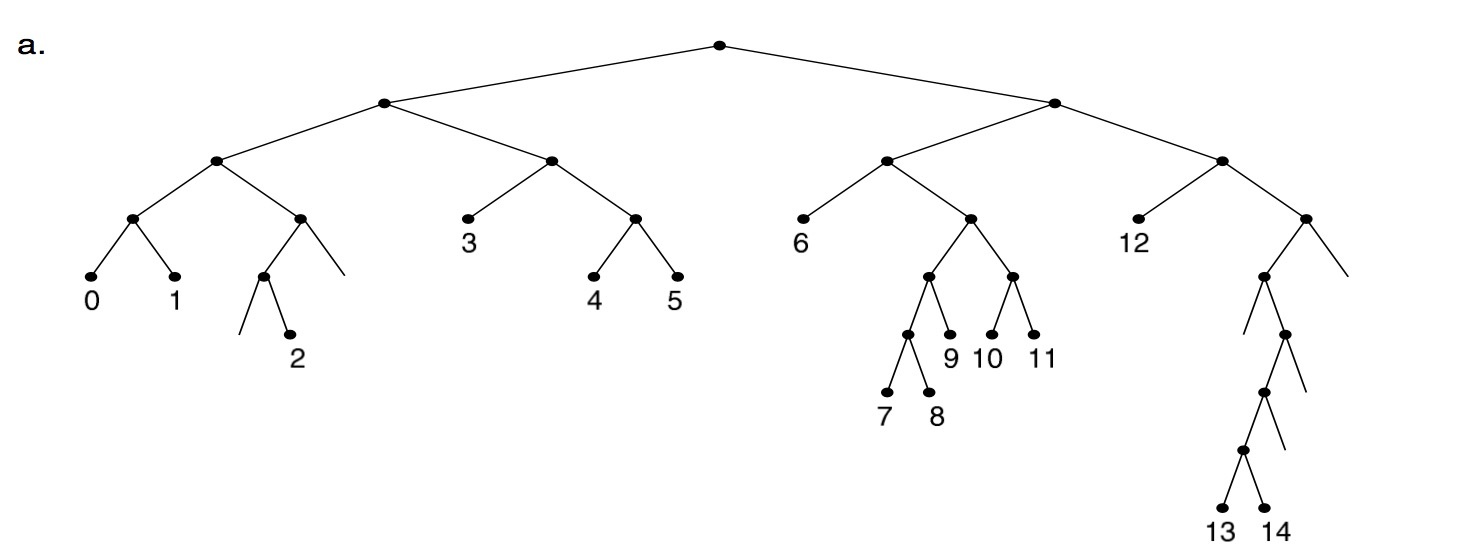
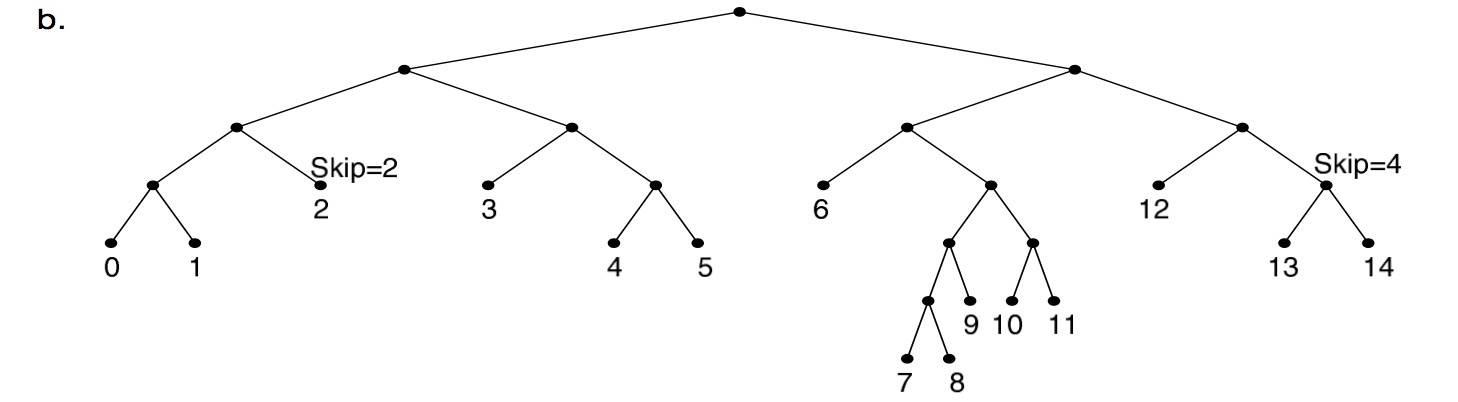
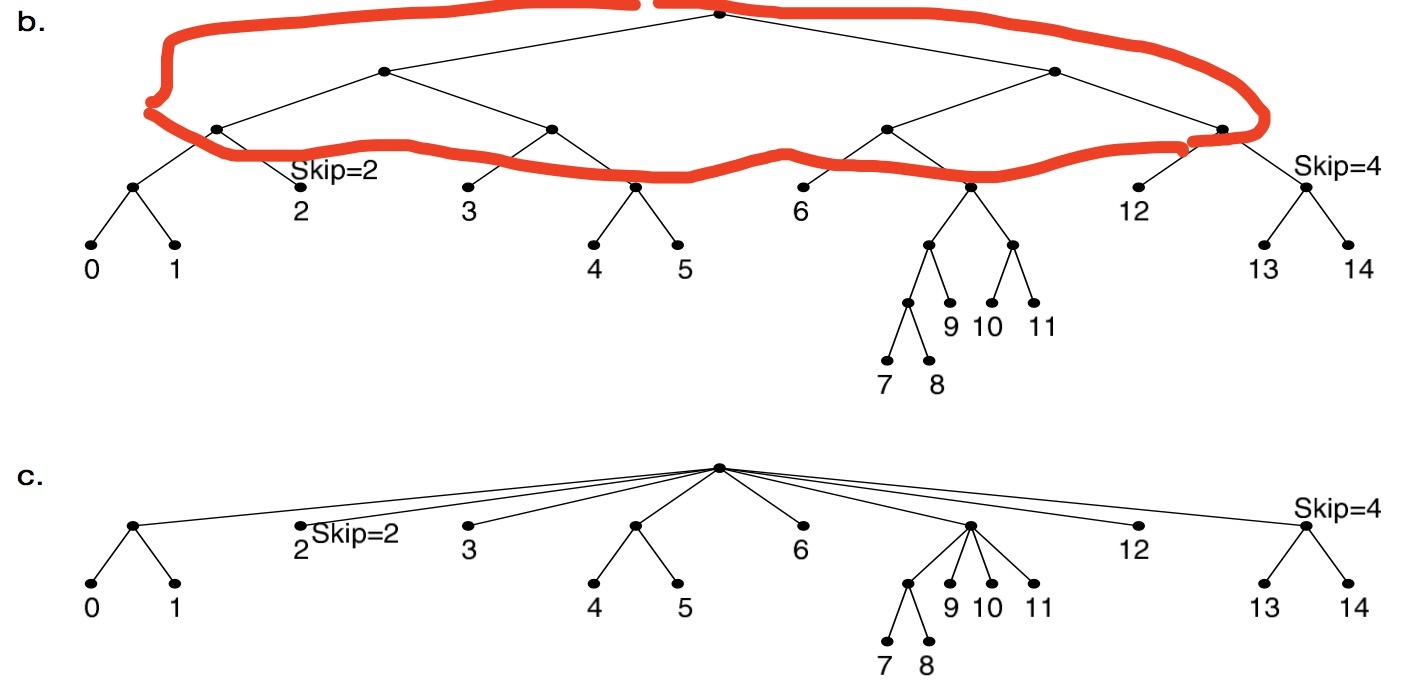
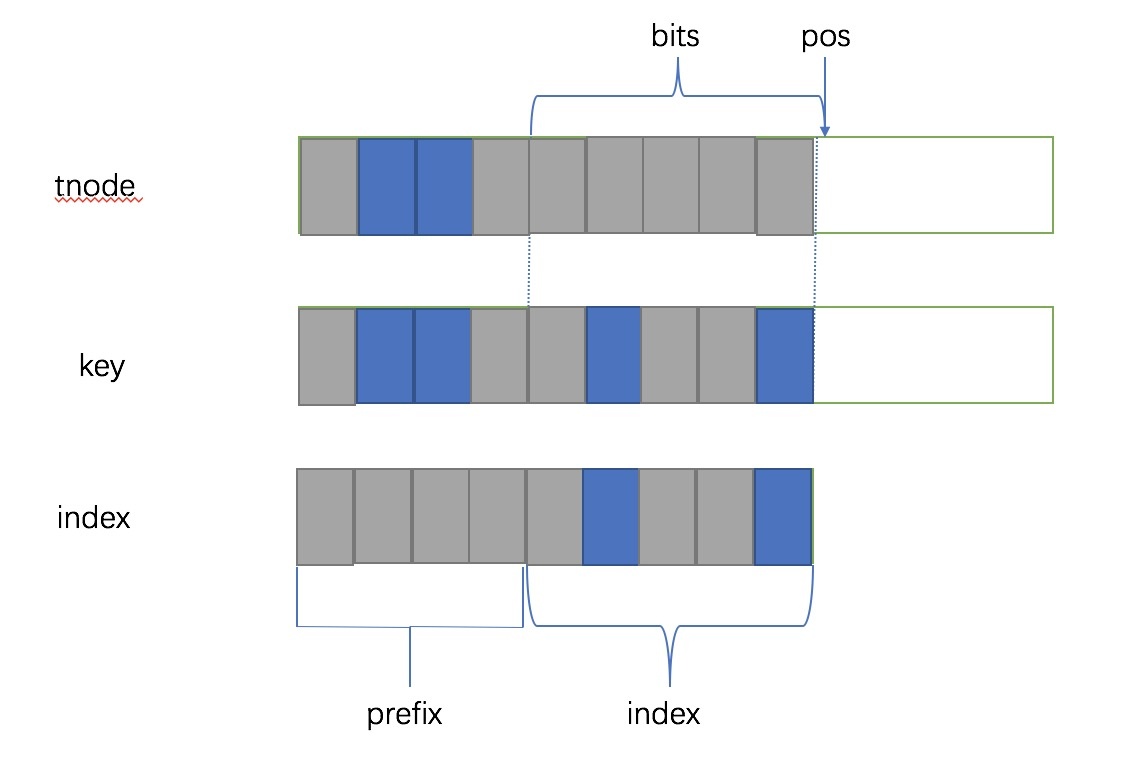
/* rcu_read_lock needs to be hold by caller from readside */ staticstruct key_vector *fib_find_node(struct trie *t, struct key_vector **tp, u32 key) { structkey_vector *pn, *n = t->kv; unsignedlong index = 0;
do { pn = n; n = get_child_rcu(n, index);
if (!n) break;
index = get_cindex(key, n);
/* This bit of code is a bit tricky but it combines multiple * checks into a single check. The prefix consists of the * prefix plus zeros for the bits in the cindex. The index * is the difference between the key and this value. From * this we can actually derive several pieces of data. * if (index >= (1ul << bits)) * we have a mismatch in skip bits and failed * else * we know the value is cindex * * This check is safe even if bits == KEYLENGTH due to the * fact that we can only allocate a node with 32 bits if a * long is greater than 32 bits. */ if (index >= (1ul << n->bits)) { n = NULL; break; }
/* keep searching until we find a perfect match leaf or NULL */ } while (IS_TNODE(n));
/* retrieve child from parent node */ n = get_child(tp, get_index(key, tp));
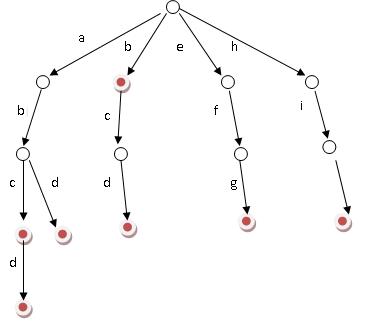
如果有子节点,就要创建一个新的 tnode,再把这个 key 给插入。
1 2 3 4 5 6 7 8
/* Case 2: n is a LEAF or a TNODE and the key doesn't match. * * Add a new tnode here * first tnode need some special handling * leaves us in position for handling as case 3 */ if (n) { structkey_vector *tn;
__fls find last set bit,就是找到 pos,然后扩展出有两个选择(2 的 1 次方)的 tnode。
/* track the tnode via the pointer from the parent instead of * doing it ourselves. This way we can let RCU fully do its * thing without us interfering */ BUG_ON(tn != get_child(tp, cindex));
/* Double as long as the resulting node has a number of * nonempty nodes that are above the threshold. */
should_inflate 决定要不要压缩的依据是根据动态压缩算法来的(引用4),直观的来说就是高度超过了一个动态计算的阈值,并且还没压缩超过十次就会继续压缩。这个动态阈值的算法是用非空子节点的数目如果超过压缩之后子节点数目的一半就值得压缩。而 inflate 做的事情就把层级压缩一层,也就是把 children 的 children 按照 bits 的匹配放到 parent 的 new_children 当中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
while (should_inflate(tp, tn) && max_work) { tp = inflate(t, tn); if (!tp) { #ifdef CONFIG_IP_FIB_TRIE_STATS this_cpu_inc(stats->resize_node_skipped); #endif break; }
max_work--; tn = get_child(tp, cindex); }
/* update parent in case inflate failed */ tp = node_parent(tn);
/* Return if at least one inflate is run */ if (max_work != MAX_WORK) return tp;
到这里说明一次调整都没有发生,说明节点很稀疏,也就是把节点分开。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
/* Halve as long as the number of empty children in this * node is above threshold. */ while (should_halve(tp, tn) && max_work) { tp = halve(t, tn); if (!tp) { #ifdef CONFIG_IP_FIB_TRIE_STATS this_cpu_inc(stats->resize_node_skipped); #endif break; }
max_work--; tn = get_child(tp, cindex); }
只有一个孩子,可以进行 path compress,没必要再多一个中间节点。
1 2 3 4 5 6 7
/* Only one child remains */ if (should_collapse(tn)) return collapse(t, tn);
/* update parent in case halve failed */ return node_parent(tn); }
/* Compare new lladdr with cached one */ if (!dev->addr_len) { /* First case: device needs no address. */ lladdr = neigh->ha; } elseif (lladdr) { /* The second case: if something is already cached and a new address is proposed: - compare new & old - if they are different, check override flag */ if ((old & NUD_VALID) && !memcmp(lladdr, neigh->ha, dev->addr_len)) lladdr = neigh->ha; } else { /* No address is supplied; if we know something, use it, otherwise discard the request. */ err = -EINVAL; if (!(old & NUD_VALID)) goto out; lladdr = neigh->ha; }
如果NUD_CONNECTED 更新 confirm 的时间,更新『更新』的时间。
1 2 3
if (new & NUD_CONNECTED) neigh->confirmed = jiffies; neigh->updated = jiffies;
/* If entry was valid and address is not changed, do not change entry state, if new one is STALE. */ err = 0; update_isrouter = flags & NEIGH_UPDATE_F_OVERRIDE_ISROUTER; if (old & NUD_VALID) { if (lladdr != neigh->ha && !(flags & NEIGH_UPDATE_F_OVERRIDE)) { update_isrouter = 0; if ((flags & NEIGH_UPDATE_F_WEAK_OVERRIDE) && (old & NUD_CONNECTED)) { lladdr = neigh->ha; new = NUD_STALE; } else goto out; } else { if (lladdr == neigh->ha && new == NUD_STALE && !(flags & NEIGH_UPDATE_F_ADMIN)) new = old; } }
