+1个的时候也是没有交集的。那1层能保证没有交集的话取出一个向下合并也是类似的不会有交集。所以再重复一遍分层存储的两个属性。
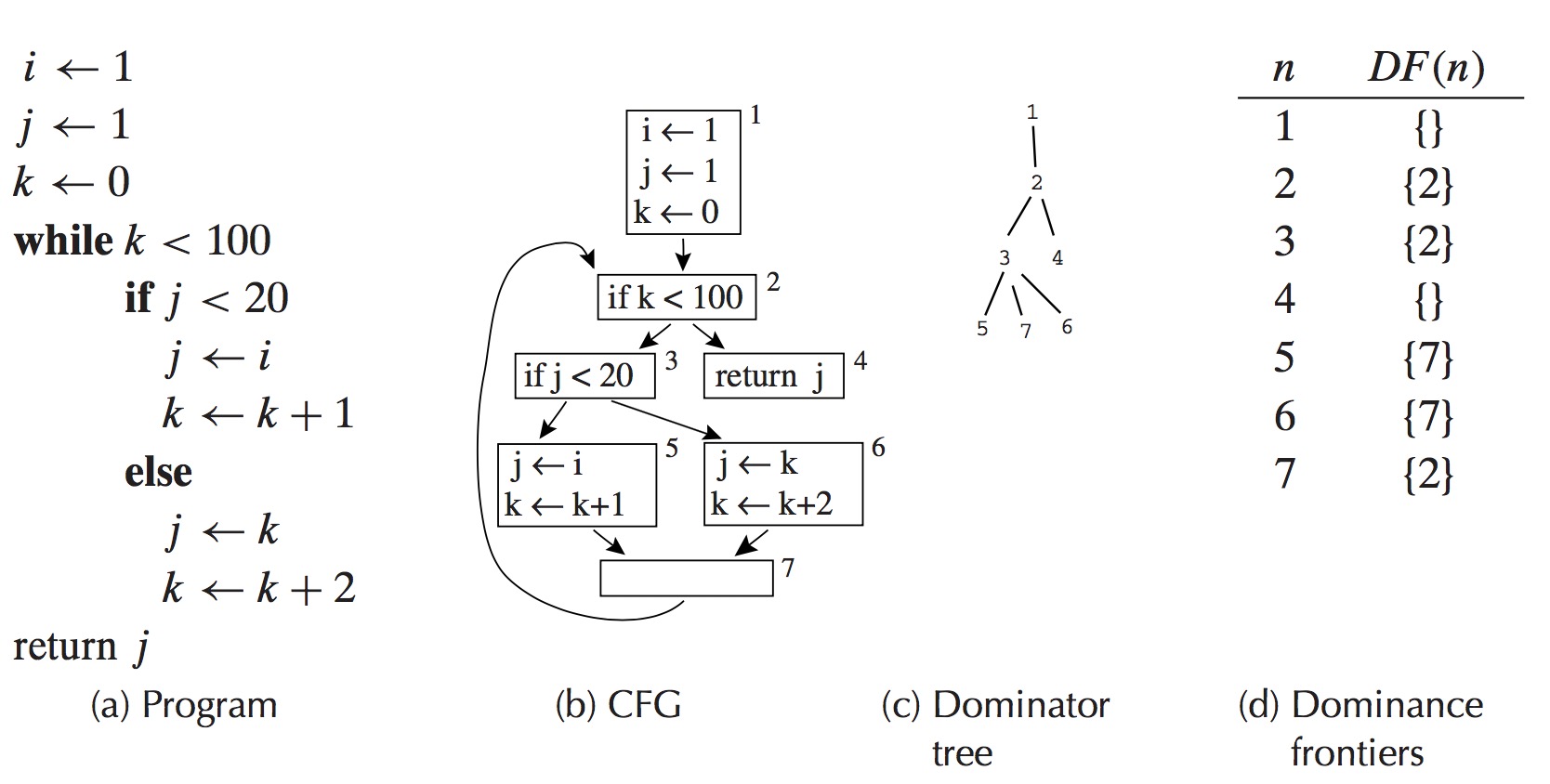
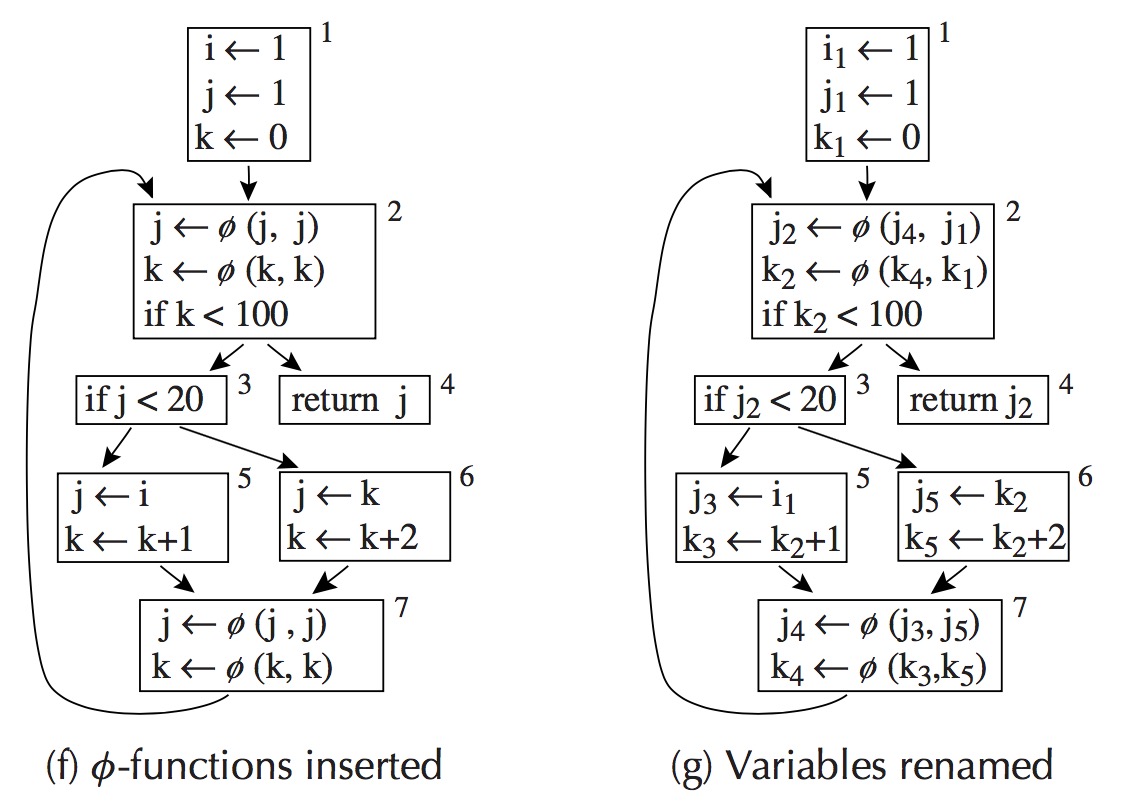
A 的 dominance frontier 含有B,如果A没有strictly dominate B,但是 dominate 了B的一个前驱节点。
用遍历的方式确定 dominance frontier 的伪代码。
1 2 3 4 5 6 7
for each node b if the number of immediate predecessors of b ≥ 2 for each p in immediate predecessors of b runner := p while runner ≠ idom(b) add b to runner’s dominance frontier set runner := idom(runner)
/* * This is the ISR for the vortex series chips. * full_bus_master_tx == 0 && full_bus_master_rx == 0 */
static irqreturn_t vortex_interrupt(int irq, void *dev_id) { struct net_device *dev = dev_id; struct vortex_private *vp = netdev_priv(dev); void __iomem *ioaddr; int status; int work_done = max_interrupt_work; int handled = 0; unsigned int bytes_compl = 0, pkts_compl = 0;
ioaddr = vp->ioaddr; spin_lock(&vp->lock);
status = ioread16(ioaddr + EL3_STATUS); // 从ioremap的地址当中读取网卡的状态,这个是设备规定的地址
if (vortex_debug > 6) pr_debug("vortex_interrupt(). status=0x%4x\n", status);
// 在中断处理的时候,设备是关中断的,这个时候可以通过观察这个status来检查设备是否有中断到来. if ((status & IntLatch) == 0) // 有中断需要处理,但是可能已经被其他中断处理函数处理了 goto handler_exit; /* No interrupt: shared IRQs cause this */ handled = 1;
if (status & IntReq) { // 中断请求 status |= vp->deferred; vp->deferred = 0; }
if (status == 0xffff) /* h/w no longer present (hotplug)? */ goto handler_exit;
if (vortex_debug > 4) pr_debug("%s: interrupt, status %4.4x, latency %d ticks.\n", dev->name, status, ioread8(ioaddr + Timer));
spin_lock(&vp->window_lock); window_set(vp, 7);
do { if (vortex_debug > 5) pr_debug("%s: In interrupt loop, status %4.4x.\n", dev->name, status); if (status & RxComplete) // 中断表示接收完成的时候调用 vortex_rx vortex_rx(dev);
if (status & TxAvailable) { // 中断表示可以传输的时候 if (vortex_debug > 5) pr_debug(" TX room bit was handled.\n"); /* There's room in the FIFO for a full-sized packet. */ iowrite16(AckIntr | TxAvailable, ioaddr + EL3_CMD); netif_wake_queue (dev); }
if (status & DMADone) {// 表示发送完成可以清除sk_buff了 if (ioread16(ioaddr + Wn7_MasterStatus) & 0x1000) { iowrite16(0x1000, ioaddr + Wn7_MasterStatus); /* Ack the event. */ pci_unmap_single(VORTEX_PCI(vp), vp->tx_skb_dma, (vp->tx_skb->len + 3) & ~3, PCI_DMA_TODEVICE); pkts_compl++; bytes_compl += vp->tx_skb->len; dev_kfree_skb_irq(vp->tx_skb); /* Release the transferred buffer */ if (ioread16(ioaddr + TxFree) > 1536) { /* * AKPM: FIXME: I don't think we need this. If the queue was stopped due to * insufficient FIFO room, the TxAvailable test will succeed and call * netif_wake_queue() */ netif_wake_queue(dev); } else { /* Interrupt when FIFO has room for max-sized packet. */ iowrite16(SetTxThreshold + (1536>>2), ioaddr + EL3_CMD); netif_stop_queue(dev); } } } /* Check for all uncommon interrupts at once. */ if (status & (HostError | RxEarly | StatsFull | TxComplete | IntReq)) { if (status == 0xffff) break; if (status & RxEarly) vortex_rx(dev); spin_unlock(&vp->window_lock); vortex_error(dev, status); spin_lock(&vp->window_lock); window_set(vp, 7); }
if (--work_done < 0) { // 最多处理work_done个frame pr_warn("%s: Too much work in interrupt, status %4.4x\n", dev->name, status); /* Disable all pending interrupts. */ do { vp->deferred |= status; // 把当前状态保存起来等下次中断的时候处理 iowrite16(SetStatusEnb | (~vp->deferred & vp->status_enable), ioaddr + EL3_CMD); iowrite16(AckIntr | (vp->deferred & 0x7ff), ioaddr + EL3_CMD); } while ((status = ioread16(ioaddr + EL3_CMD)) & IntLatch); // 把中断清掉? /* The timer will reenable interrupts. */ mod_timer(&vp->timer, jiffies + 1*HZ); break; } /* Acknowledge the IRQ. */ iowrite16(AckIntr | IntReq | IntLatch, ioaddr + EL3_CMD); } while ((status = ioread16(ioaddr + EL3_STATUS)) & (IntLatch | RxComplete));// 当有pending的中断并且是接收完成的状态
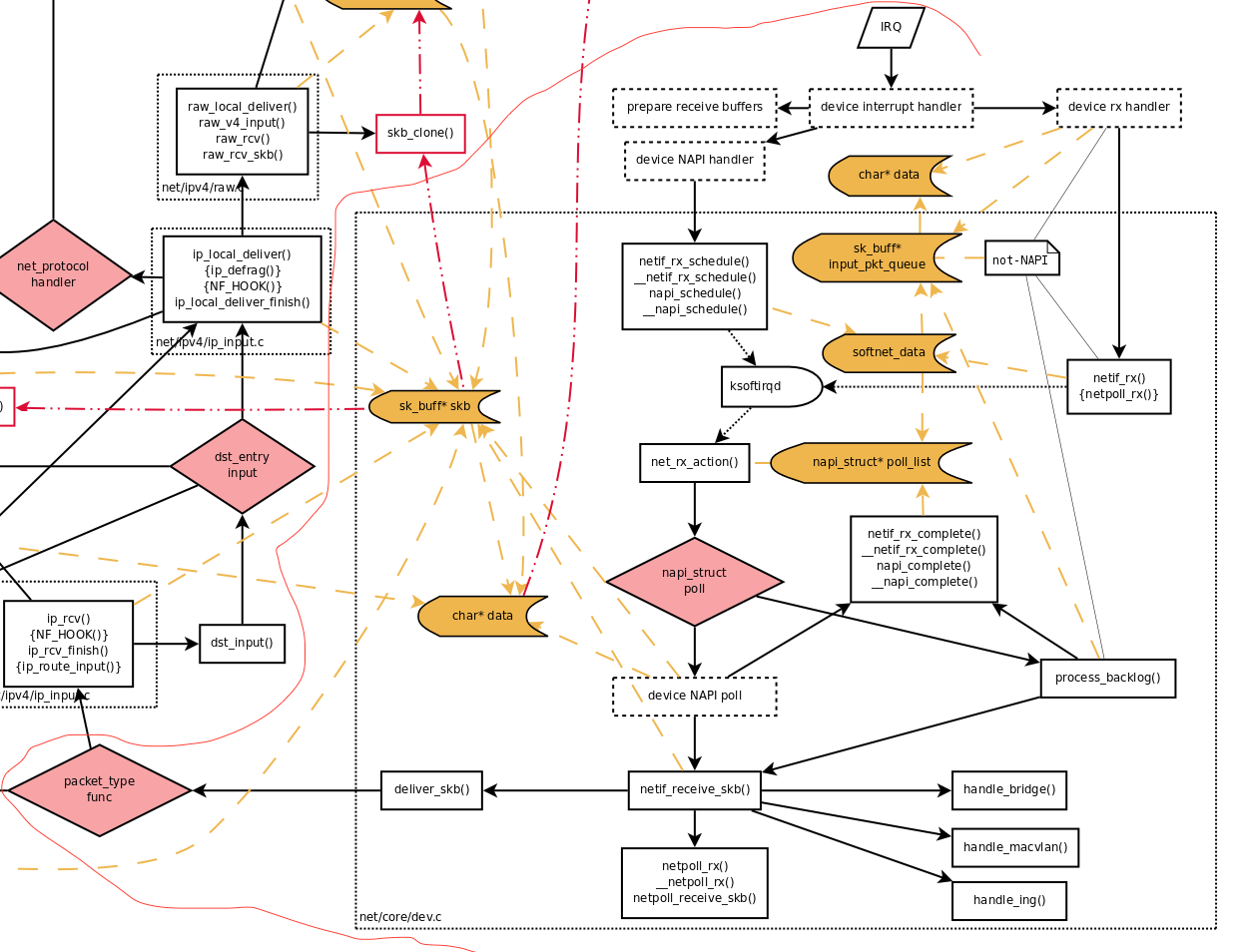
/* * enqueue_to_backlog is called to queue an skb to a per CPU backlog * queue (may be a remote CPU queue). */ static int enqueue_to_backlog(struct sk_buff *skb, int cpu, unsigned int *qtail) { struct softnet_data *sd; unsigned long flags; unsigned int qlen;
rps_lock(sd); if (!netif_running(skb->dev)) // 如果设备已经没有运行的直接丢frame goto drop; qlen = skb_queue_len(&sd->input_pkt_queue); // 获取softnet_data的&sk_buff的队列长度 if (qlen <= netdev_max_backlog && !skb_flow_limit(skb, qlen)) { // 如果没有超过最大长度并且没有被限制 if (qlen) { enqueue: __skb_queue_tail(&sd->input_pkt_queue, skb); input_queue_tail_incr_save(sd, qtail); rps_unlock(sd); local_irq_restore(flags); // 加入队列并且开中断 return NET_RX_SUCCESS; } // 如果队列为空可以尝试调度 backlog device, // 再把frame加入到队列当中。 /* Schedule NAPI for backlog device * We can use non atomic operation since we own the queue lock */ if (!__test_and_set_bit(NAPI_STATE_SCHED, &sd->backlog.state)) { if (!rps_ipi_queued(sd)) ____napi_schedule(sd, &sd->backlog); } goto enqueue; }
/* If softirq window is exhausted then punt. * Allow this to run for 2 jiffies since which will allow * an average latency of 1.5/HZ. */ if (unlikely(budget <= 0 || // 如果budge耗尽或者超过了两个jiffies就会停止 time_after_eq(jiffies, time_limit))) { sd->time_squeeze++; break; } }
static int process_backlog(struct napi_struct *napi, int quota) { int work = 0; struct softnet_data *sd = container_of(napi, struct softnet_data, backlog);
/* Check if we have pending ipi, its better to send them now, * not waiting net_rx_action() end. */ if (sd_has_rps_ipi_waiting(sd)) { local_irq_disable(); net_rps_action_and_irq_enable(sd); }
rps_lock(sd); if (skb_queue_empty(&sd->input_pkt_queue)) { /* * Inline a custom version of __napi_complete(). * only current cpu owns and manipulates this napi, * and NAPI_STATE_SCHED is the only possible flag set * on backlog. * We can use a plain write instead of clear_bit(), * and we dont need an smp_mb() memory barrier. */ napi->state = 0; rps_unlock(sd);
if (status & TxAvailable) { // 中断表示可以传输的时候 if (vortex_debug > 5) pr_debug(" TX room bit was handled.\n"); /* There's room in the FIFO for a full-sized packet. */ iowrite16(AckIntr | TxAvailable, ioaddr + EL3_CMD); netif_wake_queue (dev); }
就是说当状态可用的时候,尝试调用netif_wake_queue来触发frame的发送。
首先来看一下如何选择发送的设备。
1 2 3 4 5 6 7 8 9 10 11