如果是更新操作,删除老的 timer,如果需要 timer,更新新的 timer,并且设置新状态。
1 2 3 4 5 6 7 8 9 10 11 12
if (new != old) { neigh_del_timer(neigh); if (new & NUD_PROBE) atomic_set(&neigh->probes, 0); if (new & NUD_IN_TIMER) neigh_add_timer(neigh, (jiffies + ((new & NUD_REACHABLE) ? neigh->parms->reachable_time : 0))); neigh->nud_state = new; notify = 1; }
更新 neigh->ha,如果 lladdr 和 neigh->ha 不同的话。
1 2 3 4 5 6 7 8 9 10 11 12
if (lladdr != neigh->ha) { write_seqlock(&neigh->ha_lock); memcpy(&neigh->ha, lladdr, dev->addr_len); write_sequnlock(&neigh->ha_lock); neigh_update_hhs(neigh); if (!(new & NUD_CONNECTED)) neigh->confirmed = jiffies - (NEIGH_VAR(neigh->parms, BASE_REACHABLE_TIME) << 1); notify = 1; } if (new == old) goto out;
根据状态调用 connect 和 suspect
1 2 3 4
if (new & NUD_CONNECTED) neigh_connect(neigh); else neigh_suspect(neigh);
/* Why not just use 'neigh' as-is? The problem is that * things such as shaper, eql, and sch_teql can end up * using alternative, different, neigh objects to output * the packet in the output path. So what we need to do * here is re-lookup the top-level neigh in the path so * we can reinject the packet there. */ n2 = NULL; if (dst) { n2 = dst_neigh_lookup_skb(dst, skb); if (n2) n1 = n2; } n1->output(n1, skb); if (n2) neigh_release(n2); rcu_read_unlock();
还有就是 VIP,一般的作用是在本地网路中有两台机器,一台作为备机,一台作为主机,当主机 failover 的时候,备机可以继续『冒充』主机的 IP 地址,具体的做法就是主动发送请求,解析的 MAC 和 IP 都和 source 一样,老的 server 肯定不会回答这个 ARP,交换机上已经没有这个端口的缓存,会进行广播,让所有的接收者都会更新自己的缓存。也就是发送了一个一去不复返的请求,让所有的邻居更新了自己的 ARP 缓存,从而替代了老 server 的 IP,这就是 VIP 通过 ARP 实现的 failover。
while (left > 0) { len = left; /* IF: it doesn't fit, use 'mtu' - the data space left */ if (len > mtu) len = mtu; /* IF: we are not sending up to and including the packet end then align the next start on an eight byte boundary */ if (len < left) { len &= ~7; }
/* * Copy a block of the IP datagram. */ if (skb_copy_bits(skb, ptr, skb_transport_header(skb2), len)) BUG(); left -= len;
设置 IP 头的偏移和分片标志。
1 2 3 4 5 6 7 8
/* * Fill in the new header fields. */ iph = ip_hdr(skb2); iph->frag_off = htons((offset >> 3));
if (IPCB(skb)->flags & IPSKB_FRAG_PMTU) iph->frag_off |= htons(IP_DF);
如果是第一个分片就尝试更新 IP options。
1 2 3 4 5 6 7 8
/* ANK: dirty, but effective trick. Upgrade options only if * the segment to be fragmented was THE FIRST (otherwise, * options are already fixed) and make it ONCE * on the initial skb, so that all the following fragments * will inherit fixed options. */ if (offset == 0) ip_options_fragment(skb);
/* * Added AC : If we are fragmenting a fragment that's not the * last fragment then keep MF on each bit */ if (left > 0 || not_last_frag) iph->frag_off |= htons(IP_MF); ptr += len; offset += len;
/* * Put this fragment into the sending queue. */ iph->tot_len = htons(len + hlen);
/* Determine the position of this fragment. */ end = offset + skb->len - skb_network_offset(skb) - ihl; err = -EINVAL;
如果是最后一个 fragment,那么不应该超过 q.len,或者已经有了最后一个了,但是 end 和 q.len 不一致,所以有一些 corruption。如果检查没问题,就更新q.flasg 标记为最后一个和把 end 赋值给q.len。
1 2 3 4 5 6 7 8 9 10 11
/* Is this the final fragment? */ if ((flags & IP_MF) == 0) { /* If we already have some bits beyond end * or have different end, the segment is corrupted. */ if (end < qp->q.len || ((qp->q.flags & INET_FRAG_LAST_IN) && end != qp->q.len)) goto err; qp->q.flags |= INET_FRAG_LAST_IN; qp->q.len = end;
如果不是最后一个,长度要与 8 对齐,然后更新 q.len。
1 2 3 4 5 6 7 8 9 10 11 12 13
} else { if (end&7) { end &= ~7; if (skb->ip_summed != CHECKSUM_UNNECESSARY) skb->ip_summed = CHECKSUM_NONE; } if (end > qp->q.len) { /* Some bits beyond end -> corruption. */ if (qp->q.flags & INET_FRAG_LAST_IN) goto err; qp->q.len = end; }
err = -ENOMEM; if (!pskb_pull(skb, skb_network_offset(skb) + ihl)) goto err;
err = pskb_trim_rcsum(skb, end - offset); if (err) goto err;
/* Find out which fragments are in front and at the back of us * in the chain of fragments so far. We must know where to put * this fragment, right? */ prev = qp->q.fragments_tail; if (!prev || FRAG_CB(prev)->offset < offset) { next = NULL; goto found; } prev = NULL; for (next = qp->q.fragments; next != NULL; next = next->next) { if (FRAG_CB(next)->offset >= offset) break; /* bingo! */ prev = next; }
如果和前面的分组有重叠,就把重叠的部分去掉,CHECKSUM_NONE 可以使当前的校验和失效。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