/** * netif_wake_queue - restart transmit * @dev: network device * * Allow upper layers to call the device hard_start_xmit routine. * Used for flow control when transmit resources are available. */ static inline void netif_wake_queue(struct net_device *dev) { netif_tx_wake_queue(netdev_get_tx_queue(dev, 0)); }
/* * Transmit possibly several skbs, and handle the return status as * required. Holding the __QDISC___STATE_RUNNING bit guarantees that * only one CPU can execute this function. * * Returns to the caller: * 0 - queue is empty or throttled. * >0 - queue is not empty. */ int sch_direct_xmit(struct sk_buff *skb, struct Qdisc *q, struct net_device *dev, struct netdev_queue *txq, spinlock_t *root_lock, bool validate) { int ret = NETDEV_TX_BUSY;
/* And release qdisc */ spin_unlock(root_lock);
/* Note that we validate skb (GSO, checksum, ...) outside of locks */ if (validate) skb = validate_xmit_skb_list(skb, dev);
if (likely(skb)) { HARD_TX_LOCK(dev, txq, smp_processor_id()); if (!netif_xmit_frozen_or_stopped(txq)) skb = dev_hard_start_xmit(skb, dev, txq, &ret);
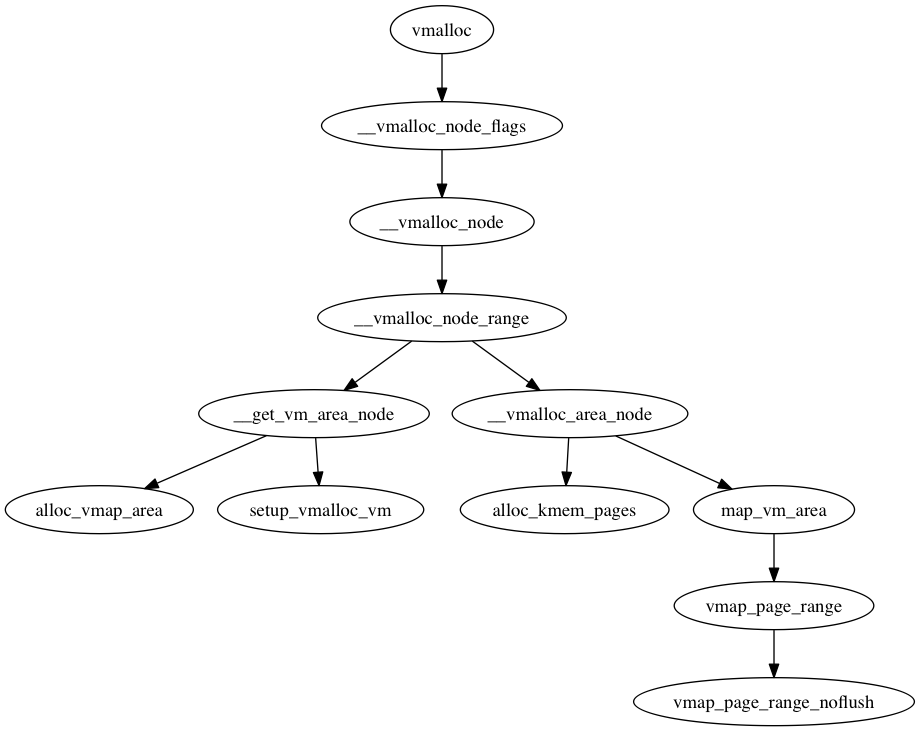
/* * Allocate a region of KVA of the specified size and alignment, within the * vstart and vend. */ static struct vmap_area *alloc_vmap_area(unsigned long size, unsigned long align, unsigned long vstart, unsigned long vend, int node, gfp_t gfp_mask) { struct vmap_area *va; struct rb_node *n; unsigned long addr; int purged = 0; struct vmap_area *first;
va = kmalloc_node(sizeof(struct vmap_area), gfp_mask & GFP_RECLAIM_MASK, node); if (unlikely(!va)) return ERR_PTR(-ENOMEM);
/* * Only scan the relevant parts containing pointers to other objects * to avoid false negatives. */ kmemleak_scan_area(&va->rb_node, SIZE_MAX, gfp_mask & GFP_RECLAIM_MASK);
retry: spin_lock(&vmap_area_lock); /* * Invalidate cache if we have more permissive parameters. * cached_hole_size notes the largest hole noticed _below_ * the vmap_area cached in free_vmap_cache: if size fits * into that hole, we want to scan from vstart to reuse * the hole instead of allocating above free_vmap_cache. * Note that __free_vmap_area may update free_vmap_cache * without updating cached_hole_size or cached_align. */ if (!free_vmap_cache || /* 缓存为空, 并且在下面条件满足的时候不使用缓存 */ size < cached_hole_size || /* 至少有一个空洞可以复用, 直接从头开始搜索 */ vstart < cached_vstart || /* 别缓存的起点小 */ align < cached_align) { /* 对齐大小比缓存的小 */ nocache: cached_hole_size = 0; free_vmap_cache = NULL; } /* record if we encounter less permissive parameters */ cached_vstart = vstart; cached_align = align;
/* find starting point for our search */ if (free_vmap_cache) { /* 这个地方是用缓存上次搜索的结果, 每次找到以后会存到这里 */ first = rb_entry(free_vmap_cache, struct vmap_area, rb_node); addr = ALIGN(first->va_end, align); if (addr < vstart) /* 缓存的末尾对齐之后超出了范围从头开始搜索 */ goto nocache; if (addr + size < addr) /* 整数溢出 */ goto overflow;
while (n) { /* 用对齐之后的vstart正好<=va_ned&&>=va_start的节点 */ struct vmap_area *tmp; tmp = rb_entry(n, struct vmap_area, rb_node); if (tmp->va_end >= addr) { first = tmp; if (tmp->va_start <= addr) break; n = n->rb_left; } else n = n->rb_right; }