if (prev) { int i = (FRAG_CB(prev)->offset + prev->len) - offset;
if (i > 0) { offset += i; err = -EINVAL; if (end <= offset) goto err; err = -ENOMEM; if (!pskb_pull(skb, i)) goto err; if (skb->ip_summed != CHECKSUM_UNNECESSARY) skb->ip_summed = CHECKSUM_NONE; } }
然后向后检查有没有重叠,并且把重叠的部分去掉,如果重叠的部分比 next 本身还要大,直接把 next 删掉。
while (next && FRAG_CB(next)->offset < end) { int i = end - FRAG_CB(next)->offset; /* overlap is 'i' bytes */
if (i < next->len) { /* Eat head of the next overlapped fragment * and leave the loop. The next ones cannot overlap. */ if (!pskb_pull(next, i)) goto err; FRAG_CB(next)->offset += i; qp->q.meat -= i; if (next->ip_summed != CHECKSUM_UNNECESSARY) next->ip_summed = CHECKSUM_NONE; break; } else { struct sk_buff *free_it = next;
/* Old fragment is completely overridden with * new one drop it. */ next = next->next;
if (prev) prev->next = next; else qp->q.fragments = next;
/* When the interface is in promisc. mode, drop all the crap * that it receives, do not try to analyse it. */ // 如果 L2 地址不是本机地址 pkt_type 就会被设置成 PACKET_OHTERHOST // 然后进行丢包 if (skb->pkt_type == PACKET_OTHERHOST) goto drop;
/* * RFC1122: 3.2.1.2 MUST silently discard any IP frame that fails the checksum. * * Is the datagram acceptable? * * 1. Length at least the size of an ip header * 2. Version of 4 * 3. Checksums correctly. [Speed optimisation for later, skip loopback checksums] * 4. Doesn't have a bogus length */ // ip 头部长度至少 20 个字节 if (iph->ihl < 5 || iph->version != 4) goto inhdr_error;
/* Our transport medium may have padded the buffer out. Now we know it * is IP we can trim to the true length of the frame. * Note this now means skb->len holds ntohs(iph->tot_len). */ if (pskb_trim_rcsum(skb, len)) { __IP_INC_STATS(net, IPSTATS_MIB_INDISCARDS); goto drop; }
/* if ingress device is enslaved to an L3 master device pass the * skb to its handler for processing */ skb = l3mdev_ip_rcv(skb); if (!skb) return NET_RX_SUCCESS;
如果设置了 ip_early_demux 并且不是分片的 IP 包,就会提前调用 TCP 的 early_demux 提前解复用这个包。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
if (net->ipv4.sysctl_ip_early_demux && !skb_dst(skb) && !skb->sk && !ip_is_fragment(iph)) { conststructnet_protocol *ipprot; int protocol = iph->protocol;
ipprot = rcu_dereference(inet_protos[protocol]); if (ipprot && (edemux = READ_ONCE(ipprot->early_demux))) { edemux(skb); /* must reload iph, skb->head might have changed */ iph = ip_hdr(skb); } }
/* * Initialise the virtual path cache for the packet. It describes * how the packet travels inside Linux networking. */ if (!skb_valid_dst(skb)) { int err = ip_route_input_noref(skb, iph->daddr, iph->saddr, iph->tos, dev); if (unlikely(err)) { if (err == -EXDEV) __NET_INC_STATS(net, LINUX_MIB_IPRPFILTER); goto drop; } }
if (ip_options_compile(dev_net(dev), opt, skb)) { __IP_INC_STATS(dev_net(dev), IPSTATS_MIB_INHDRERRORS); goto drop; }
in_device 是和 IP 有关的设备信息,如果没有 source route 选项就直接跳过,不然处理 source route 选项。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
if (unlikely(opt->srr)) { structin_device *in_dev = __in_dev_get_rcu(dev);
if (in_dev) { if (!IN_DEV_SOURCE_ROUTE(in_dev)) { if (IN_DEV_LOG_MARTIANS(in_dev)) net_info_ratelimited("source route option %pI4 -> %pI4\n", &iph->saddr, &iph->daddr); goto drop; } }
if (ip_options_rcv_srr(skb)) goto drop; }
source route 是一个多字节选项。此选项中,发送节点会列出后续几跳的 IP 地址(不能超过 IP 报头的最大长度)。如果列表中有某台主机宕机了,则必须重新计算来源地路由,重新发送,而不是使用动态路由。ip_options_rcv_srr 的具体工作就是根据提取出的目的地在本地计算目的地是否可达,如果成功就反回 0, 不然就丢弃。
/* RFC 1122 3.3.6: * * When a host sends a datagram to a link-layer broadcast * address, the IP destination address MUST be a legal IP * broadcast or IP multicast address. * * A host SHOULD silently discard a datagram that is received * via a link-layer broadcast (see Section 2.4) but does not * specify an IP multicast or broadcast destination address. * * This doesn't explicitly say L2 *broadcast*, but broadcast is * in a way a form of multicast and the most common use case for * this is 802.11 protecting against cross-station spoofing (the * so-called "hole-196" attack) so do it for both. */ if (in_dev && IN_DEV_ORCONF(in_dev, DROP_UNICAST_IN_L2_MULTICAST)) goto drop; }
return dst_input(skb);
进入 dst_input 就会交给 skb>dst >input 来处理。
转发会分成两部分处理 ip_forward 和 ip_forward_finish IP 转发分成几个步骤
处理 IP options,可能会要求记录本地 IP 地址和时间戳
基于 IP 头,确保这个 pakcet 可以发出去
减 1 TTL,到达 0 就丢弃
根据 MTU 进行分组
发送至出口设备
期间如果出错了,会通过 ICMP 告知。xfrm4_xxx 是 IPsec 相关的函数。
1 2
if (IPCB(skb)->opt.router_alert && ip_call_ra_chain(skb)) return NET_RX_SUCCESS;
首先是检查 IP 选项当中有没有 Router Alert,如果有的话就交给 ip_ra_chain 中对此感兴趣的 raw socket 来处理,并且就次结束。
在这里检查 TTL 是否耗尽
1 2 3
if (ip_hdr(skb)->ttl <= 1) goto too_many_hops;
如果是严格的源路由,下一条是网关而不是直接连接的路由就丢包。
rt_uses_gateway 代表两种意思
1 的时候表示网关
0 的时候表示直接路由
1 2 3
if (opt->is_strictroute && rt->rt_uses_gateway) goto sr_failed;
如果超出 MTU 进行丢包
1 2 3 4 5 6 7 8 9
IPCB(skb)->flags |= IPSKB_FORWARDED; mtu = ip_dst_mtu_maybe_forward(&rt->dst, true); if (ip_exceeds_mtu(skb, mtu)) { IP_INC_STATS(net, IPSTATS_MIB_FRAGFAILS); icmp_send(skb, ICMP_DEST_UNREACH, ICMP_FRAG_NEEDED, htonl(mtu)); goto drop; }
declone 这个 skb 并且确保预留 L2 的空间,然后减少 TTL。
1 2 3 4 5 6 7 8
/* We are about to mangle packet. Copy it! */ if (skb_cow(skb, LL_RESERVED_SPACE(rt->dst.dev)+rt->dst.header_len)) goto drop; iph = ip_hdr(skb);
/* Decrease ttl after skb cow done */ ip_decrease_ttl(iph);
如果被标记为 IPSKB_DOREDIRECT 发送 redirect ICMP,接着设置优先级。
1 2 3 4 5 6 7 8 9 10
/* * We now generate an ICMP HOST REDIRECT giving the route * we calculated. */ if (IPCB(skb)->flags & IPSKB_DOREDIRECT && !opt->srr && !skb_sec_path(skb)) ip_rt_send_redirect(skb);
/* Use correct destination address if we have options. */ daddr = inet->inet_daddr; if (inet_opt && inet_opt->opt.srr) daddr = inet_opt->opt.faddr;
/* If this fails, retransmit mechanism of transport layer will * keep trying until route appears or the connection times * itself out. */ rt = ip_route_output_ports(net, fl4, sk, daddr, inet->inet_saddr, inet->inet_dport, inet->inet_sport, sk->sk_protocol, RT_CONN_FLAGS(sk), sk->sk_bound_dev_if); if (IS_ERR(rt)) goto no_route; sk_setup_caps(sk, &rt->dst); } skb_dst_set_noref(skb, &rt->dst);
接下来就需要构建 IP 头了,先调用空出需要的 IP 头部空间,并且重置我的大脑。
1 2
/* OK, we know where to send it, allocate and build IP header. */ skb_push(skb, sizeof(struct iphdr) + (inet_opt ? inet_opt->opt.optlen : 0));
/* * transhdrlen > 0 means that this is the first fragment and we wish * it won't be fragmented in the future. */ if (transhdrlen && length + fragheaderlen <= mtu && rt->dst.dev->features & (NETIF_F_HW_CSUM | NETIF_F_IP_CSUM) && !(flags & MSG_MORE) && !exthdrlen) csummode = CHECKSUM_PARTIAL;
下面如果满足下面条件就进入 UDP Fragment Offload 例程。是硬件网卡提供的一种特性,由内核和驱动配合完成相关功能。其目的是由网卡硬件来完成本来需要软件进行的分段(分片)操作用于提升效率和性能。如大家所知,在网络上传输的数据包不能大于 mtu,当用户发送大于 mtu 的数据报文时,通常会在传输层(或者在特殊情况下在 IP 层分片,比如 ip 转发或 ipsec 时)就会按 mtu 大小进行分段,防止发送出去的报文大于 mtu,为提升该操作的性能,新的网卡硬件基本都实现了 UFO 功能,可以使分段(或分片)操作在网卡硬件完成,此时用户态就可以发送长度大于 mtu 的包,而且不必在协议栈中进行分段(或分片)。如果硬件支持,是 UDP 协议,并且是大于 mtu 的可以直接用这个函数。
/* * If remaining data exceeds the mtu, * we know we need more fragment(s). */ datalen = length + fraggap; if (datalen > mtu - fragheaderlen) datalen = maxfraglen - fragheaderlen; fraglen = datalen + fragheaderlen;
/* The last fragment gets additional space at tail. * Note, with MSG_MORE we overallocate on fragments, * because we have no idea what fragment will be * the last. */ if (datalen == length + fraggap) alloclen += rt->dst.trailer_len;
/* * Fill in the control structures */ skb->ip_summed = csummode; skb->csum = 0; skb_reserve(skb, hh_len);
设置 tx_flags 和 tskey
1 2 3 4 5 6
/* only the initial fragment is time stamped */ skb_shinfo(skb)->tx_flags = cork->tx_flags; cork->tx_flags = 0; skb_shinfo(skb)->tskey = tskey; tskey = 0;
保留数据空间,并且把指针移动到头部后面,指向负载的部分。
1 2 3 4 5 6 7
* Find where to start putting bytes. */ data = skb_put(skb, fraglen + exthdrlen); skb_set_network_header(skb, exthdrlen); skb->transport_header = (skb->network_header + fragheaderlen); data += fragheaderlen + exthdrlen;
这部分就是把上个 skb 的 fraggap 移到当前这个,并且重新获取 checksum。
1 2 3 4 5 6 7 8 9 10
if (fraggap) { skb->csum = skb_copy_and_csum_bits( skb_prev, maxfraglen, data + transhdrlen, fraggap, 0); skb_prev->csum = csum_sub(skb_prev->csum, skb->csum); data += fraggap; pskb_trim_unique(skb_prev, maxfraglen); }
接下来调用 getfrag 拷贝数据,加入到队尾。
getfrag 对应的 4 个 routine 分别是
ICMP icmp_glue_bits
UDP. ip_generic_getfrag
RAW iP ip_generic_getfrag
TCP. Ip_reply_glue_bits
getfrag 的功能就是从 from 拷贝到 to ,因为可能是用户态的数据,所以包含了地址转换的功能并且在比好的时候重新计算校验和。