if (!first) goto found; } /* from the starting point, walk areas until a suitable hole is found */ while (addr + size > first->va_start && addr + size <= vend) { if (addr + cached_hole_size < first->va_start) /* cached_hole_size */ cached_hole_size = first->va_start - addr; /* 缓存最大的空洞大小 */ addr = ALIGN(first->va_end, align); if (addr + size < addr) goto overflow;
if (list_is_last(&first->list, &vmap_area_list)) goto found;
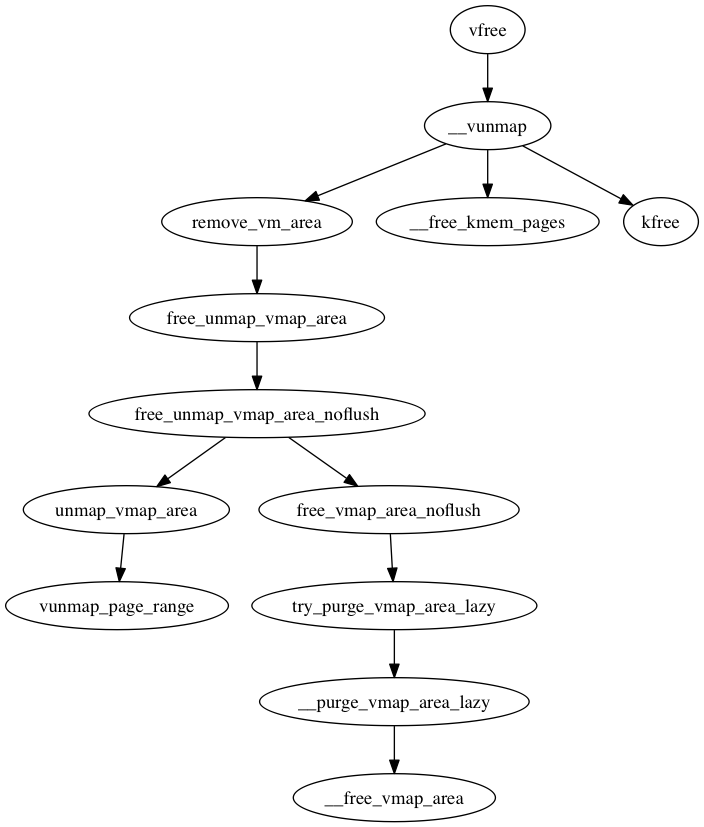
if (gfpflags_allow_blocking(gfp_mask)) { unsigned long freed = 0; blocking_notifier_call_chain(&vmap_notify_list, 0, &freed); if (freed > 0) { purged = 0; goto retry; } }
if (printk_ratelimit()) pr_warn("vmap allocation for size %lu failed: use vmalloc=<size> to increase size\n", size); kfree(va); return ERR_PTR(-EBUSY); }
/* * * Set up page tables in kva (addr, end). The ptes shall have prot "prot", and * will have pfns corresponding to the "pages" array. * 这里的kva指的是kernel virtual address. * Ie. pte at addr+N*PAGE_SIZE shall point to pfn corresponding to pages[N] */ static int vmap_page_range_noflush(unsigned long start, unsigned long end, pgprot_t prot, struct page **pages) { pgd_t *pgd; unsigned long next; unsigned long addr = start; int err = 0; int nr = 0;
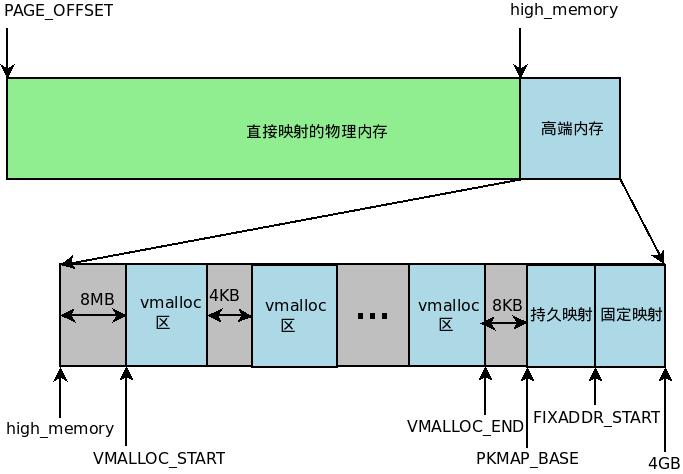
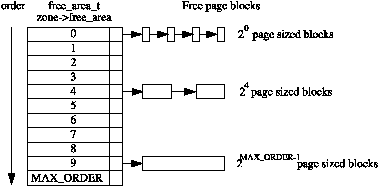
/* * PAGE_ALLOC_COSTLY_ORDER is the order at which allocations are deemed * costly to service. That is between allocation orders which should * coalesce naturally under reasonable reclaim pressure and those which * will not. */ /* 内核认为超过8个页算是大的内存分配 */ #define PAGE_ALLOC_COSTLY_ORDER 3
enum { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_RECLAIMABLE, MIGRATE_PCPTYPES, /* the number of types on the pcp lists */ MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES, #ifdef CONFIG_CMA /* * MIGRATE_CMA migration type is designed to mimic the way * ZONE_MOVABLE works. Only movable pages can be allocated * from MIGRATE_CMA pageblocks and page allocator never * implicitly change migration type of MIGRATE_CMA pageblock. * * The way to use it is to change migratetype of a range of * pageblocks to MIGRATE_CMA which can be done by * __free_pageblock_cma() function. What is important though * is that a range of pageblocks must be aligned to * MAX_ORDER_NR_PAGES should biggest page be bigger then * a single pageblock. */ MIGRATE_CMA, #endif #ifdef CONFIG_MEMORY_ISOLATION MIGRATE_ISOLATE, /* can't allocate from here */ #endif MIGRATE_TYPES };
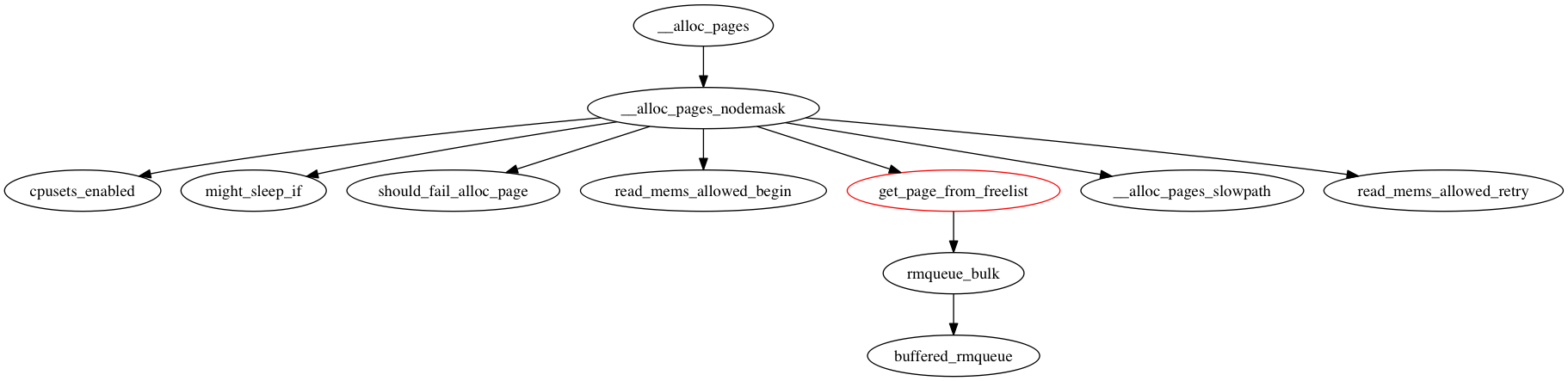
/* * Do the hard work of removing an element from the buddy allocator. * Call me with the zone->lock already held. */ static struct page *__rmqueue(struct zone *zone, unsigned int order, int migratetype) { struct page *page;
page = __rmqueue_smallest(zone, order, migratetype); if (unlikely(!page)) { if (migratetype == MIGRATE_MOVABLE) page = __rmqueue_cma_fallback(zone, order); /* MOVABLE的失败优先从cma迁移 */
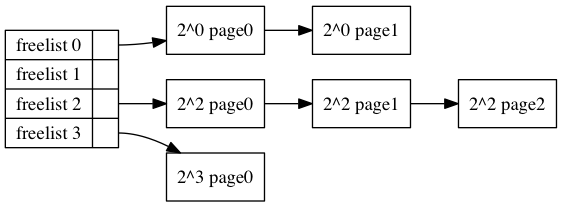
/* * Go through the free lists for the given migratetype and remove * the smallest available page from the freelists */ static inline struct page *__rmqueue_smallest(struct zone *zone, unsigned int order, int migratetype) { unsigned int current_order; struct free_area *area; struct page *page;