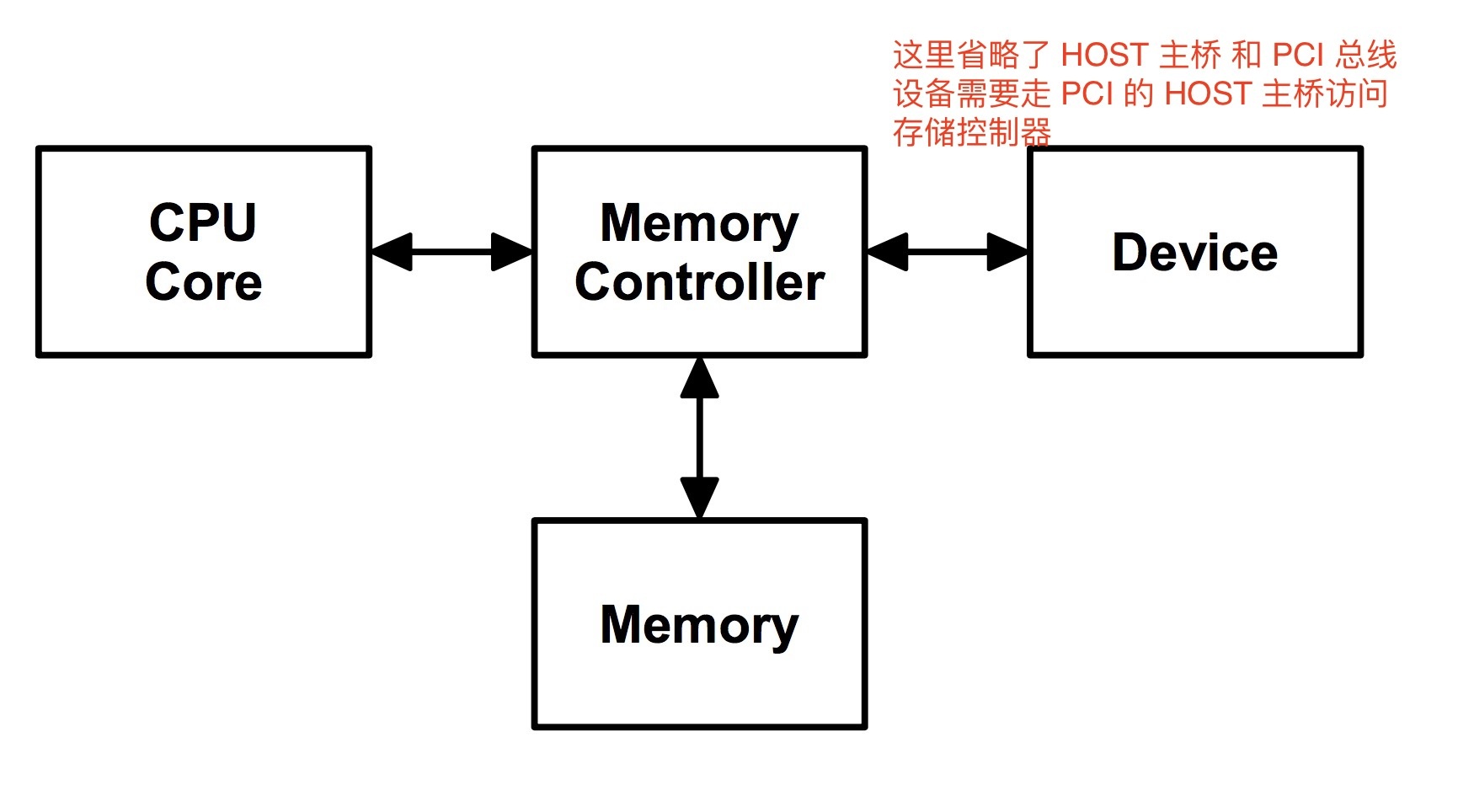
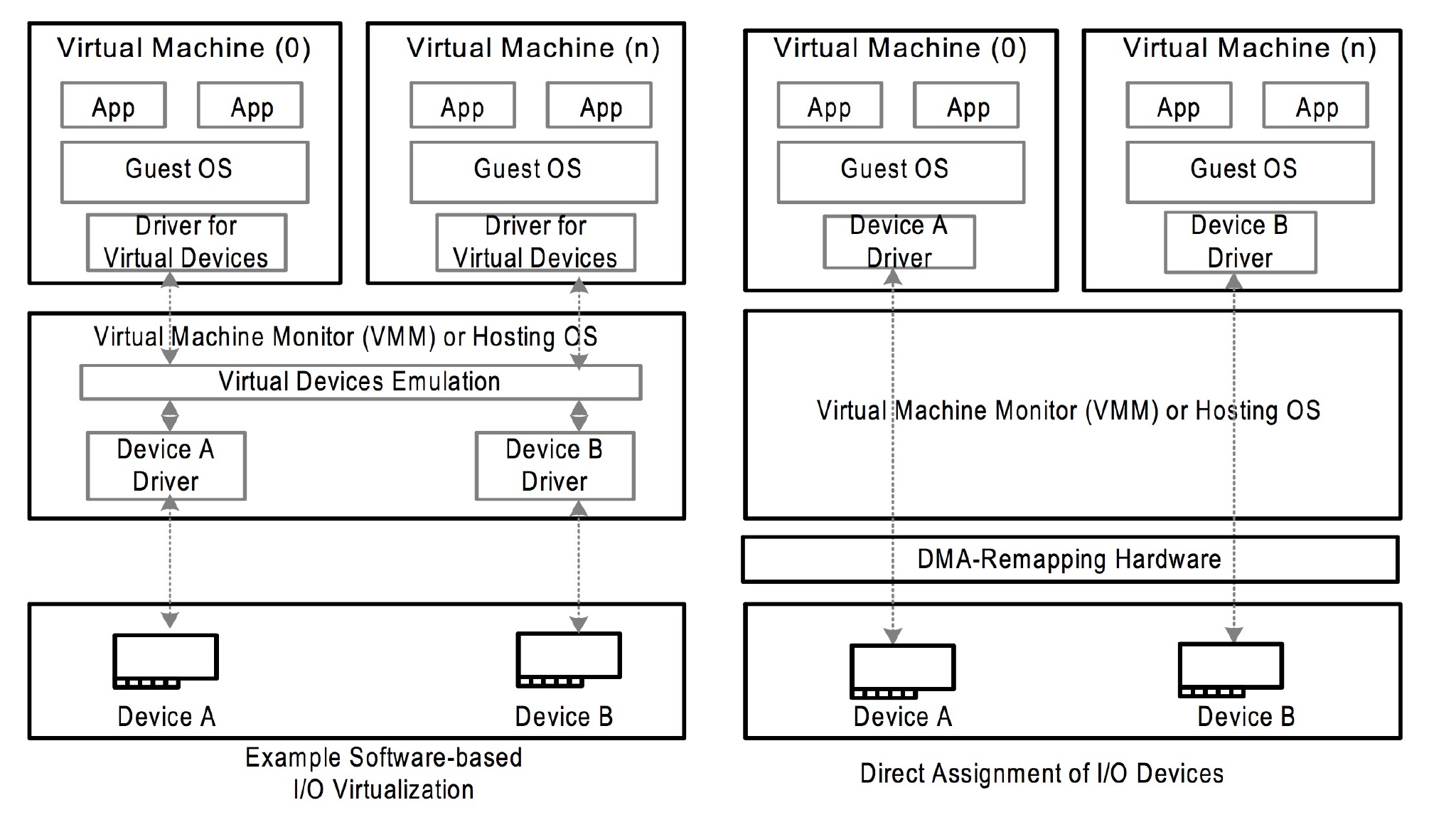
这是一个比较简单的体系结构图,设备 和 CPU 通过存储控制器访问存储器。一个简单的 case 是 CPU 向存储器写数据,然后设备从存储器读数据。这么快来一切都很正常。但是实际上 CPU 是有一层缓存的,例如下面这样的。
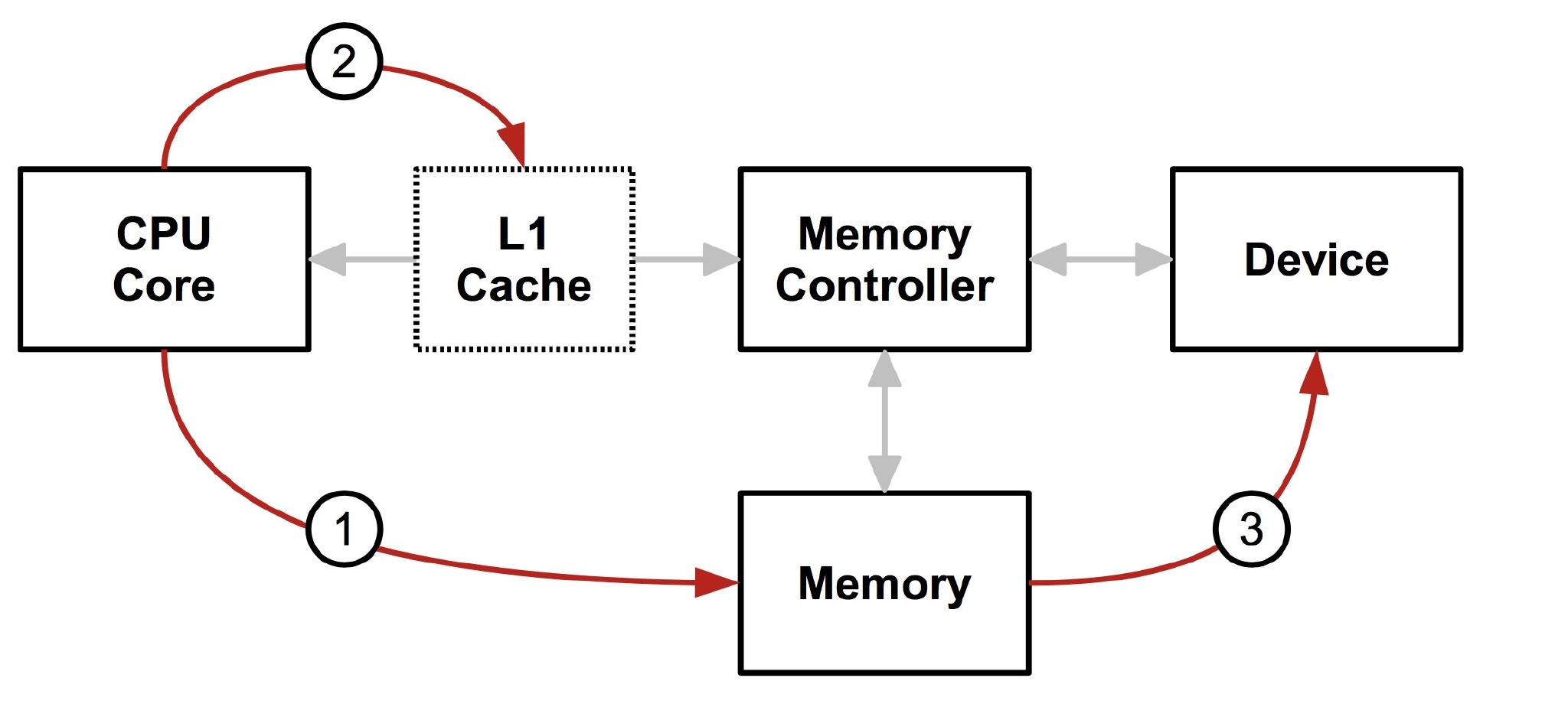
CPU 想内存写数据,但是先要清空到不一致的缓存,然后设备再去读数据,不然设备读到的数据和 CPU 实际的数据会不一致(因为缓存里的数据可能和存储器的不一致),而且实际上缓存也不只是一层,所以需要一个中间层来保证 从 CPU 的角度和从设备的角度内存都是一致的,所以就有了下面这个结构。
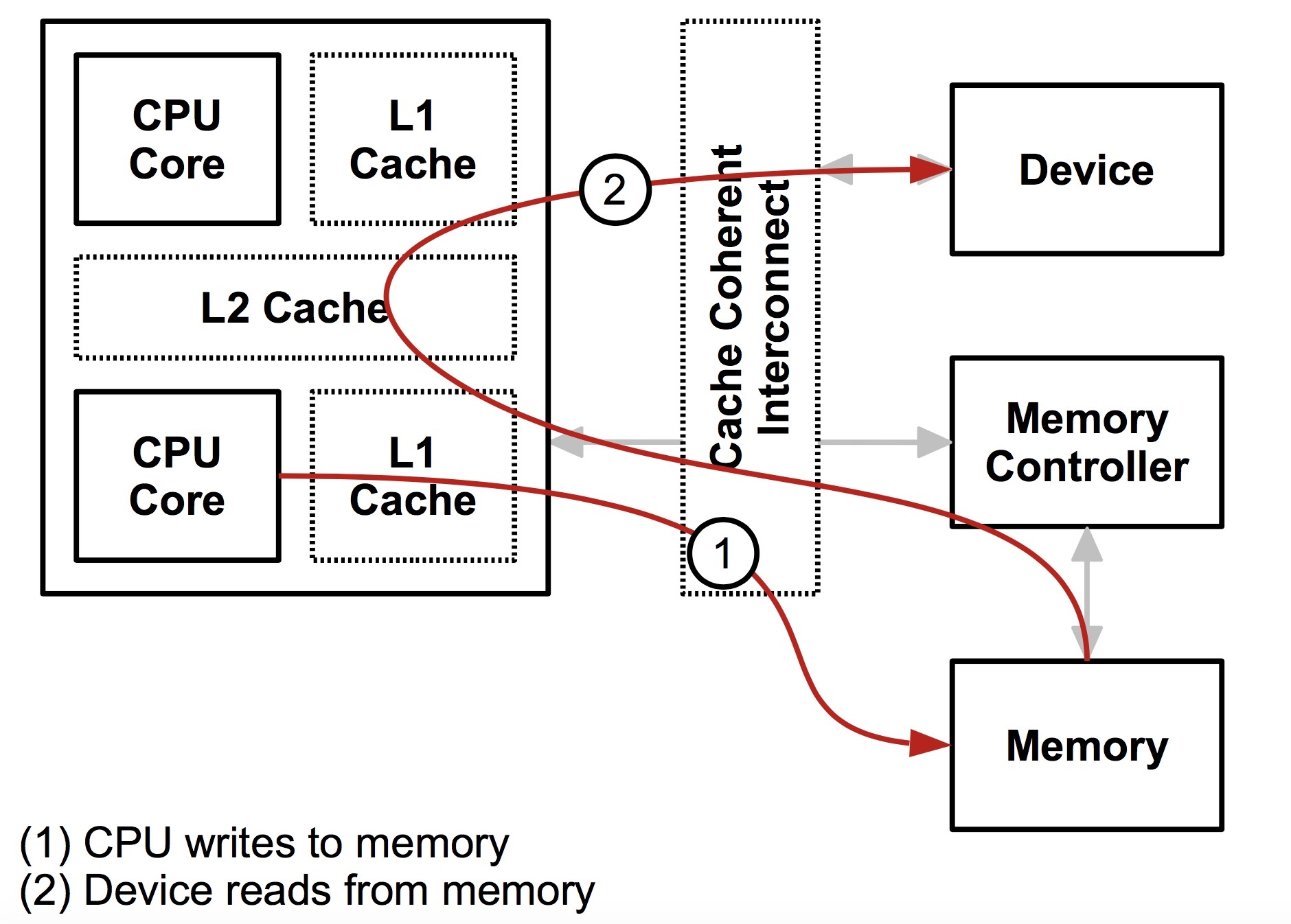
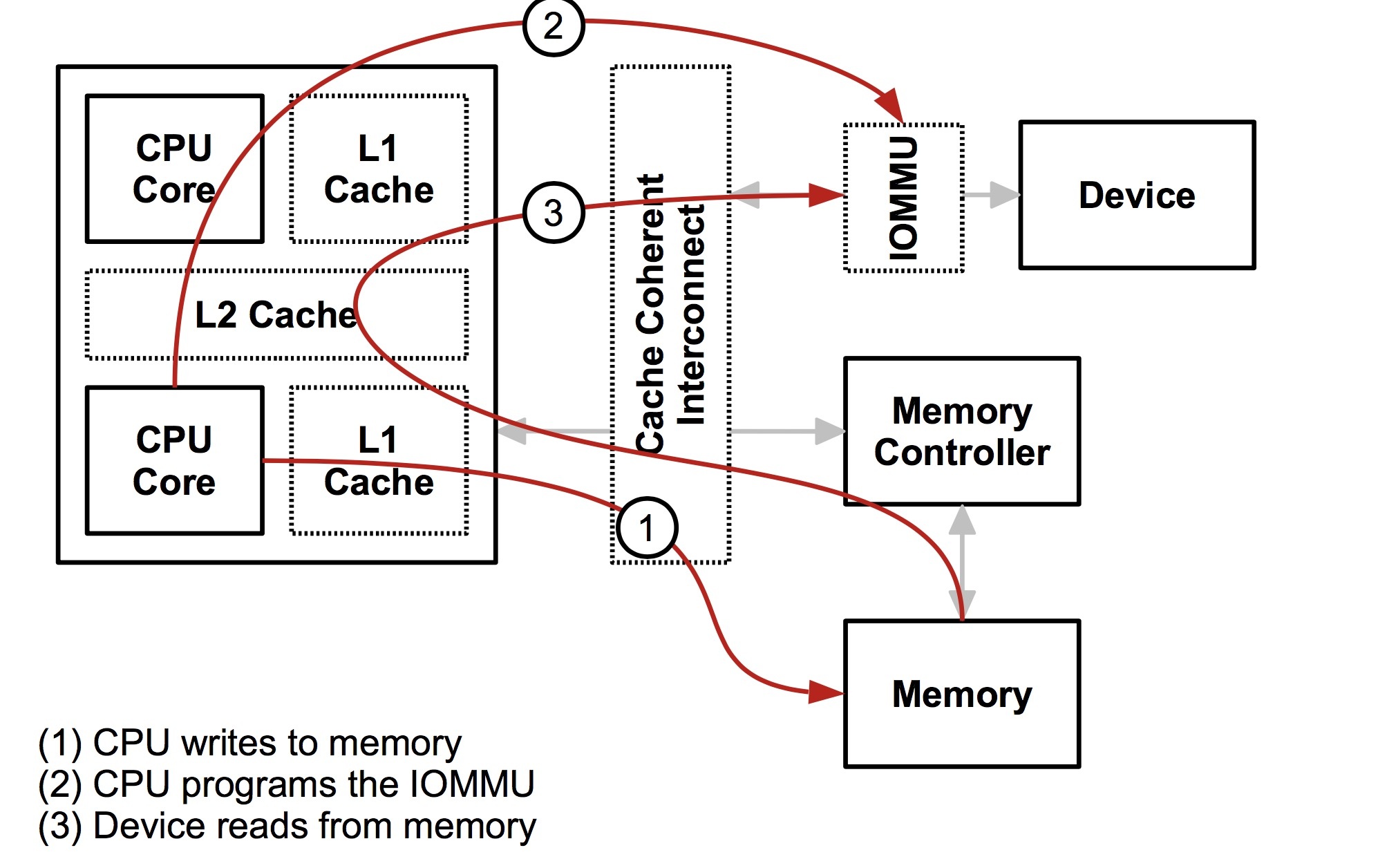
CPU 和 设备都会走缓存验证一遍以后,再落到存储器上,这样带上缓存以后大家的一致性都是一样的了。所以从设备的角度,设备也拥有了缓存,实际上这个和 IOMMU 关系不是很大,接下来设备其实也可以和 CPU 一样有一层 MMU,也就是地址到存储器物理地址的转换。注意,这里我用了地址,因为对 CPU 来说是虚拟地址,但是对设备来说是一个总线域的地址。这里要明确区分一下,一个是总线地址,是从设备的角度来看的,一个是 CPU 的虚拟地址,这是从 CPU 角度来看的,两个是不同的东西。将总线域地址转换成存储器物理地址的设备就叫 IOMMU。
通过打开/dev/vfio/vfio就能创建一个 VFIO 的 container,然后再打开/dev/vfio/$GROUP用VFIO_GROUP_SET_CONTAINER ioctl 把文件描述传进去,就把 group 加进去了,如果支持多个 group 共享页表等结构,还可以把相应的 group 也加进去。(再强调一遍这个页表是总线地址到存储器物理地址,IOMMU 管理的那个页表)。
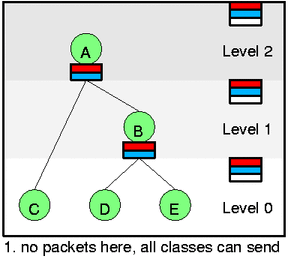
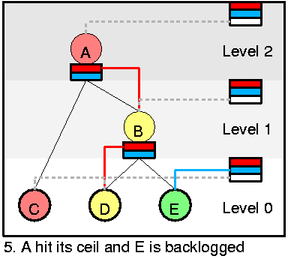
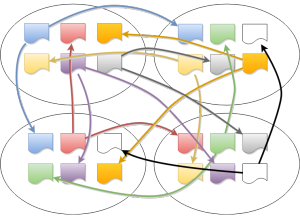
每个 class 有个 slot 包含不同的 prio 级别,指向 yellow 的子节点,然后每个层级包含一个 slot 也有不同的 prio 级别指向这一层中 green 的节点,上图展示了的是有两个 prio 的 slot,右边的 self slot 有个白色的是用于 yellow red 的 wait list。
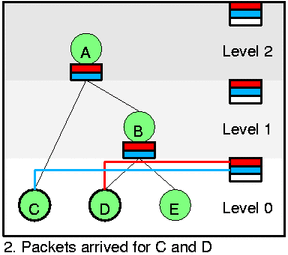
假设当前如图 1 的状态,所有节点都是绿的没有 packet 到来,现在有有两个包到达 C 和 D,然后激活它们,并且它们现在都是绿的,所以 self slot 指向他们,然后因为 D 的优先级更高,所以先把 D 出队。所以你可以发现,出队的顺序很简答,就是按照优先级从 self slot 里面把绿色的包按顺序取出来就可以。
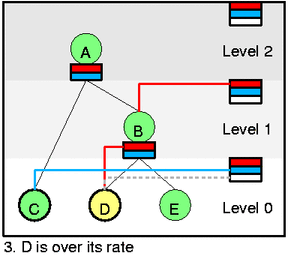
然后我们看一下更复杂的情况,在图 3 中,我们从 D 中出队一个 packet(htb_dequeue),然后htb_charge_class会增加 D 的速率,导致 D 变成 yellow,离开 self slot (通过htb_deactivate_prios和htb_remove_class_from_row),然后添加到 B 的 slot 里面 (htb_activate_prios),并且递归向上添加htb_add_class_to_row,D 会在一段时间后进入 self slot 的白色等待区,然后 D 又会变回绿色。现在如果选择的话,就会从 C 出队,因为虽然 C 的优先级低但是 C 不需要借别人的速率。
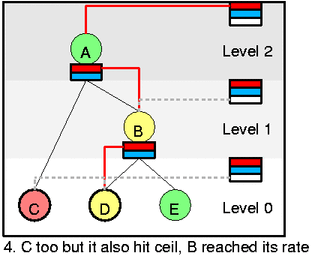
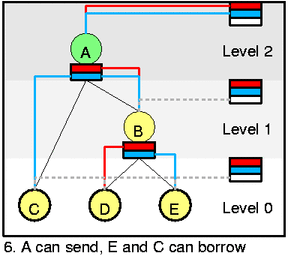
在图 4,假设 C 已经完全消耗了速率达到了最大限速,这个时候 D 就会开始工作然后把 B 消耗完,B 被消耗了以后就会去消耗 A,从这里就可以看到一个借取的过程。
现在说一个更复杂一点的例子,在图 5 中,A 已经被消耗光了,E 开始工作,然后 C 也能开始工作,变成图 6 的样子。注意即使 D 没有被使用但是他的优先级还会被 class slot 维持,也就是红线。但是 C 和 E 都是同一个优先级,这样的话,就要使用 DRR 算法(也就是在 RR 算法上给每个变量加一个权重,也就是之前的那个量子 quantom)。然后也可以发现一个 class 可以对不同的优先级(红色和蓝色)保持 active。
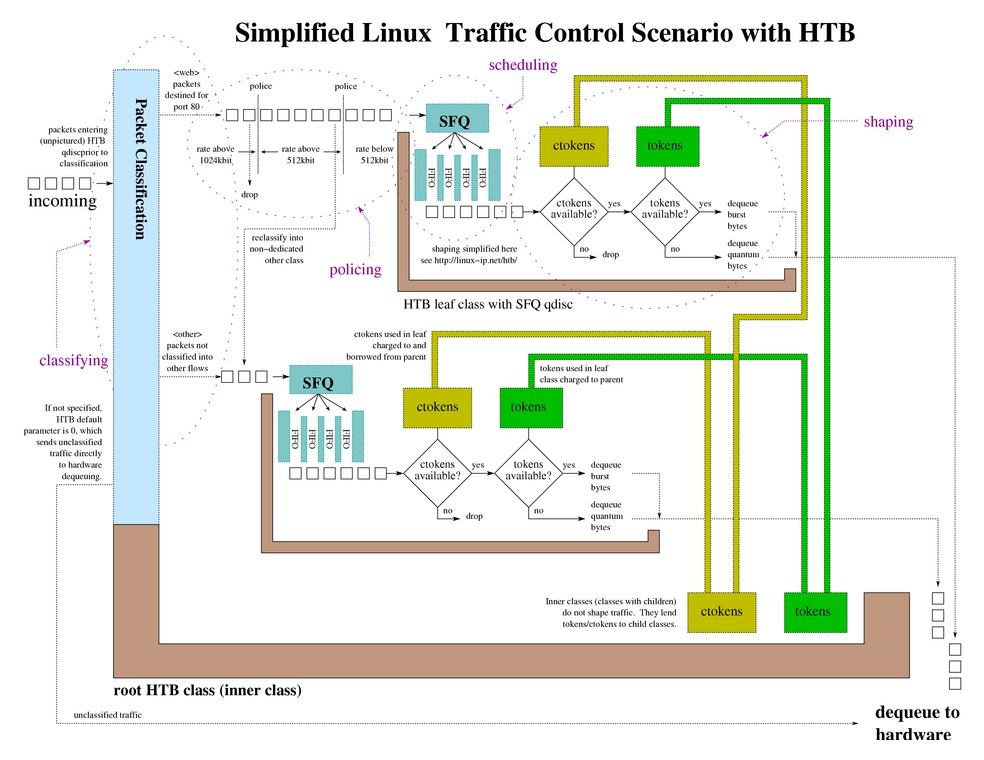
下面是一个 HTB 的全貌图,抽象的可以理解成一个从父 class 中根据优先级带权重的分享令牌的一个算法。
下面三个值对应的就是三种颜色。
1 2 3 4 5 6
/* used internaly to keep status of single class */ enum htb_cmode { HTB_CANT_SEND, /* class can't send and can't borrow */ HTB_MAY_BORROW, /* class can't send but may borrow */ HTB_CAN_SEND /* class can send */ };
struct htb_sched { struct Qdisc_class_hash clhash; int defcls; /* class where unclassified flows go to */ int rate2quantum; /* quant = rate / rate2quantum */
/* filters for qdisc itself */ struct tcf_proto __rcu *filter_list;
#define HTB_WARN_TOOMANYEVENTS 0x1 unsigned int warned; /* only one warning */ int direct_qlen; struct work_struct work;
/* non shaped skbs; let them go directly thru */ struct qdisc_skb_head direct_queue; long direct_pkts;
struct qdisc_watchdog watchdog;
s64 now; /* cached dequeue time */ struct list_head drops[TC_HTB_NUMPRIO];/* active leaves (for drops) */
/* time of nearest event per level (row) */ s64 near_ev_cache[TC_HTB_MAXDEPTH];
cgroup 是容器当中对资源进行限制的机制,完整的名称是叫 control group。经常提到的 hierarchy 对应的是一个层级,而subsystem 对应的是一个子系统,都是可以望文生意的。创建一个层级是通过挂载完成的,也就是说层级对应的是文件系统 root 目录的结构。
子系统目前有下列几种
devices 设备权限
cpuset 分配指定的 CPU 和内存节点
cpu 控制 CPU 占用率
cpuacct 统计 CPU 使用情况
memory 限制内存的使用上限
freezer 暂停 Cgroup 中的进程
net_cls 配合 tc(traffic controller)限制网络带宽
net_prio 设置进程的网络流量优先级
huge_tlb 限制 HugeTLB 的使用
perf_event 允许 Perf 工具基于 Cgroup 分组做性能检测
创建层级通过 mount -t cgroup -o subsystems name /cgroup/name,/cgroup/name 是用来挂载层级的目录(层级结构是通过挂载添加的),-o 是子系统列表,比如 -o cpu,cpuset,memory,name 是层级的名称,一个层级可以包含多个子系统,如果要修改层级里的子系统重新 mount 即可。子系统和层级之间满足几个关系。
/proc/[pid]/cgroup (since Linux 2.6.24) This file describes control groups to which the process/task belongs. For each cgroup hierarchy there is one entry containing colon-separated fields of the form:
5:cpuacct,cpu,cpuset:/daemons
The colon-separated fields are, from left to right:
1. hierarchy ID number
2. set of subsystems bound to the hierarchy
3. control group in the hierarchy to which the process belongs
This file is present only if the CONFIG_CGROUPS kernel configuration option is enabled.