/* Find a page of the appropriate size in the preferred list */ for (current_order = order; current_order < MAX_ORDER; ++current_order) { area = &(zone->free_area[current_order]); page = list_first_entry_or_null(&area->free_list[migratetype], struct page, lru); if (!page) continue; /* 如果失败就尝试更大的块 */ list_del(&page->lru); /* 这个lru取决他的上下文,比如在这里就是free_list */ rmv_page_order(page); /* 设置flags */ area->nr_free--; /* free计数器-1 */ expand(zone, page, order, current_order, area, migratetype); set_pcppage_migratetype(page, migratetype);/* 设置page的migratetype */ return page; } return NULL; }
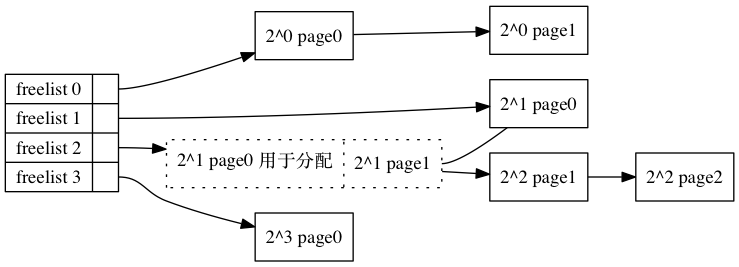
/* * The order of subdivision here is critical for the IO subsystem. * Please do not alter this order without good reasons and regression * testing. Specifically, as large blocks of memory are subdivided, * the order in which smaller blocks are delivered depends on the order * they're subdivided in this function. This is the primary factor * influencing the order in which pages are delivered to the IO * subsystem according to empirical testing, and this is also justified * by considering the behavior of a buddy system containing a single * large block of memory acted on by a series of small allocations. * This behavior is a critical factor in sglist merging's success. * * -- nyc */ static inline void expand(struct zone *zone, struct page *page, int low, int high, struct free_area *area, int migratetype) { unsigned long size = 1 << high;
while (high > low) { /* 从高阶向低阶迭代 */ area--; high--; size >>= 1; VM_BUG_ON_PAGE(bad_range(zone, &page[size]), &page[size]); /* guardpage TODO */ if (IS_ENABLED(CONFIG_DEBUG_PAGEALLOC) && debug_guardpage_enabled() && high < debug_guardpage_minorder()) { /* * Mark as guard pages (or page), that will allow to * merge back to allocator when buddy will be freed. * Corresponding page table entries will not be touched, * pages will stay not present in virtual address space */ set_page_guard(zone, &page[size], high, migratetype); continue; } list_add(&page[size].lru, &area->free_list[migratetype]); /* 把page放到area的free_list里面, 这个page是一个数组形式的 比如之前是8 这里变成4,那么后半部分会被留下来,前半部分会继续用于迭代 */ area->nr_free++; /* 空闲块计数器+1 */ set_page_order(&page[size], high); /* 相当于page->private = high 表示自己属于order为high的阶的block中 */ } }
/* * This array describes the order lists are fallen back to when * the free lists for the desirable migrate type are depleted */ static int fallbacks[MIGRATE_TYPES][4] = { [MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_TYPES }, [MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_TYPES }, [MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_TYPES }, #ifdef CONFIG_CMA [MIGRATE_CMA] = { MIGRATE_TYPES }, /* Never used */ #endif #ifdef CONFIG_MEMORY_ISOLATION [MIGRATE_ISOLATE] = { MIGRATE_TYPES }, /* Never used */ #endif };
/* Remove an element from the buddy allocator from the fallback list */ static inline struct page * __rmqueue_fallback(struct zone *zone, unsigned int order, int start_migratetype) { struct free_area *area; unsigned int current_order; struct page *page; int fallback_mt; bool can_steal;
/* Find the largest possible block of pages in the other list */ for (current_order = MAX_ORDER-1; current_order >= order && current_order <= MAX_ORDER-1; --current_order) { area = &(zone->free_area[current_order]); /* 遍历fallback table 找到合适的fallback migratetype 要综合考虑: 是否有超过一定阈值的空闲页,并且是可以退化的页类型 */ fallback_mt = find_suitable_fallback(area, current_order, start_migratetype, false, &can_steal); if (fallback_mt == -1) continue;
/* Remove the page from the freelists */ area->nr_free--; list_del(&page->lru); rmv_page_order(page);
expand(zone, page, order, current_order, area, start_migratetype); /* * The pcppage_migratetype may differ from pageblock's * migratetype depending on the decisions in * find_suitable_fallback(). This is OK as long as it does not * differ for MIGRATE_CMA pageblocks. Those can be used as * fallback only via special __rmqueue_cma_fallback() function */ set_pcppage_migratetype(page, start_migratetype);
/* * Structure for holding the mostly immutable allocation parameters passed * between functions involved in allocations, including the alloc_pages* * family of functions. * * nodemask, migratetype and high_zoneidx are initialized only once in * __alloc_pages_nodemask() and then never change. * * zonelist, preferred_zone and classzone_idx are set first in * __alloc_pages_nodemask() for the fast path, and might be later changed * in __alloc_pages_slowpath(). All other functions pass the whole strucure * by a const pointer. */ struct alloc_context { struct zonelist *zonelist; nodemask_t *nodemask; struct zoneref *preferred_zoneref; int migratetype; enum zone_type high_zoneidx; bool spread_dirty_pages; };
struct per_cpu_pages { int count; /* number of pages in the list */ int high; /* high watermark, emptying needed */ int batch; /* chunk size for buddy add/remove */
/* Lists of pages, one per migrate type stored on the pcp-lists */ struct list_head lists[MIGRATE_PCPTYPES]; };
/* * Freeing function for a buddy system allocator. * * The concept of a buddy system is to maintain direct-mapped table * (containing bit values) for memory blocks of various "orders". * The bottom level table contains the map for the smallest allocatable * units of memory (here, pages), and each level above it describes * pairs of units from the levels below, hence, "buddies". * At a high level, all that happens here is marking the table entry * at the bottom level available, and propagating the changes upward * as necessary, plus some accounting needed to play nicely with other * parts of the VM system. * At each level, we keep a list of pages, which are heads of continuous * free pages of length of (1 << order) and marked with _mapcount * PAGE_BUDDY_MAPCOUNT_VALUE. Page's order is recorded in page_private(page) * field. * So when we are allocating or freeing one, we can derive the state of the * other. That is, if we allocate a small block, and both were * free, the remainder of the region must be split into blocks. * If a block is freed, and its buddy is also free, then this * triggers coalescing into a block of larger size. * * -- nyc */