这个展示的是当前进程属于的 control groups, 每一行是一排 hierarchy,中间是子系统,最后是受控制的 cgroup,可以通过这个文件知道自己所属于的cgroup。
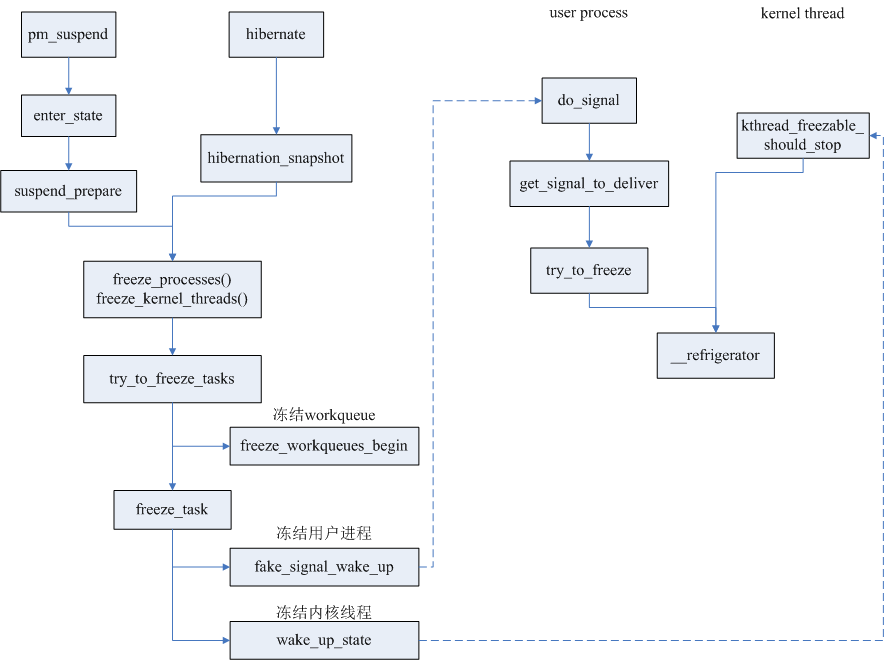
/* Refrigerator is place where frozen processes are stored :-). */ void refrigerator(void) { /* Hmm, should we be allowed to suspend when there are realtime processes around? */ long save;
task_lock(current); if (freezing(current)) { frozen_process(); task_unlock(current); } else { task_unlock(current); return; } save = current->state; pr_debug("%s entered refrigerator\n", current->comm); spin_lock_irq(¤t->sighand->siglock); recalc_sigpending(); /* We sent fake signal, clean it up */ spin_unlock_irq(¤t->sighand->siglock); /* prevent accounting of that task to load */ current->flags |= PF_FREEZING; for (;;) { set_current_state(TASK_UNINTERRUPTIBLE); if (!frozen(current)) break; schedule(); }
/* Remove the accounting blocker */ current->flags &= ~PF_FREEZING;
pr_debug("%s left refrigerator\n", current->comm); __set_current_state(save); }
if (!cgroup_lock_live_group(cgroup)) return -ENODEV;
freezer = cgroup_freezer(cgroup); spin_lock_irq(&freezer->lock); state = freezer->state; if (state == CGROUP_FREEZING) { /* We change from FREEZING to FROZEN lazily if the cgroup was * only partially frozen when we exitted write. */ update_freezer_state(cgroup, freezer); state = freezer->state; } spin_unlock_irq(&freezer->lock); cgroup_unlock();
bool freeze_task(struct task_struct *p, bool sig_only) { /* * We first check if the task is freezing and next if it has already * been frozen to avoid the race with frozen_process() which first marks * the task as frozen and next clears its TIF_FREEZE. */ if (!freezing(p)) { rmb(); /* 如果frozen标记了 * 说明已经冻结,就返回失败 */ if (frozen(p)) return false;
if (!sig_only || should_send_signal(p)) set_freeze_flag(p); else return false; }
if (should_send_signal(p)) { if (!signal_pending(p)) fake_signal_wake_up(p); } else if (sig_only) { return false; } else { wake_up_state(p, TASK_INTERRUPTIBLE); }
Linux is a multi-user operating system. Consider a scenario where user A spawns ten tasks and user B spawns five. Using the above approach, every task would get ~7% of the available CPU time within a scheduling period. So user A gets 67% and user B gets 33% of the CPU time during their runs. Clearly, if user A continues to spawn more tasks, he can starve user B of even more CPU time. To address this problem, the concept of “group scheduling” was introduced in the scheduler, where, instead of dividing the CPU time among tasks, it is divided among groups of tasks.
总结来说 CPU 的时间并不是分给独立的 task 的,而是分给 task_group 的,这样防止用户 A 的进程数远远大于 B 而导致 B 饥饿的情况。这一组task通过 sched_entity 来表示。能够导致进程分组的方式一种是把进程划入一个cgroup,一种是通过set_sid()系统调用的新session中创建的进程会自动分组,这需要CONFIG_SCHED_AUTOGROUP编译选项开启。
#ifdef CONFIG_FAIR_GROUP_SCHED struct sched_entity *parent; /* rq on which this entity is (to be) queued: */ struct cfs_rq *cfs_rq; /* rq "owned" by this entity/group: */ struct cfs_rq *my_q; #endif };
每个调度实体都有两个cfs_rq结构
1 2 3 4 5 6 7
struct cfs_rq { struct load_weight load; unsigned long runnable_load_avg; unsigned long blocked_load_avg; unsigned long tg_load_contrib; /* ... */ };
Each scheduling entity may, in turn, be queued on a parent scheduling entity’s run queue. At the lowest level of this hierarchy, the scheduling entity is a task; the scheduler traverses this hierarchy until the end when it has to pick a task to run on the CPU.
Tasks belonging to a group can be scheduled on any CPU. Therefore it is not sufficient for a group to have a single scheduling entity; instead, every group must have one scheduling entity for each CPU. Tasks belonging to a group must move between the run queues in these per-CPU scheduling entities only, so that the footprint of the task is associated with the group even during task migrations.
对于cpu.cfs_period_us和cpu.cfs_quota_us,是关于CPU bandwith的内容,论文CPU bandwidth control for CFS详细描述了其中的设计。论文中举例提到,shares 值只是使得CPU 的时间能够平均分配,但是实际运行时间可能会有变化,不能限制一个进程运行的上限。
/* track cpu usage of a group of tasks and its child groups */ struct cpuacct { struct cgroup_subsys_state css; /* cpuusage holds pointer to a u64-type object on every cpu */ u64 __percpu *cpuusage; struct kernel_cpustat __percpu *cpustat; };
/* * charge this task's execution time to its accounting group. * * called with rq->lock held. */ void cpuacct_charge(struct task_struct *tsk, u64 cputime) { struct cpuacct *ca; int cpu; /* 获取当前task属于的cpu */ cpu = task_cpu(tsk);
/* * Add user/system time to cpuacct. * * Note: it's the caller that updates the account of the root cgroup. */ void cpuacct_account_field(struct task_struct *p, int index, u64 val) { struct kernel_cpustat *kcpustat; struct cpuacct *ca;
rcu_read_lock(); ca = task_ca(p); while (ca != &root_cpuacct) { kcpustat = this_cpu_ptr(ca->cpustat); kcpustat->cpustat[index] += val; ca = __parent_ca(ca); } rcu_read_unlock(); }
struct cpuset { struct cgroup_subsys_state css; unsigned long flags; /* "unsigned long" so bitops work */ cpumask_var_t cpus_allowed; /* CPUs allowed to tasks in cpuset */ nodemask_t mems_allowed; /* Memory Nodes allowed to tasks */ struct fmeter fmeter; /* memory_pressure filter */ /* * Tasks are being attached to this cpuset. Used to prevent * zeroing cpus/mems_allowed between ->can_attach() and ->attach(). */ int attach_in_progress; /* partition number for rebuild_sched_domains() */ int pn; /* for custom sched domain */ int relax_domain_level; struct work_struct hotplug_work; };
Setting the flag ‘cpuset.memory_spread_page’ turns on a per-process flag PFA_SPREAD_PAGE for each task that is in that cpuset or subsequently joins that cpuset. The page allocation calls for the page cache is modified to perform an inline check for this PFA_SPREAD_PAGE task flag, and if set, a call to a new routine cpuset_mem_spread_node() returns the node to prefer for the allocation.
Similarly, setting ‘cpuset.memory_spread_slab’ turns on the flag PFA_SPREAD_SLAB, and appropriately marked slab caches will allocate pages from the node returned by cpuset_mem_spread_node().
/* * The caller (fork, wakeup) owns p->pi_lock, ->cpus_allowed is stable. */ static inline int select_task_rq(struct task_struct *p, int sd_flags, int wake_flags) { int cpu = p->sched_class->select_task_rq(p, sd_flags, wake_flags); /* * In order not to call set_task_cpu() on a blocking task we need * to rely on ttwu() to place the task on a valid ->cpus_allowed * cpu. * * Since this is common to all placement strategies, this lives here. * * [ this allows ->select_task() to simply return task_cpu(p) and * not worry about this generic constraint ] */ if (unlikely(!cpumask_test_cpu(cpu, tsk_cpus_allowed(p)) || !cpu_online(cpu))) cpu = select_fallback_rq(task_cpu(p), p);
简单说一下[sched_domain](https://www.ibm.com/developerworks/cn/linux/l-cn-schldom/ sched domain 的详细内容)的作用,其实就是划定了负载均衡的 CPU 范围,默认是有一个全局的sched_domain,对所有 CPU 做负载均衡的,现在再划分出一个sched_domain把 CPU 的某个子集作为负载均衡的单元。 每个 Scheduling Domain 其实就是具有相同属性的一组 CPU 的集合. 并且跟据 Hyper-threading, Multi-core, SMP, NUMA architectures 这样的系统结构划分成不同的级别,不同级之间通过指针链接在一起, 从而形成一种的树状的关系, 如下图所示。
调度器会调用partition_sched_domains()来更新自己的scehd_domains,调度域发生作用的地方是在时钟中断的时候会触发SCHED_SOFTIRQ对任务做迁移,或者p->sched_class->select_task_rq,会在选择运行 CPU 时进行抉择,看一下 CFS 的实现的select_task_rq的简化流程
// 向上遍历更高层次的domain,如果发现同属一个domain // 就是affine目标 for_each_domain(cpu, tmp) { /* * If both cpu and prev_cpu are part of this domain, * cpu is a valid SD_WAKE_AFFINE target. */ if (want_affine && (tmp->flags & SD_WAKE_AFFINE) && cpumask_test_cpu(prev_cpu, sched_domain_span(tmp))) { affine_sd = tmp; break; }
if (tmp->flags & sd_flag) sd = tmp; } // 如果上面的条件满足,从prev_cpu中选出一个idle的new_cpu来运行. if (affine_sd) { if (cpu != prev_cpu && wake_affine(affine_sd, p, sync)) prev_cpu = cpu; // 在同一个级别的sched domain向下找到一个idle的CPU. new_cpu = select_idle_sibling(p, prev_cpu); // 快速路径,有idle的CPU就不用负载均衡了. goto unlock; } // 遍历层级 while (sd) { // 找到负载最小的CPU group = find_idlest_group(sd, p, cpu, load_idx); if (!group) { sd = sd->child; continue; }
new_cpu = find_idlest_cpu(group, p, cpu); /* 如果最闲置的CPU没有变的话,或者没有找到的话,就向下遍历. if (new_cpu == -1 || new_cpu == cpu) { /* Now try balancing at a lower domain level of cpu */ sd = sd->child; continue; }
/* Now try balancing at a lower domain level of new_cpu */ cpu = new_cpu; weight = sd->span_weight; sd = NULL; // 如果选出的节点weight比其他节点都大的话. // 再向下一个层级遍历. for_each_domain(cpu, tmp) { if (weight <= tmp->span_weight) break; if (tmp->flags & sd_flag) sd = tmp; } /* while loop will break here if sd == NULL */ }
负载均衡的对象有个例外。
CPUs in “cpuset.isolcpus” were excluded from load balancing by the isolcpus= kernel boot option, and will never be load balanced regardless of the value of “cpuset.sched_load_balance” in any cpuset.