static inline void __free_one_page(struct page *page, /* 把page加回到free_list里面 */ unsigned long pfn, struct zone *zone, unsigned int order, int migratetype) { unsigned long page_idx; unsigned long combined_idx; unsigned long uninitialized_var(buddy_idx); struct page *buddy; unsigned int max_order;
continue_merging: while (order < max_order - 1) { buddy_idx = __find_buddy_index(page_idx, order);/* 获取buddy的下标 */ buddy = page + (buddy_idx - page_idx); /* 根据相对距离得到buddy page */ if (!page_is_buddy(page, buddy, order)) /* 如果不是buddy就结束合并 */ goto done_merging; /* * Our buddy is free or it is CONFIG_DEBUG_PAGEALLOC guard page, * merge with it and move up one order. */ if (page_is_guard(buddy)) { clear_page_guard(zone, buddy, order, migratetype); } else { /* 把buddy从free_area当中移除 */ list_del(&buddy->lru); zone->free_area[order].nr_free--; rmv_page_order(buddy); } combined_idx = buddy_idx & page_idx; page = page + (combined_idx - page_idx); page_idx = combined_idx; order++; /* 向上合并 */ } if (max_order < MAX_ORDER) { /* If we are here, it means order is >= pageblock_order. * We want to prevent merge between freepages on isolate * pageblock and normal pageblock. Without this, pageblock * isolation could cause incorrect freepage or CMA accounting. * * We don't want to hit this code for the more frequent * low-order merging. */ /* 在这里说明已经超出了pageblock的order, 可能在不同的migratetype的block边界了,这里再检查一次是不是isolate, 不允许节点间迁移的page, 如果是的话就要结束合并的迭代,不然继续向上合并 */ if (unlikely(has_isolate_pageblock(zone))) { int buddy_mt;
/* * If this is not the largest possible page, check if the buddy * of the next-highest order is free. If it is, it's possible * that pages are being freed that will coalesce soon. In case, * that is happening, add the free page to the tail of the list * so it's less likely to be used soon and more likely to be merged * as a higher order page */ if ((order < MAX_ORDER-2) && pfn_valid_within(page_to_pfn(buddy))) { /* 这个条件判断没有合并到最大块, 内核认为很有可能接下来这个块和其他free的块合并, 从减少碎片的角度来说会更倾向于放到链表的末尾, 让这个块的free状态保持久一点, 更有机会被合并成更大的块 */ struct page *higher_page, *higher_buddy; combined_idx = buddy_idx & page_idx; /* 合并后的idx */ higher_page = page + (combined_idx - page_idx); /* 合并后的page */ buddy_idx = __find_buddy_index(combined_idx, order + 1); /* 向上寻找buddy */ higher_buddy = higher_page + (buddy_idx - combined_idx); if (page_is_buddy(higher_page, higher_buddy, order + 1)) { list_add_tail(&page->lru, &zone->free_area[order].free_list[migratetype]); goto out; } }
// All node types implement the Node interface. type Node interface { Pos() token.Pos // position of first character belonging to the node End() token.Pos // position of first character immediately after the node }
// All expression nodes implement the Expr interface. type Expr interface { Node exprNode() }
// All statement nodes implement the Stmt interface. type Stmt interface { Node stmtNode() }
// All declaration nodes implement the Decl interface. type Decl interface { Node declNode() }
// The parser structure holds the parser's internal state. type parser struct { file *token.File errors scanner.ErrorList // 解析过程中遇到的错误列表 scanner scanner.Scanner // 词法分析器.