/* * The core object. the cgroup that wishes to account for some * resource may include this counter into its structures and use * the helpers described beyond */
struct res_counter { /* * the current resource consumption level */ unsigned long long usage; /* * the maximal value of the usage from the counter creation */ unsigned long long max_usage; /* * the limit that usage cannot exceed */ unsigned long long limit; /* * the limit that usage can be exceed */ unsigned long long soft_limit; /* * the number of unsuccessful attempts to consume the resource */ unsigned long long failcnt; /* * the lock to protect all of the above. * the routines below consider this to be IRQ-safe */ spinlock_t lock; /* * Parent counter, used for hierarchial resource accounting */ struct res_counter *parent; };
获取方式是通过该结构相关的封装接口提供的,比如mem_cgroup_usage就是通过res_counter_red_u64来获取对应的res_counter的RES_USAGE对应的值的,也就是unsigned long long usage这个成员。(如果不是root,还会递归获取rss和page cache的合。
static inline u64 mem_cgroup_usage(struct mem_cgroup *memcg, bool swap) { u64 val; if (!mem_cgroup_is_root(memcg)) { if (!swap) return res_counter_read_u64(&memcg->res, RES_USAGE); else return res_counter_read_u64(&memcg->memsw, RES_USAGE); } /* * Transparent hugepages are still accounted for in MEM_CGROUP_STAT_RSS * as well as in MEM_CGROUP_STAT_RSS_HUGE. */ // 如果是root就把所有的内存使用量都算进来. val = mem_cgroup_recursive_stat(memcg, MEM_CGROUP_STAT_CACHE); val += mem_cgroup_recursive_stat(memcg, MEM_CGROUP_STAT_RSS); if (swap) val += mem_cgroup_recursive_stat(memcg, MEM_CGROUP_STAT_SWAP); return val << PAGE_SHIFT; }
static int __do_fault(struct mm_struct *mm, struct vm_area_struct *vma, unsigned long address, pmd_t *pmd, pgoff_t pgoff, unsigned int flags, pte_t orig_pte) { pte_t *page_table; spinlock_t *ptl; struct page *page; struct page *cow_page; pte_t entry; int anon = 0; struct page *dirty_page = NULL; struct vm_fault vmf; int ret; int page_mkwrite = 0;
/* * If we do COW later, allocate page befor taking lock_page() * on the file cache page. This will reduce lock holding time. */ if ((flags & FAULT_FLAG_WRITE) && !(vma->vm_flags & VM_SHARED)) {
if (unlikely(anon_vma_prepare(vma))) return VM_FAULT_OOM;
/* 分配内存并且映射到内存区间 */ cow_page = alloc_page_vma(GFP_HIGHUSER_MOVABLE, vma, address); if (!cow_page) return VM_FAULT_OOM; /* 进行统计 */ if (mem_cgroup_newpage_charge(cow_page, mm, GFP_KERNEL)) { page_cache_release(cow_page); return VM_FAULT_OOM; } } else cow_page = NULL;
static unsigned long mem_cgroup_reclaim(struct mem_cgroup *memcg, gfp_t gfp_mask, unsigned long flags) { unsigned long total = 0; bool noswap = false; int loop;