// Tracing/debugging mode Mode // parsing mode // 解析模式 trace bool // == (mode & Trace != 0) indent int // indentation used for tracing output
// Comments 列表 comments []*ast.CommentGroup leadComment *ast.CommentGroup // last lead comment lineComment *ast.CommentGroup // last line comment
// Next token pos token.Pos // token position tok token.Token // one token look-ahead lit string // token literal
// Error recovery // (used to limit the number of calls to syncXXX functions // w/o making scanning progress - avoids potential endless // loops across multiple parser functions during error recovery) syncPos token.Pos // last synchronization position 解析错误的同步点. syncCnt int // number of calls to syncXXX without progress
// Non-syntactic parser control // 非语法性的控制 // <0 在控制语句中, >= 在表达式中. exprLev int // < 0: in control clause, >= 0: in expression // 正在解析右值表达式 inRhs bool // if set, the parser is parsing a rhs expression
// Ordinary identifier scopes pkgScope *ast.Scope // pkgScope.Outer == nil topScope *ast.Scope // top-most scope; may be pkgScope unresolved []*ast.Ident // unresolved identifiers imports []*ast.ImportSpec // list of imports
// Label scopes // (maintained by open/close LabelScope) labelScope *ast.Scope // label scope for current function targetStack [][]*ast.Ident // stack of unresolved labels }
func (p *parser) parseStmt() (s ast.Stmt) { if p.trace { defer un(trace(p, "Statement")) }
switch p.tok { case token.CONST, token.TYPE, token.VAR: s = &ast.DeclStmt{Decl: p.parseDecl(syncStmt)} case // tokens that may start an expression token.IDENT, token.INT, token.FLOAT, token.IMAG, token.CHAR, token.STRING, token.FUNC, token.LPAREN, // operands token.LBRACK, token.STRUCT, token.MAP, token.CHAN, token.INTERFACE, // composite types token.ADD, token.SUB, token.MUL, token.AND, token.XOR, token.ARROW, token.NOT: // unary operators s, _ = p.parseSimpleStmt(labelOk) // because of the required look-ahead, labeled statements are // parsed by parseSimpleStmt - don't expect a semicolon after // them if _, isLabeledStmt := s.(*ast.LabeledStmt); !isLabeledStmt { p.expectSemi() } case token.GO: s = p.parseGoStmt() case token.DEFER: s = p.parseDeferStmt() case token.RETURN: s = p.parseReturnStmt() case token.BREAK, token.CONTINUE, token.GOTO, token.FALLTHROUGH: s = p.parseBranchStmt(p.tok) case token.LBRACE: s = p.parseBlockStmt() ...省略
// 解析左列表 一般是 l := r 或者 l1,l2 = r1,r2 或者 l <- r 或者 l++ x := p.parseLhsList() switch p.tok { case token.DEFINE, token.ASSIGN, token.ADD_ASSIGN, token.SUB_ASSIGN, token.MUL_ASSIGN, token.QUO_ASSIGN, token.REM_ASSIGN, token.AND_ASSIGN, token.OR_ASSIGN, token.XOR_ASSIGN, token.SHL_ASSIGN, token.SHR_ASSIGN, token.AND_NOT_ASSIGN: // 如果看到range,range作为一种运算符按照range rhs来解析 // 如果没看到就按正常赋值语句解析 lhs op rhs 来解析op可以是上面那些token中的一种. pos, tok := p.pos, p.tok p.next() var y []ast.Expr isRange := false if mode == rangeOk && p.tok == token.RANGE && (tok == token.DEFINE || tok == token.ASSIGN) { pos := p.pos p.next() y = []ast.Expr{&ast.UnaryExpr{OpPos: pos, Op: token.RANGE, X: p.parseRhs()}} isRange = true } else { y = p.parseRhsList() } as := &ast.AssignStmt{Lhs: x, TokPos: pos, Tok: tok, Rhs: y}
// 碰到":"找一个ident, 构成 goto: indent 之类的语句. case token.COLON: colon := p.pos p.next() if label, isIdent := x[0].(*ast.Ident); mode == labelOk && isIdent { // Go spec: The scope of a label is the body of the function // in which it is declared and excludes the body of any nested // function. stmt := &ast.LabeledStmt{Label: label, Colon: colon, Stmt: p.parseStmt()} p.declare(stmt, nil, p.labelScope, ast.Lbl, label) return stmt, false } // 碰到"<-",就构成 <- rhs 这样的语句. case token.ARROW: // send statement arrow := p.pos p.next() y := p.parseRhs() return &ast.SendStmt{Chan: x[0], Arrow: arrow, Value: y}, false
// 碰到"++"或者"--"就构成一个单独的自增语句. case token.INC, token.DEC: // increment or decrement s := &ast.IncDecStmt{X: x[0], TokPos: p.pos, Tok: p.tok} p.next() return s, false }