if (flags & MEM_CGROUP_RECLAIM_NOSWAP) noswap = true; if (!(flags & MEM_CGROUP_RECLAIM_SHRINK) && memcg->memsw_is_minimum) noswap = true;
for (loop = 0; loop < MEM_CGROUP_MAX_RECLAIM_LOOPS; loop++) { if (loop) drain_all_stock_async(memcg); total += try_to_free_mem_cgroup_pages(memcg, gfp_mask, noswap); /* * Allow limit shrinkers, which are triggered directly * by userspace, to catch signals and stop reclaim * after minimal progress, regardless of the margin. */ if (total && (flags & MEM_CGROUP_RECLAIM_SHRINK)) break; if (mem_cgroup_margin(memcg)) break; /* * If nothing was reclaimed after two attempts, there * may be no reclaimable pages in this hierarchy. */ if (loop && !total) break; } return total; }
why ‘memory+swap’ rather than swap. The global LRU(kswapd) can swap out arbitrary pages. Swap-out means to move account from memory to swap…there is no change in usage of memory+swap. In other words, when we want to limit the usage of swap without affecting global LRU, memory+swap limit is better than just limiting swap from an OS point of view.[12]
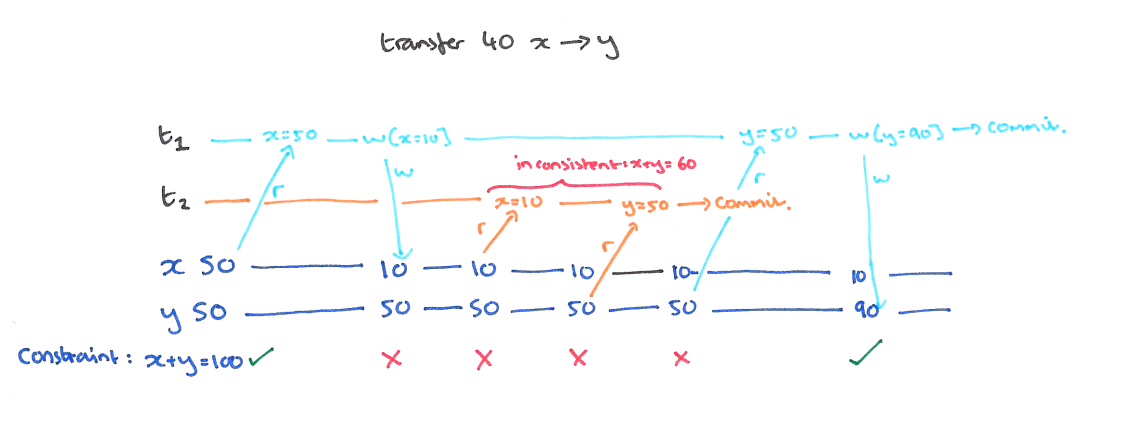
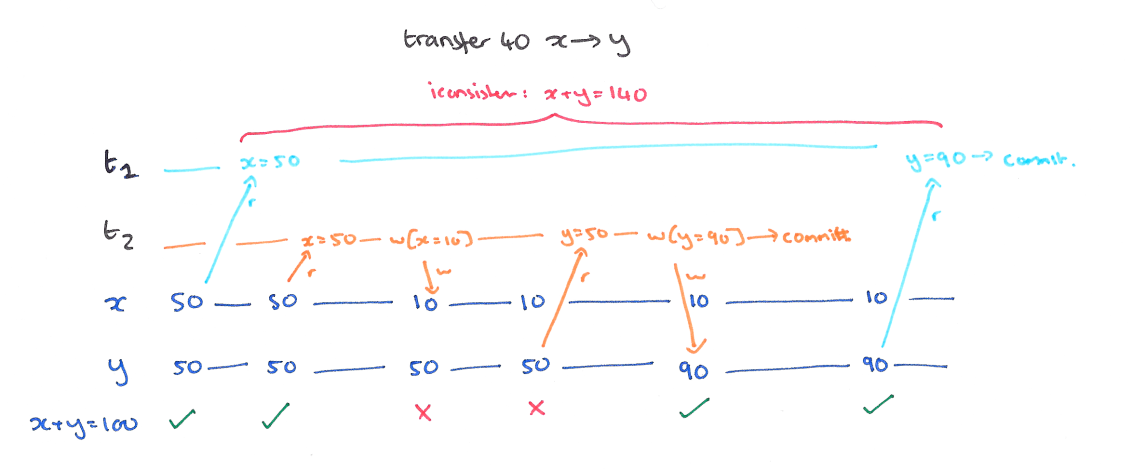
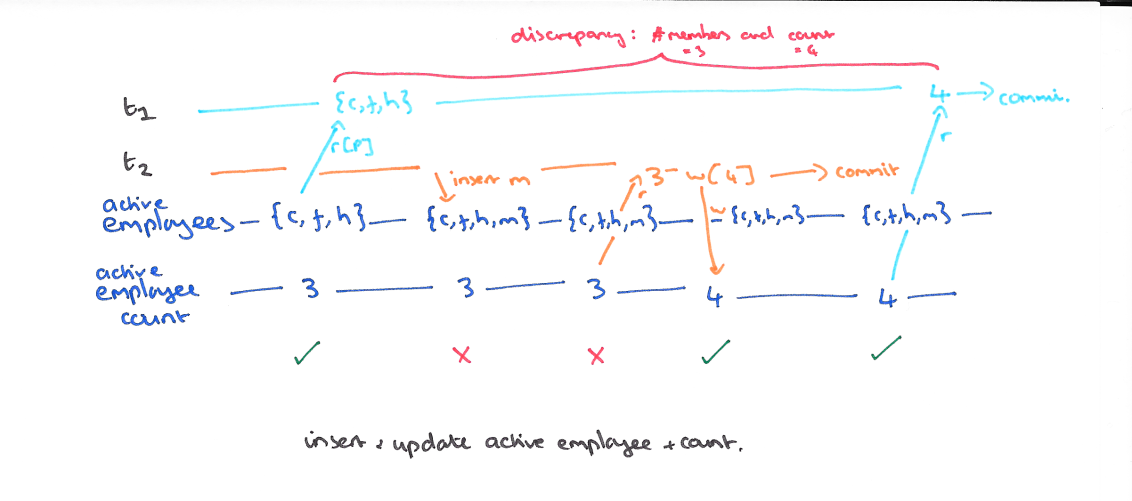
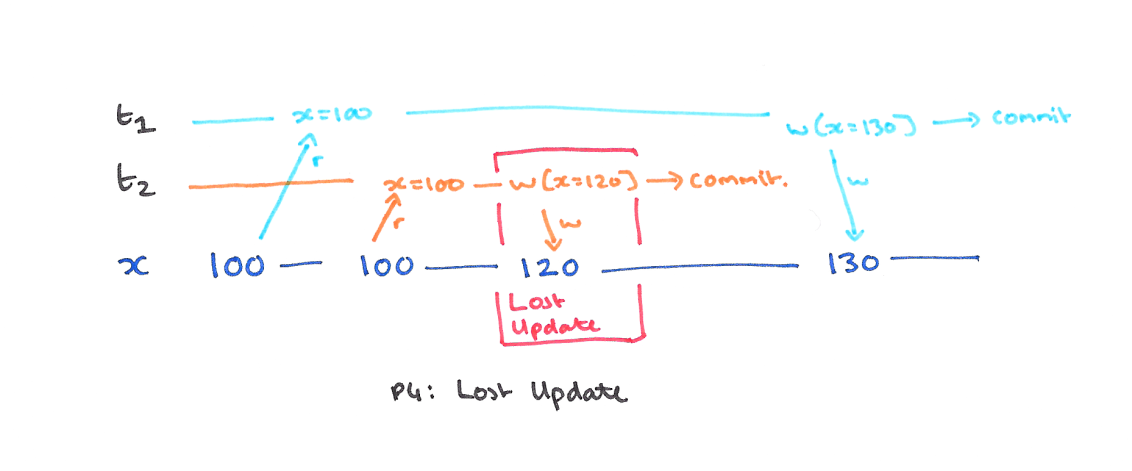
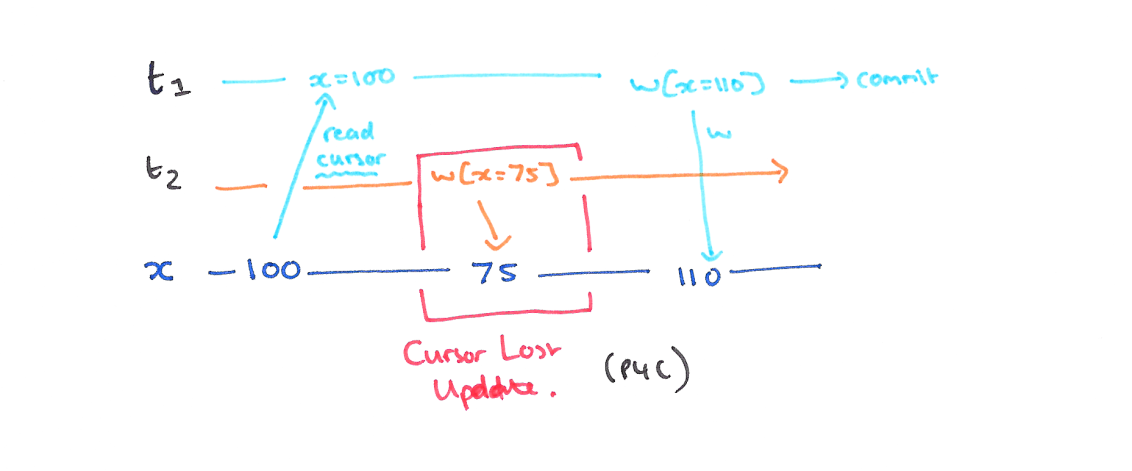
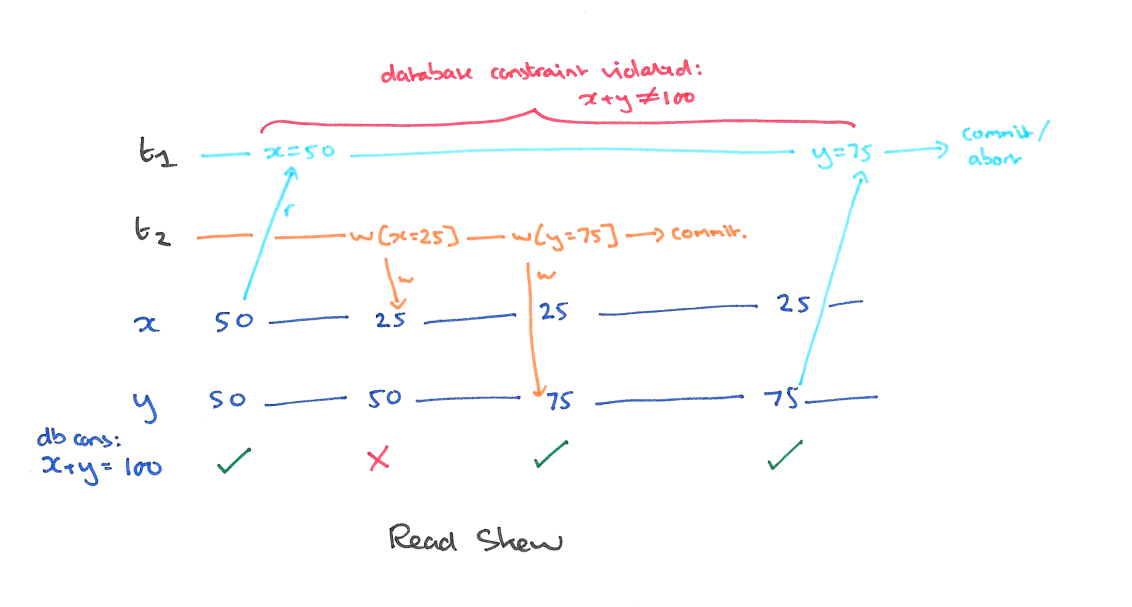
使用快照隔离 (Snapshot Isolation),快照隔离是基于 MVCC 的。当一个 T 事务开始的时候,T 会获得一个抽象的时间戳(版本),当对数据 X 进行读取的时候,并不是直接看到最新写入的数据而是在 T 开始前的所有执行中的事务中最后一个对 X 标记的版本(如果 T 修改过 X,那么看到的是自己的版本)。也就是说 T 是基于当前的数据库的一个镜像进行操作的,有点类似于 Copy And Swap,而 T 开始执行是获得的版本就是这个快照的凭证。这样能保证所有的读都是基于一个一致的状态获取的。
SI 解决冲突的方法一般是 “First-Commiter-Wins” 也就是说,如果两个并发的事务修改了同一个数据,先写的事务会成功,而后写的事务会发现版本和原本的不一致而退出事务。
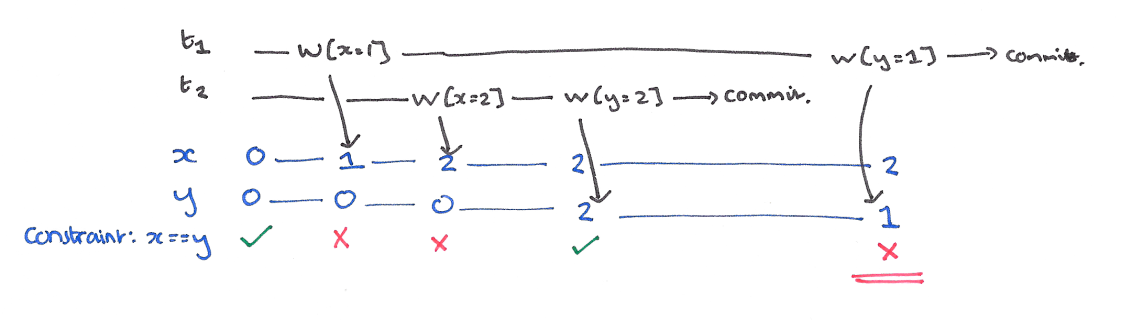
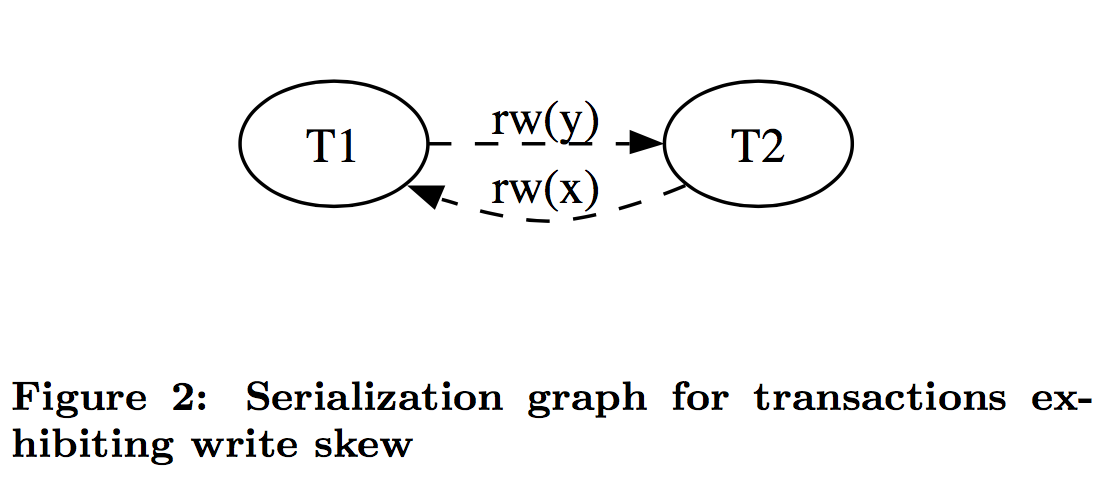
以我们的例子来说的话,T1 的 y 只会读到自己开始时候的版本,也就是 50,而不是 75,这样读偏就解决了。但是快照隔离还是不能解决另一个问题,就是写偏。这是我们要面临的新问题。
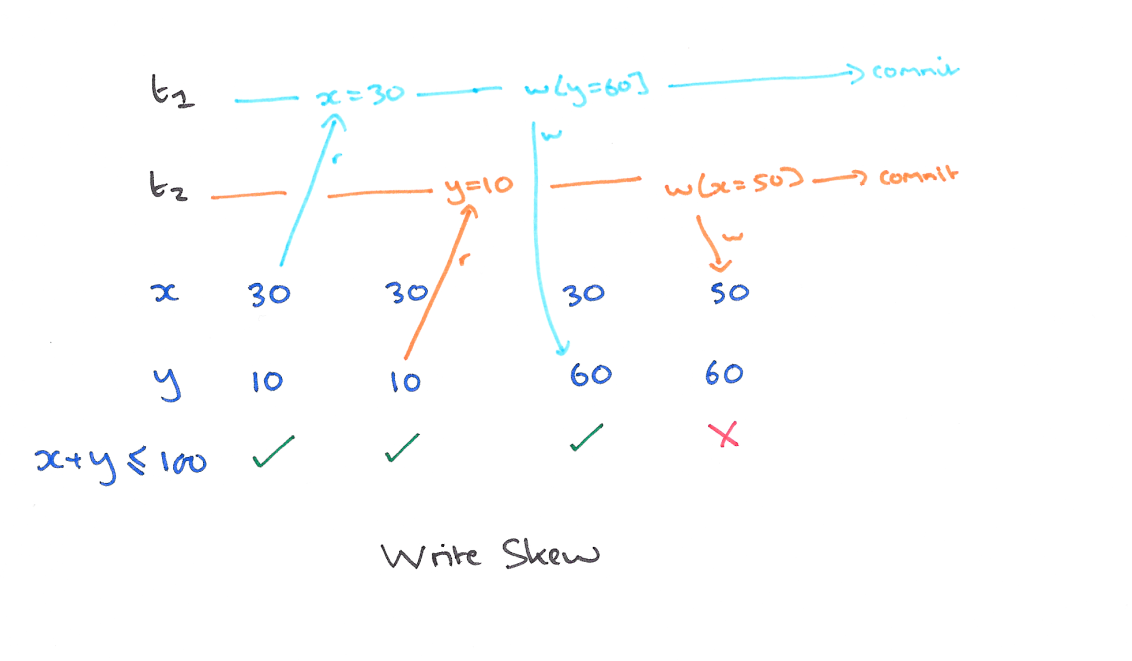
A5B write skew (写偏)
现象
这个和读偏类似,只不过,不一致在了整个系统上。T1 写锁有 y 的新版本,T2 写锁有 x 的新版本,他们没有写冲突,导致最后系统不一致,x+y 的钱变多了。
// Since coalesced heartbeats adds latency to heartbeat messages, it is // beneficial to have it run on a faster cycle than once per tick, so that // the delay does not impact latency-sensitive features such as quiescence. func (s *Store) startCoalescedHeartbeatsLoop() { s.stopper.RunWorker(func() { ticker := time.NewTicker(s.cfg.CoalescedHeartbeatsInterval) defer func() { ticker.Stop() }()
for { select { case <-ticker.C: s.sendQueuedHeartbeats() case <-s.stopper.ShouldStop(): return } } }) }
在 Store 这个层面是对每个 Replica (一个 raft group 的成员) 是有感知的,但是每个 raft group 是独立的,只是在发送是会检查对方节点是否和现在的 raft group 有交集, 从而尝试合并消息的发送,你可以理解为在节点之间的消息通道上对不同 raft group 之间多路复用。 这就是 MultiRaft 对多个 raft group 的网络吞吐做的一个优化,代价是可能造成消息的延迟,因为毕竟是被缓存到队列里了。